Designing the Initial Graph Data Model
About this module
At the end of this module, you will be able to:
-
Describe the domain for a model.
-
Define the questions for the domain.
-
Identify entities from the questions for the domain.
-
Use the Arrows Tool to model the domain.
-
Identify the connections between entities.
-
Describe how to test the initial model.
Designing the initial data model
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Designing the initial model is a multi-step process. We find it is extremely important to be disciplined about this. If you do, you tend to get to a first model faster, that model better suits your documented needs, and that model is usually simple to understand. It will almost certainly not be perfect, and will need to change in response to shifting needs and a deepening understanding of the domain, use case, and capabilities of Neo4j. But recall that modifying a data remodel in Neo4j is relatively inexpensive. This fact reduces the pain and risk of taking a narrow approach to the first model.
Later in this training, you will learn how to identify weaknesses in a model, and how to improve the existing design.
| Every organization has their own standards for how requirements are documented. You will not be learning how to document requirements, but rather focus on the model itself. |
Step 1: Understanding the domain
-
Describe the application in detail.
-
Identify the stakeholders and developers of the application.
-
Identify the users of the application (people, systems).
-
Enumerate the use cases that are agreed upon by all stakeholders where users are part of the use case.
| No knowledge of the underlying implementation is required! |
Example domain: Bill Of Materials (BOM)
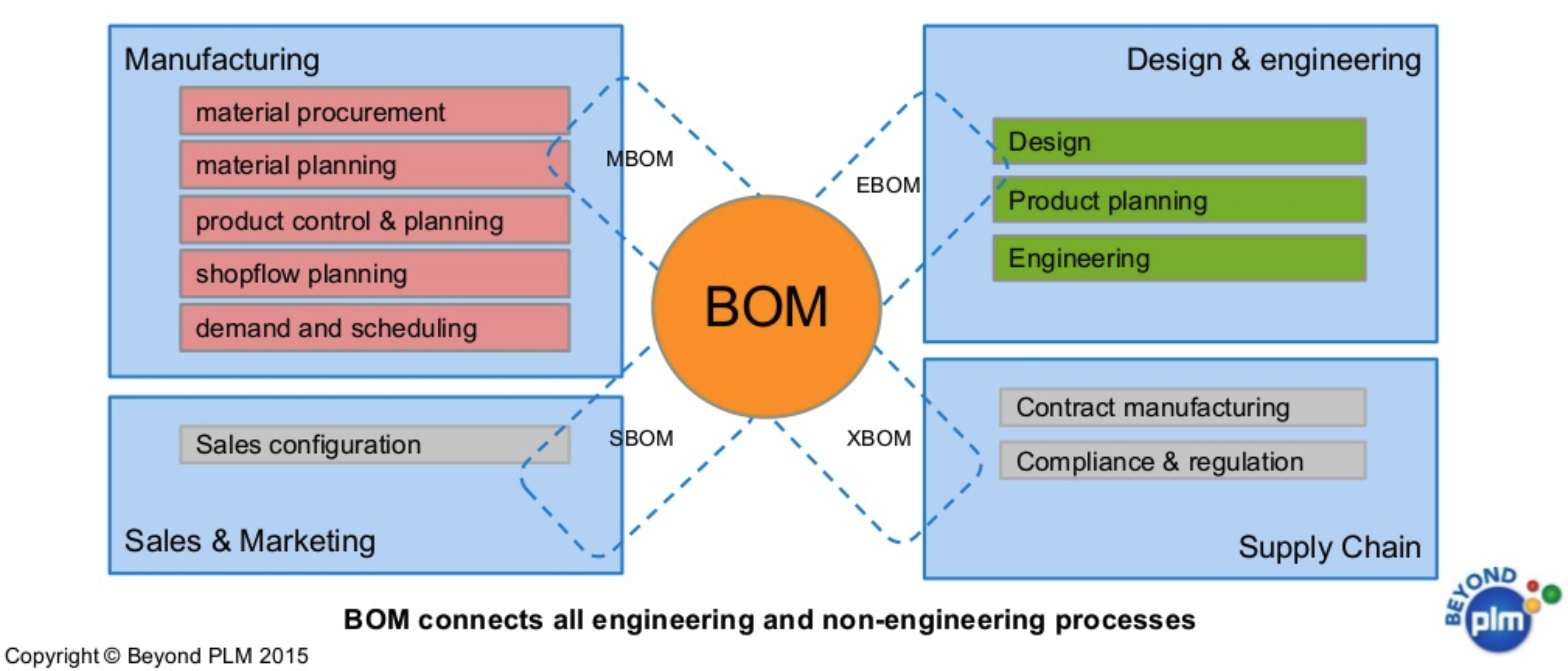
From Wikipedia:
A bill of materials or product structure (sometimes bill of material, BOM or associated list) is a list of the raw materials, sub-assemblies, intermediate assemblies, sub-components, parts, and the quantities of each needed to manufacture an end product. A BOM may be used for communication between manufacturing partners or confined to a single manufacturing plant. A bill of materials is often tied to a production order whose issuance may generate reservations for components in the bill of materials that are in stock and requisitions for components that are not in stock.
A BOM can define products as they are designed (engineering bill of materials), as they are ordered (sales bill of materials), as they are built (manufacturing bill of materials), or as they are maintained (service bill of materials). The different types of BOMs depend on the business need and use for which they are intended. In process industries, the BOM is also known as the formula, recipe, or ingredients list. The phrase "bill of material" (or "BOM") is frequently used by engineers as an adjective to refer not to the literal bill, but to the current production configuration of a product, to distinguish it from modified or improved versions under study or in test.
Example BOM use cases
-
System produces list of parts to make a product.
-
System produces list of products that can be made with available parts.
-
System produces list of parts that are made with other parts.
-
User picks parts to make a product.
-
System creates a price for a product based upon the part prices.
-
System creates list of parts that need to be ordered.
| A product or part can be made of multiple parts of the same type. Some parts are made from other parts (sub-assembly). |
This is a very small fraction of the use cases for the BOM application.
Step 2: Create high-level sample data
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Sample data need not be expansive, detailed, or even of particularly high quality. It simply needs to represent the broad shape of the information you would expect to find in the real data.
Sample data can either be completely made up, or can be a sample pulled from a real dataset. If you’ve done the work to properly understand the domain, it will not strongly matter either way.
