Refactoring and Evolving a Model
About this module
At the end of this module, you will be able to:
-
Describe why you would refactor a graph data model.
-
Refactor a model to:
-
Eliminate duplicate data in nodes.
-
Use node labels rather than properties.
-
Extract property values to create nodes.
-
What is refactoring?
Refactoring is the process of changing the data structure without altering its semantic meaning.
-
Most of the time, refactoring simply involves moving data from one structure to another within the graph.
-
In some cases, refactoring involves adding more data from other sources.
The most common type of refactoring of a graph is to use a property value to restructure the graph. That is, a property value is used to create a label, a node, or a relationship.
Review: Hierarchy of Accessibility
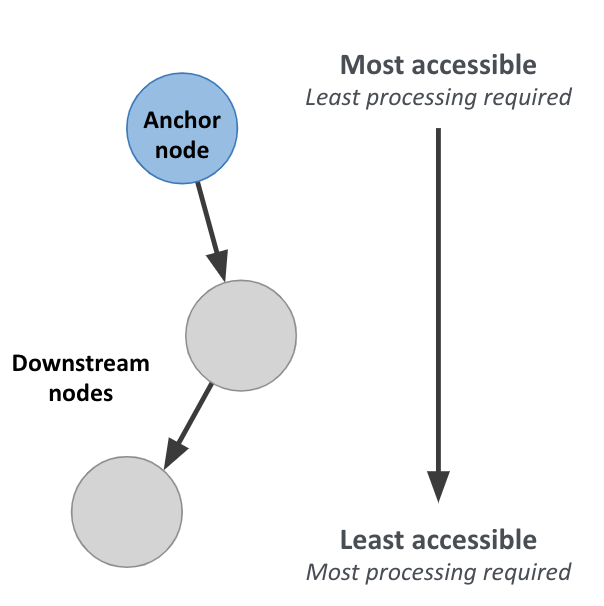
For each data object, how much work must Neo4j do to evaluate if this is a “good” path or a “bad” one?
-
Anchor node label, indexed anchor node properties
-
Relationship types
-
Non-indexed anchor node properties
-
Downstream node labels
-
Relationship properties, downstream node properties
Recall the hierarchy of accessibility. In general, refactoring involves moving data around this hierarchy, in order to better answer a question.
Why refactor?
Data models can be optimized for one of four things:
-
Query performance
-
Model simplicity & intuitiveness
-
Query simplicity (i.e., simpler Cypher strings)
-
Easy data updates
| Improving behavior in one of these areas frequently involves sacrifices in others. |
Another important reason to refactor is to accommodate new application questions in the same model.
Goal: Eliminate duplicate data in properties
There may be data that is duplicated in many nodes in your graph. In this example the type of currency is a property of a node.
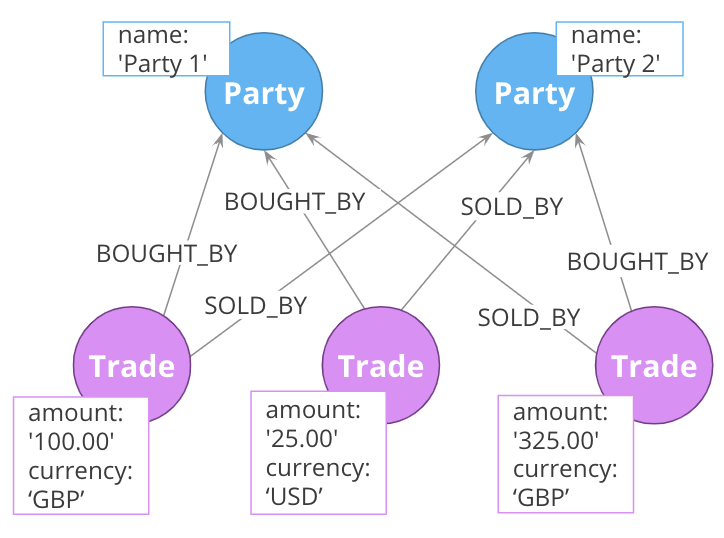
What if we do not want to duplicate the currency type data in all of our Trade nodes?
