Architecture
|
This content is for the classic Neo4j Aura console. Use the version selector on the left to see the new console documentation. |
AuraDS makes it easy to run graph algorithms on Neo4j by integrating two main components:
-
Neo4j Database, where graph data are loaded and stored, and Cypher queries and all database operations (for example user management, query termination, etc.) are executed;
-
Graph Data Science, a software component installed in the Neo4j Database, whose main purpose is to run graph algorithms on in-memory projections of Neo4j Database data.
Neo4j Graph Data Science concepts
The Neo4j Graph Data Science (GDS) library includes procedures to project and manage graphs, run algorithms, and train machine learning models.
The graph catalog is used to store and manage projected graphs via GDS procedures.
GDS contains many graph algorithms, invoked as Cypher procedures and run on projected graphs.
GDS algorithms are broken down into three tiers of maturity:
-
Alpha: experimental algorithms that may be changed or removed at any time. Algorithms in this tier are prefixed with
gds.alpha.<algorithm>. -
Beta: algorithms promoted from the Alpha tier to candidates for the Production tier. Algorithms in this tier are prefixed with
gds.beta.<algorithm>. -
Production: algorithms that have been rigorously tested for stability and scalability. Algorithms in this tier are prefixed with
gds.<algorithm>.
Some machine learning algorithms (for example Node Classification and GraphSage) need to use trained models in their computation. The model catalog is used to store and manage named trained models.
The pipeline catalog is used to manage machine learning pipelines. A pipeline groups together all the stages of a supported machine learning task (for example Node classification), from graph feature extraction to model training, in a single end-to-end workflow.
Graph data flow
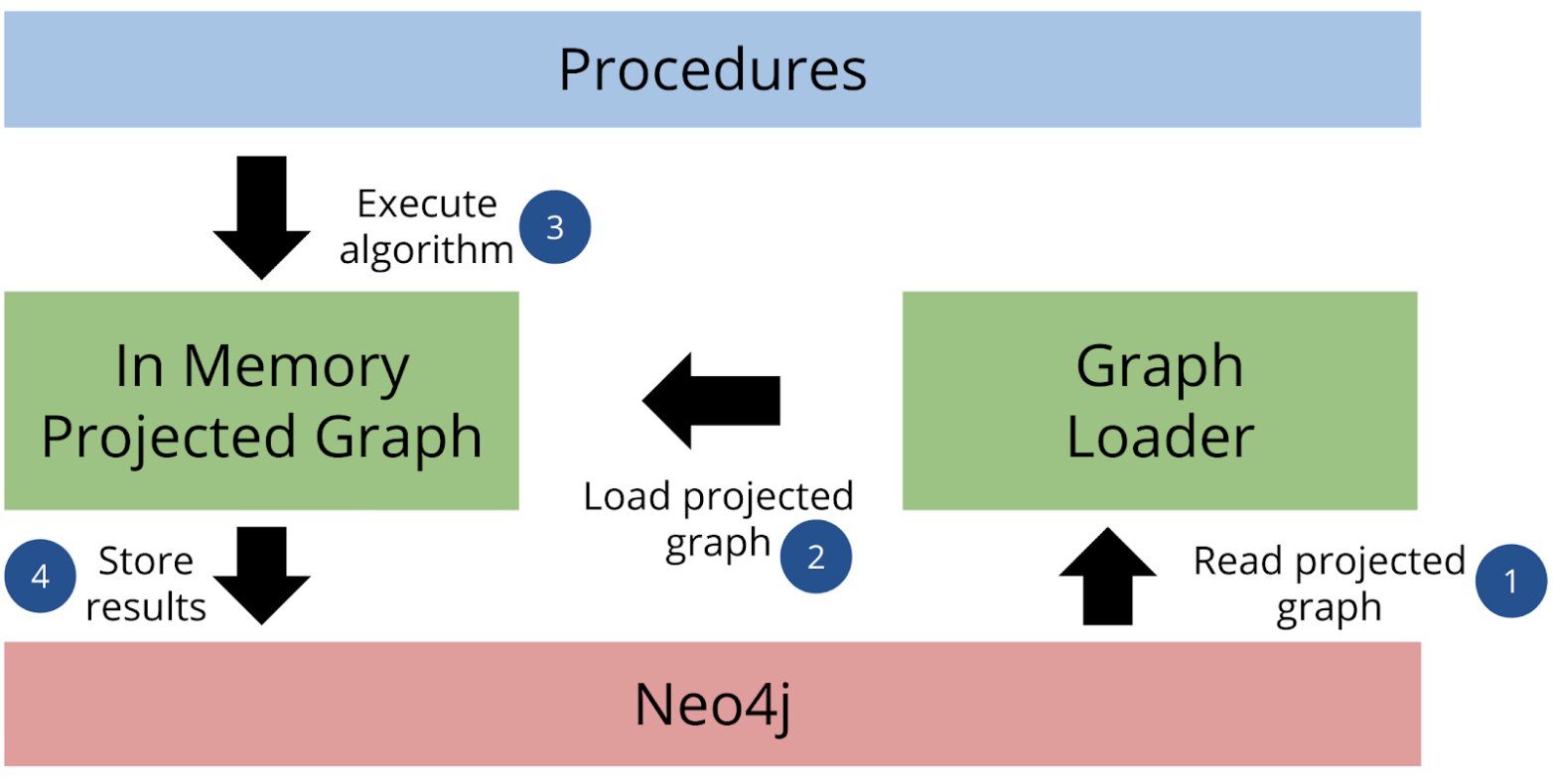
Since GDS algorithms can only run in memory, the typical data flow involves:
-
Reading the graph data from Neo4j Database
-
Loading (projecting) the data into an in-memory graph
-
Running an algorithm on a projected graph
-
Writing the results back to Neo4j Database (if the algorithm runs in write mode)