BOM high-level sample data
| Products | Parts | Assemblies | Notes |
|---|---|---|---|
Wood table 40" |
Glass top 40" |
Leg assembly |
Has 4 legs |
Deluxe wood table 40" |
Wood top 40" |
Leg assembly |
Has 4 legs |
Wood table 60" |
Glass top 60" |
Leg assembly |
Has 6 legs, table brace |
Deluxe wood table 60" |
Wood top 60" |
Leg assembly |
Has 6 legs, table brace |
Leg |
|||
Leg foot |
|||
M20 bolt |
|||
M20 nut |
|||
Leg plate |
Uses 2 bolts/nuts per leg |
||
Table brace |
If you want your modeling process to be constructive, you must have enough data points for your domain so that you can understand the data that will be retrieved when the questions are asked.
The data is typically the "things" described in the use cases. You don’t include "system" or "user" as part of the data.
Step 3: Define specific questions for the application
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Step 4 : Identify entities
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
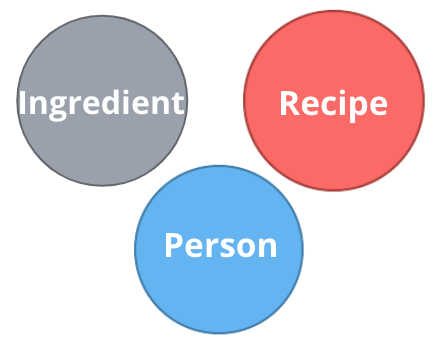
Identify entities from the questions
Entities are the nouns in your application questions:
-
What ingredients are used in a recipe?
-
Who is married to this person?
-
The generic nouns will often become labels in your model.
-
Proper nouns will often become values for properties.
-
Use domain knowledge to decide if entities need to be further grouped or differentiated.
-
In Neo4j Enterprise Edition, there is no limit to the number entities (nodes) in the graph. (Community Edition has a limit of 34 billion)
As an example of using domain knowledge, you might happen to know that the distinction between wet and dry ingredients is important in your use case, or that vegetarian and vegan are important subgroups of a recipe. These may not appear clearly in the specific application questions.
Define properties
Properties serve one of two purposes:
-
Unique identification.
-
Answering one of the application questions.
Otherwise, they are merely "decoration".
Properties are used in a Cypher query for:
-
Anchoring (where to begin the query).
-
Traversing the graph (navigation).
-
Returning data from the query.
Identifiers serve two purposes:
-
They can be used to power unique constraints or
MERGEoperations. -
They can be useful to help a human user understand what they are looking at in query results.
There are subtly different best practices for properties serving each of those functions, which you will learn about later. For now, we simply group them all into this one generic bucket of usefulness.
Decorators are usually left out of the initial model. If they are not being used to answer questions, they are a waste of storage, and their presence can distract users and developers from the information that is actually important. Remember that we endorse a narrow, focused approach to model design, based on the relative ease of modifying a graph data model.
However, it can be beneficial to include decorators when you move to production. Not because they will be used, but because, if all information is locally available to Neo4j, refactoring a model later may not require importing data from its original source.
Exercise 1: Identifying entities for the BOM application
Define the entities and properties from these questions:
-
What parts are needed to make Wood table 40"?
-
Do we have enough parts to make 100 Deluxe wood table 60"?
-
What products require a table brace?
-
How much will the parts cost to make product Wood table 60"?
Exercise 1 solution
Product
-
name
-
productId
Part
-
name
-
partNumber
-
price
Part, Assembly
-
name
-
partNumber
-
price
Assembly is the tricky one—it does not appear in the questions, and you must use domain knowledge to understand why it is needed.
Remember that your first model is never perfect, and that is OK because modifying the model in its early stages is relatively easy.
Exercise 2: Creating the BOM entity model in the Arrows tool
Use the entities you identified earlier for the BOM application and create them in the Arrows tool.
Make sure you include properties for the nodes and specify the types for the properties, rather than values.
| If you get stuck, the solution JSON files can be downloaded here: https://data.neo4j.com/v4.0-graph-data-modeling/GraphDataModeling-40-files-v2.zip |
Step 5: Identify connections between entities
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Identify connections between entities
Connections are the verbs in your application questions:
-
What ingredients are used in a recipe?

-
Who is married to this person?

At a glance, connections are straightforward things, but their micro- and macro-design are arguably the most critical factors in graph performance. Using “connections are verbs” is a fine shorthand to get started, but there are other important considerations that will be discussed later in this training.
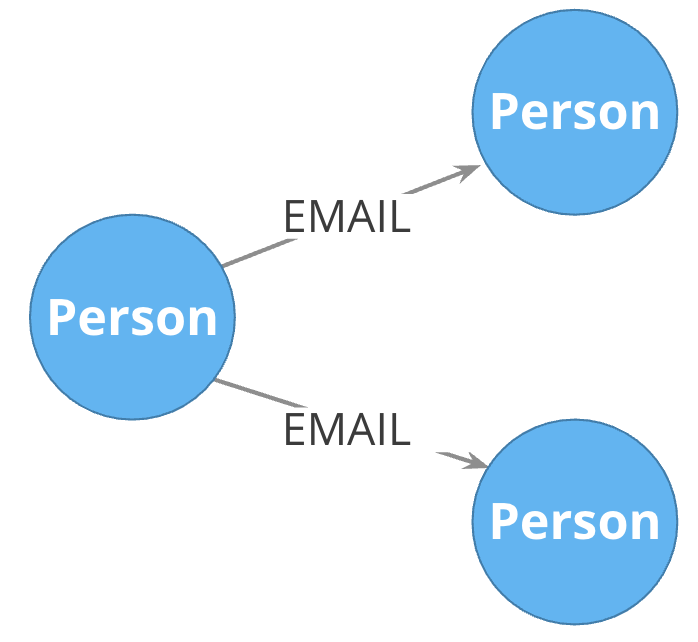
Naming relationships
-
Stakeholders must agree upon name (type for the relationship).
-
Avoid names that could be construed as nouns (for example email).
-
Neo4j has a limit of 16M relationship types in Enterprise Edition (64K in Community Edition).
Do not do this:
Instead do this:
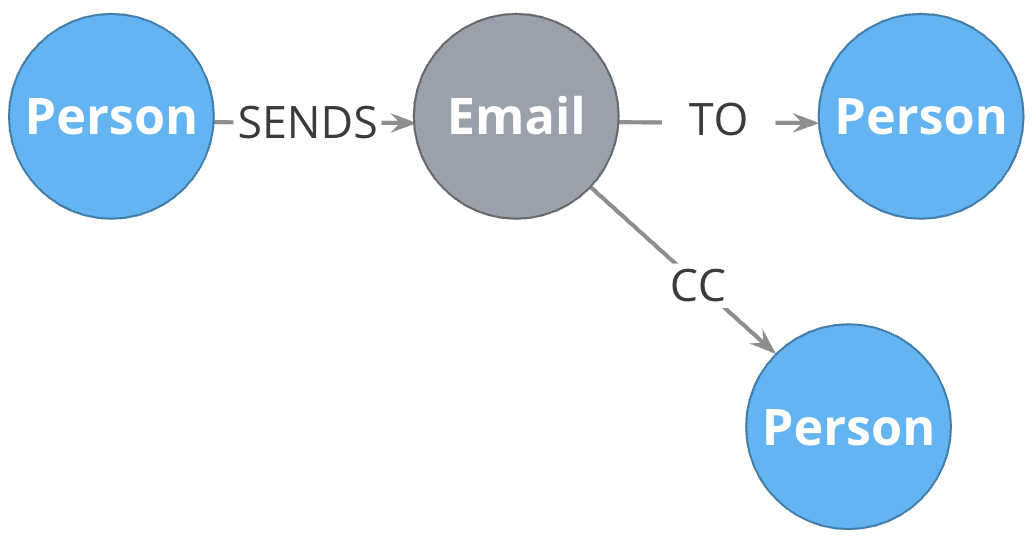
Choosing good names is vital. It needs to be something that is intuitive to stakeholders and developers alike, cannot be confused as an entity name, and is specific enough to make traversal efficient but general enough to make the Cypher easy to write. You will learn more about later in this training when you learn about the core principles of graph data modeling.
Direction and type
Direction and type are required in Neo4j.
Choose direction (and type) based on the expected questions:
-
What episode follows The Ark in Space? (NEXT)
-
What episode came before Genesis of the Daleks? (PREVIOUS)

These are episodes of the Dr. Who BBC series, season 12, aired in 1975.
A relationship can be modeled in either direction, with no effect on performance. Naturally, the type would have to differ. Here, we have chosen left-to-right relationships of the type NEXT. We could equally well have chosen right-to-left relationships of the type PREVIOUS. This has no effect on query performance, but the Cypher used for each variant will differ. Choose whichever variant makes the Cypher more intuitive for developers to write, based on your expectations for what people will ask.
How much fanout will a node have?
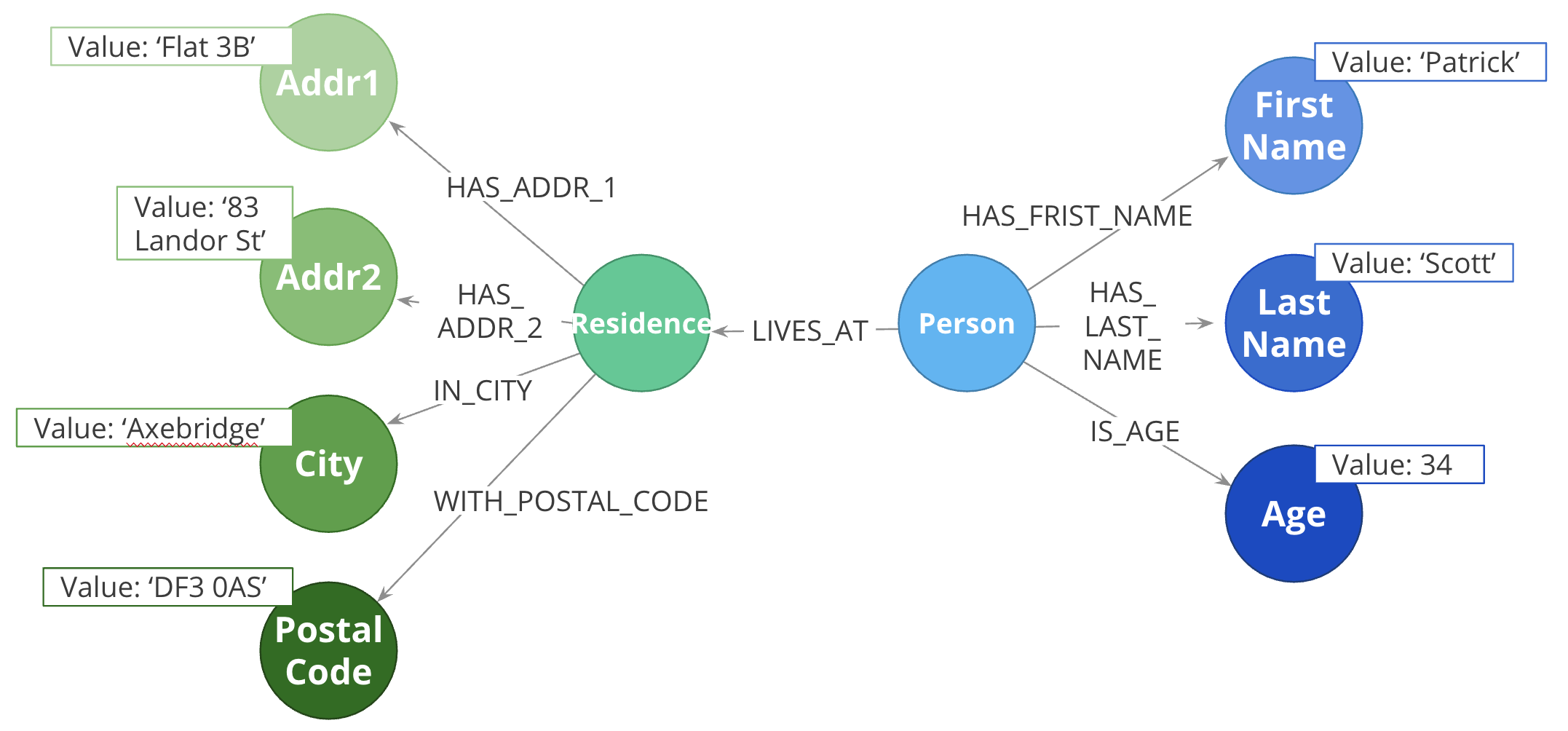
Here, we have entities (Person, Address) represented not as a single node, but as a network or linked nodes. This is an extreme example of fanout, and is almost certainly overkill for any real-life solution, but some amount of fanout can be very useful.
For example, splitting last names onto separate nodes helps answer the question, “Who has the last name Scott?” Similarly, having cities as separate nodes assists with the question, “Who lives in the same city as Patrick Scott?”
The main risk about fanout is that it can lead to very dense nodes, or supernodes. Supernodes need to be handled carefully.
Exercise 3: Adding relationships to the model
Exercise 3 instructions
Here are the questions we need to answer for our BOM application that you have already seen:
-
What parts are needed to make Wood table 40"?
-
Do we have enough parts to make 100 Deluxe wood table 60"?
-
What products require a table brace?
-
How much will the parts cost to make product Wood table 60"?
Using the Arrows tool add the relationships between the entities.
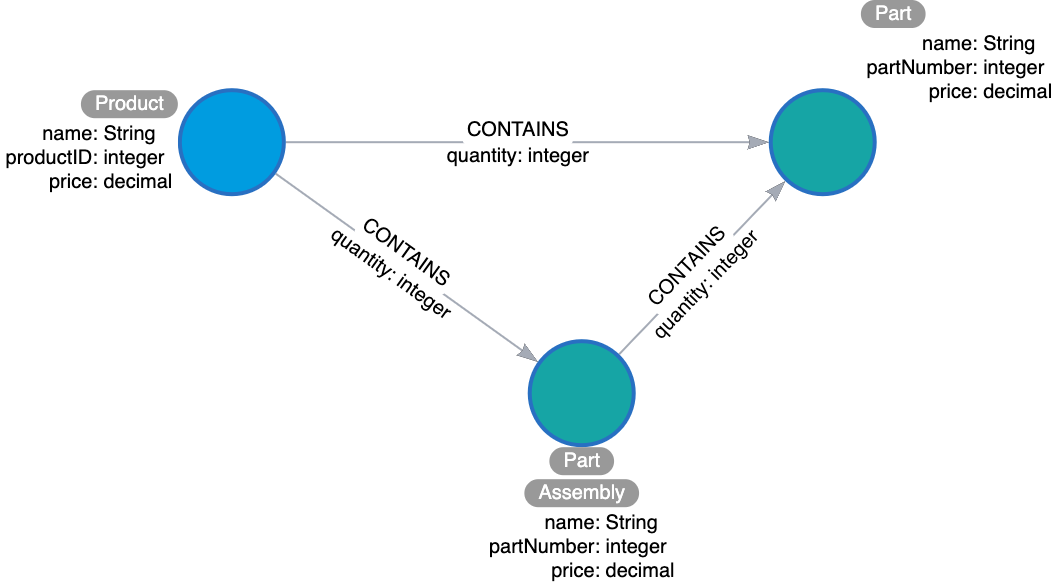
And here is the entity model:
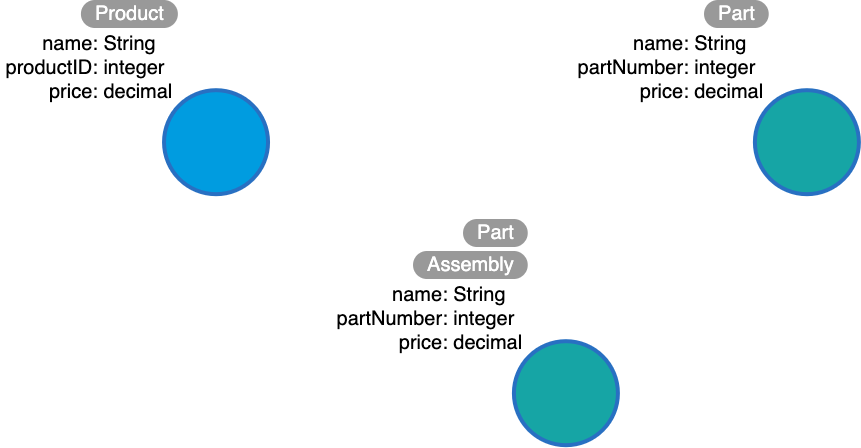
Focus on type and directions first. Then check for any qualifiers that will help answer questions. Must these qualifiers be types or properties? Why?
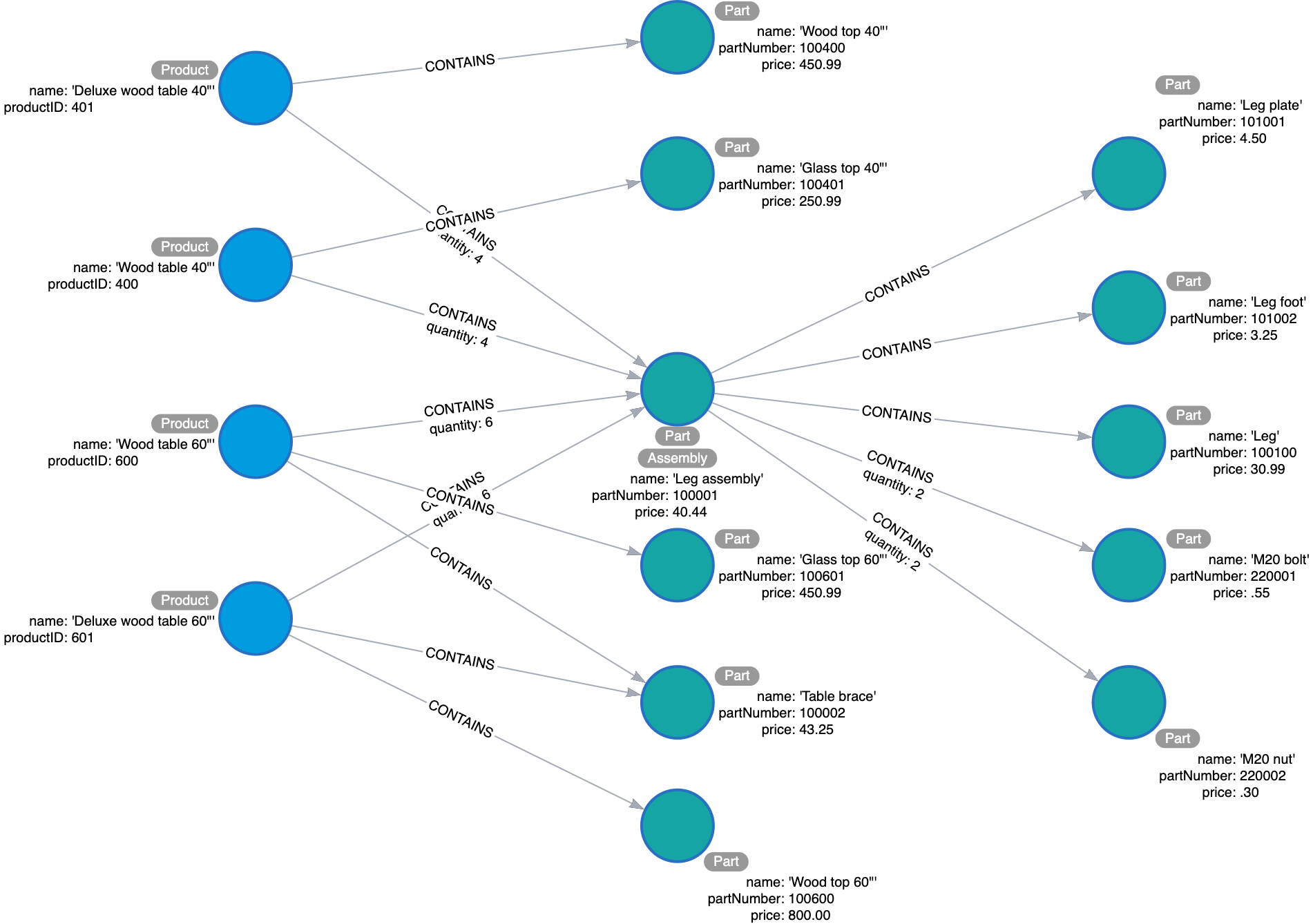
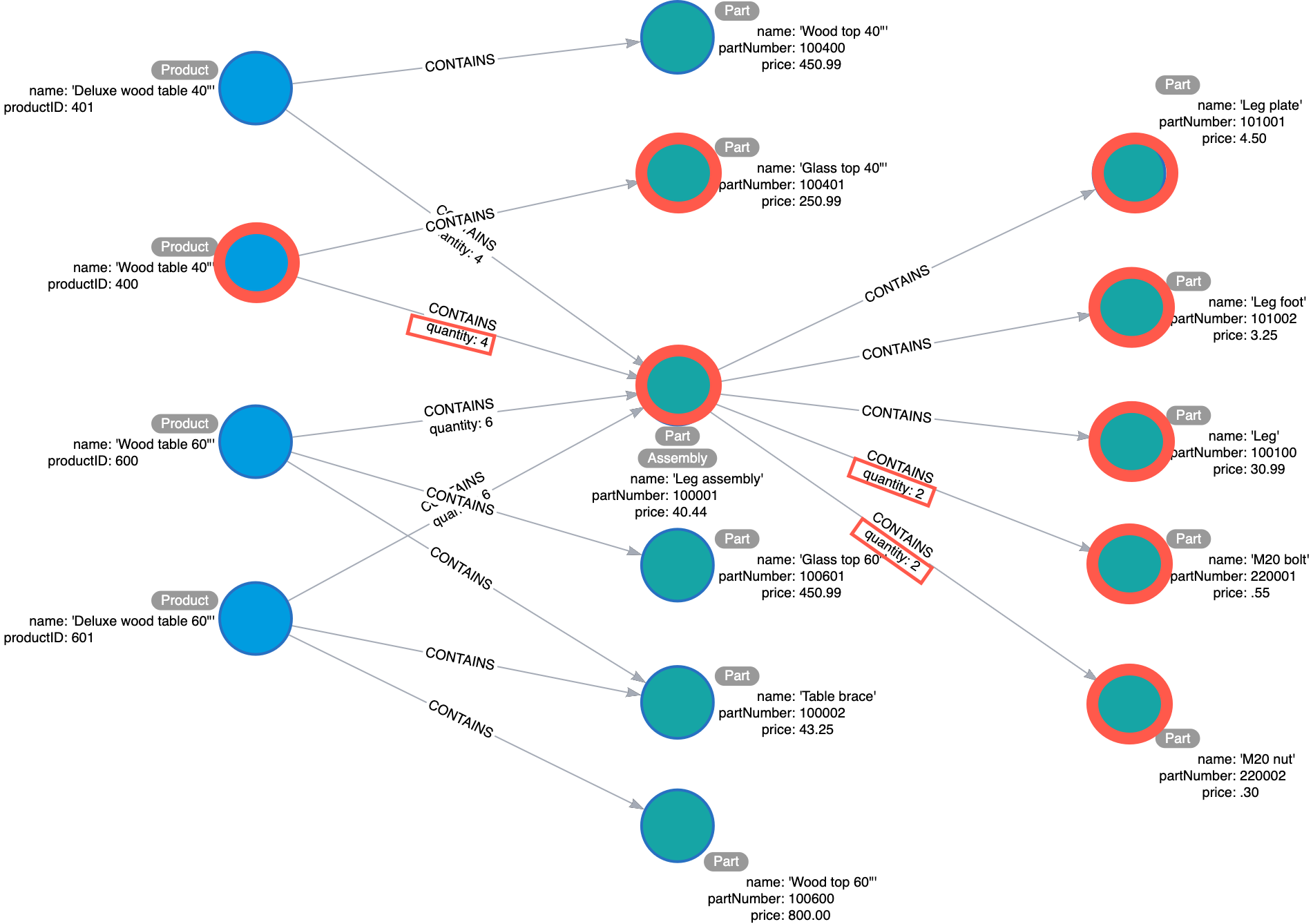
Example: Detailed sample data for the BOM application
Thus far, you have defined the entities and relationships for the BOM application. Just to fill in more details for the data model, here is more sample data that might be useful in furthering the design of the model. This particular sample data is useful, especially when discussing how well the design addresses the questions and how well the application can scale.
Here is what the sample data might look like in the UI of the Arrows tool:
Step 6: Test the questions against the model
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Testing the model - 1
What parts are needed to make Wood table 40"?
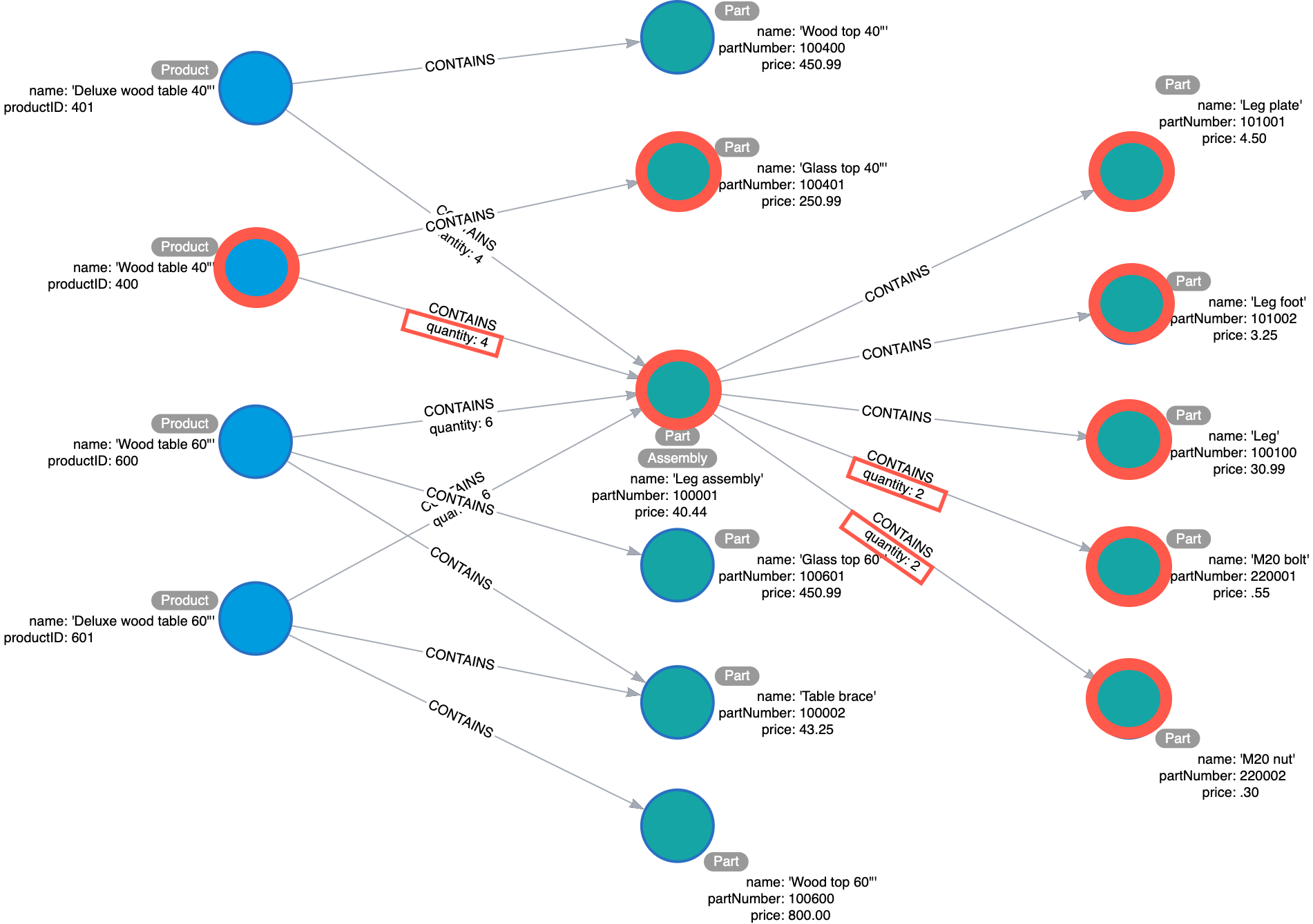
To answer the first question, we would anchor on the Wood table 40" node, and iteratively traverse all CONTAINS until we get all of the parts required to make the product. Multiply by the quantity property as you go.
Testing the model - 2
Do we have enough parts to make 100x Deluxe wood table 60"?
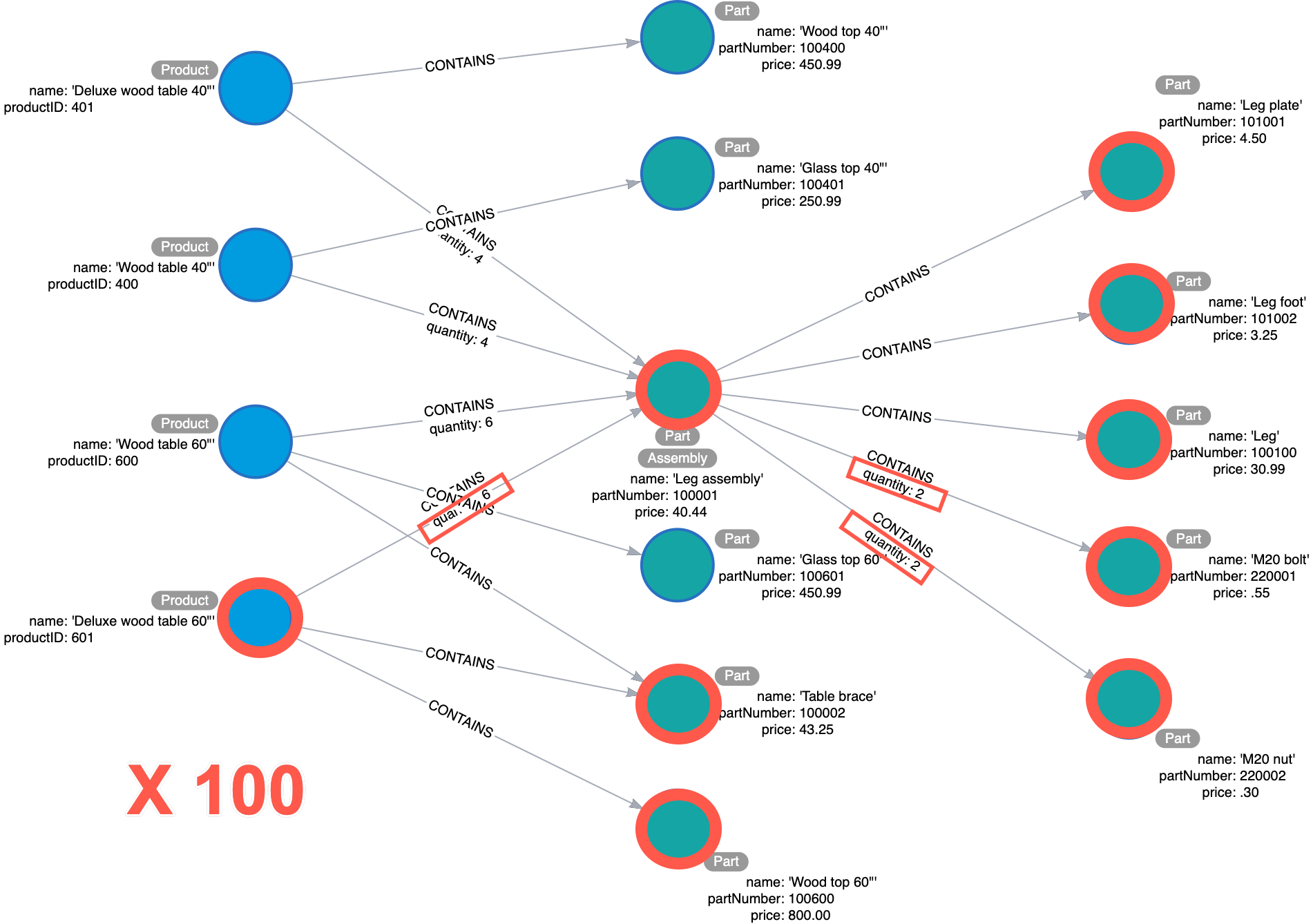
The application code that supports this question would need to come up with the inventory of parts needed to assemble the Deluxe wood table 60" and then multiply the parts list by 100. The application would then be integrated with an inventory application to truly answer the question.
Frequently, during the entity identification stage, the question of inventory comes up. Different people will advocate for or against it. Both cases work, but with different strengths and weaknesses.
If inventory is in the graph, the application architecture can be simpler—no need to integrate two data sources at query time. The downside is that stock numbers change frequently, and whenever they do, you will need to update the graph data. Neo4j is not specifically bad for frequent updates, but it offers no benefits in that area relative to other data management solutions.
Ideologically, we at Neo4j see graph databases as a problem-solving complement to the existing data management paradigm. If you were maintaining stock data somewhere else anyway, there is no inherent need to move it into Neo4j.
Testing the model - 3
What products require a table brace?
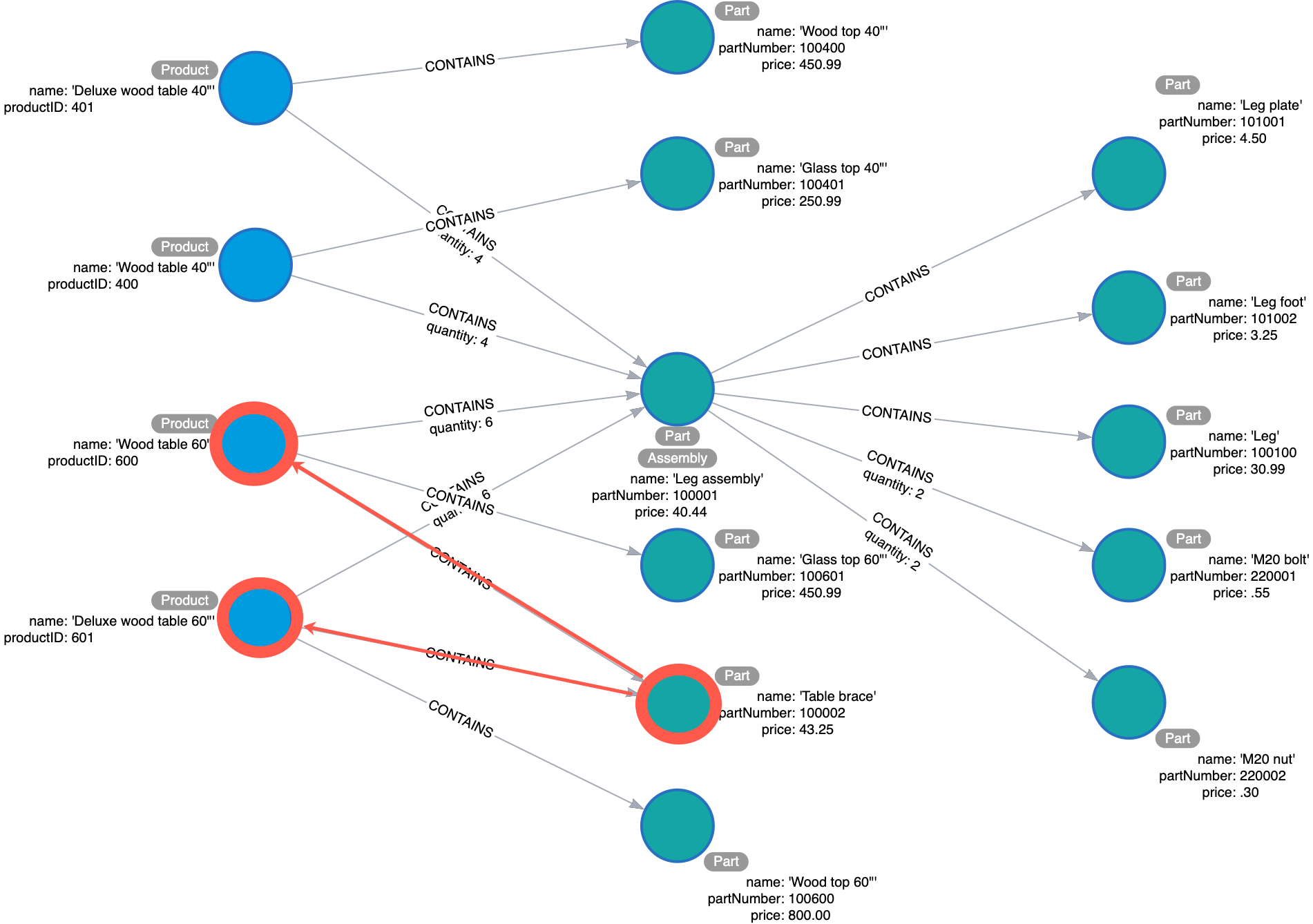
For this question, the application would anchor on the Part with the name table brace. Then it would traverse backwards along each CONTAINS to find the products that use it.
Testing the model - 4
How much will the parts cost to make Wood table 60"?
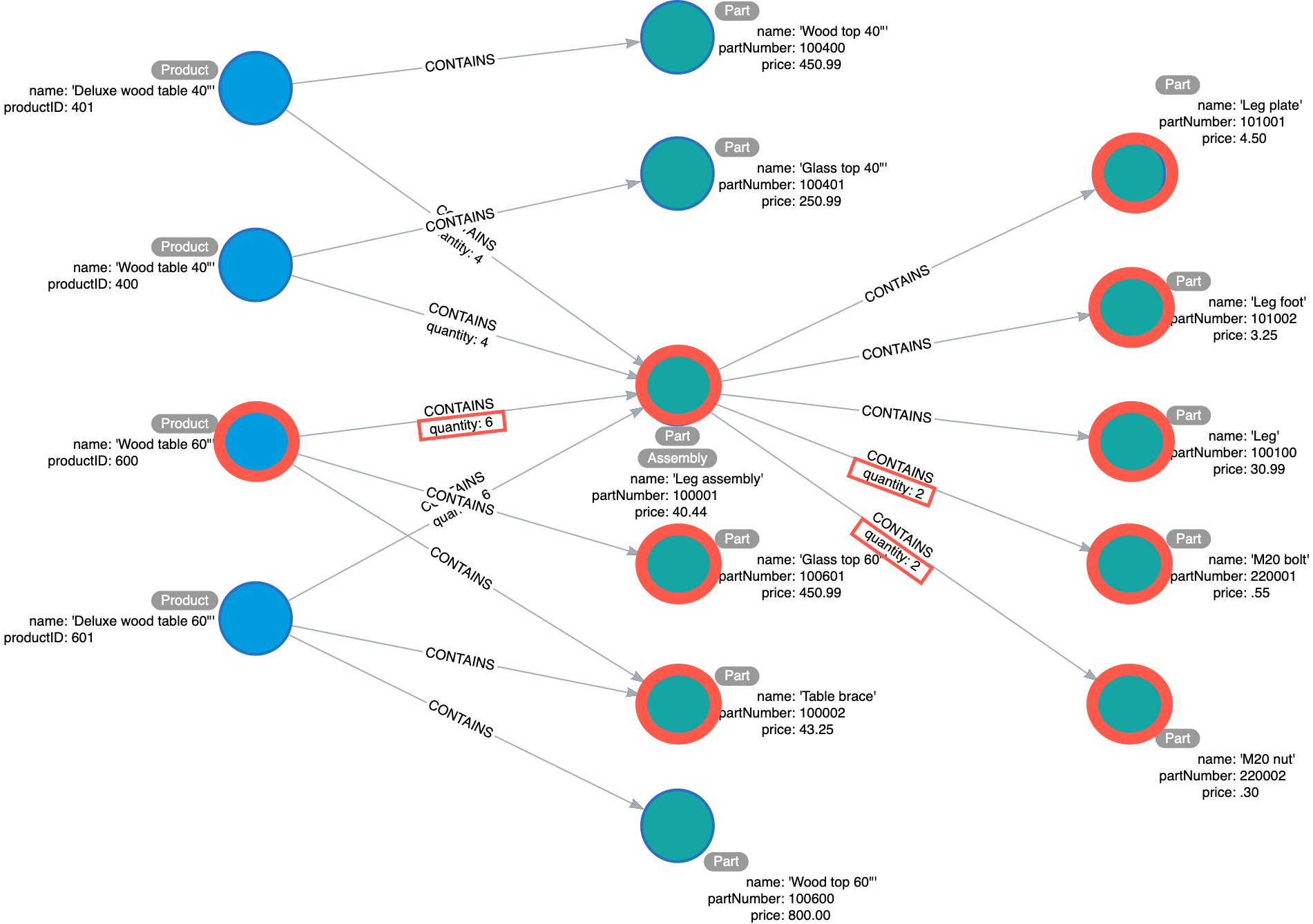
We anchor on the Wood table 60" product, and iteratively traverse each CONTAINS to the parts that the product contains. The application would simply add up the prices of the parts (multiplied by quantity when applicable) to come up with the total price.
During the entity identification stage, there is often a debate about whether Assembly nodes will contain a price, or if price will be kept only on the Part leaf nodes. That debate may even extend to whether price will be kept on Product nodes. Again, there is no “right” answer, only tradeoffs to be aware of.
If price is only on Parts, then this query needs to traverse further in order to find the answer. The benefit is that data updates are easier. If Assembly has a price, then that price is affected by any price changes of the sub-parts; ditto if price is on Products. The added complexity in data maintenance is generally undesirable. However, one big benefit of putting price at the Assembly level is that the Cypher for this question is simpler and more predictable. You can guarantee that Price is available exactly one hop away from the anchor node in all cases. This modeler felt that that benefit balanced out the added data maintenance expense.
Step 7: Test scalability
-
Understand the domain.
-
Create high-level sample data.
-
Define specific questions for the application.
-
Identify entities.
-
Identify connections between entities.
-
Test the questions against the model.
-
Test scalability.
Testing scalability
Here are some questions you may answer:
-
How many products?
-
How many parts?
-
How often are products added?
-
How often do prices change?
-
Are prices based upon time?
-
Is inventory part of the model?
Scalability questions must be asked by stakeholders and developers. Developers will have a better idea of the challenges with implementing the model as it scales so they are a key player in doing the scalability analysis. Stakeholders would have a better idea of how many products and parts, how often prices change etc.
Here, we are only looking for conceptual scalability concerns. We also do this at the level of individual query performance during the implementation of the graph data model.
Check your understanding
Question 1
What component of a graph data model is used to model the nouns of the questions for the domain?
Select the correct answer.
-
Relationship
-
Property
-
Entity
-
Data source
Summary
You can now:
-
Describe the domain for a model.
-
Define the questions for the domain.
-
Identify entities from the questions for the domain.
-
Use the Arrows Tool to model the domain.
-
Identify the connections between entities.
-
Describe how to test the initial model.
Need help? Ask in the Neo4j Community