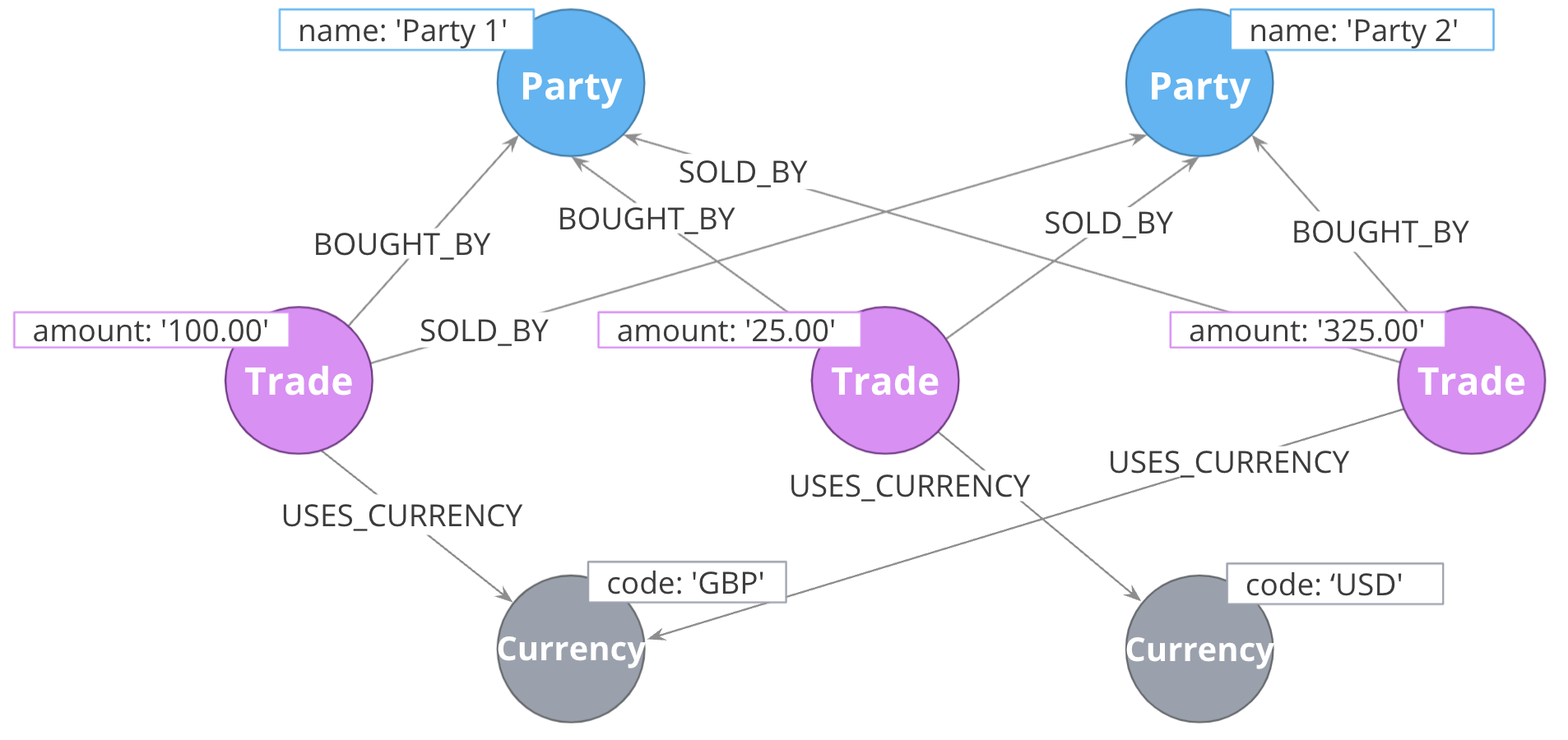
Goal: Use labels instead of property values
If many nodes in the model contain the same value for a property, another solution is the use the property value as a label. Remember, nodes can have multiple labels.
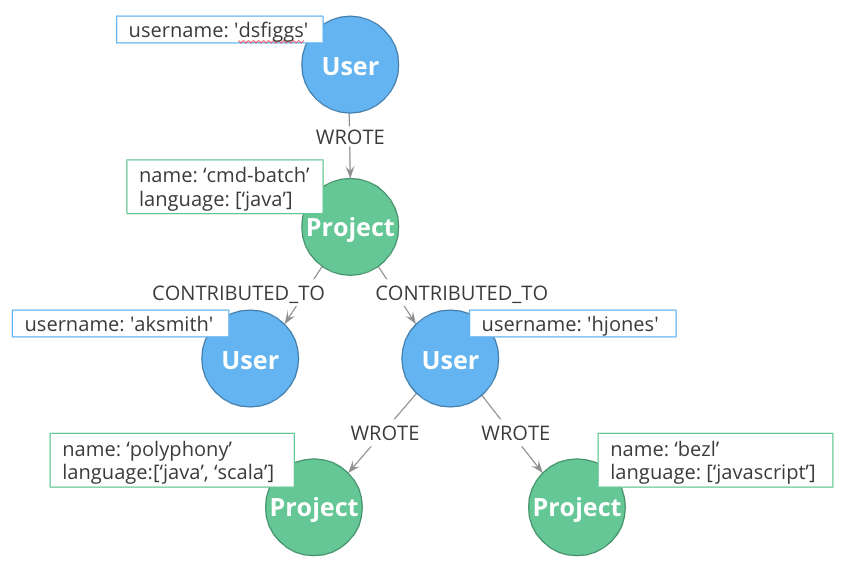
In this example, you see that the Project nodes have a property named language where the property is a list of computer languages. What if you wanted to query the graph to find all projects that are written in java? To do this, you would need to retrieve all of the Project nodes and look for java in the property language list for each node. This is an expensive query on a large graph.
Refactor example: Turn property values into labels for nodes
In this scenario, we take advantage that nodes can have multiple labels. We would go through all Project nodes in the graph and add language labels to the Project nodes for each value in the list contained in the language property. Then we eliminate completely the language property. After this refactoring, it is fast to gather the subset of project nodes with the java label instead of scanning all projects and searching inside a list.
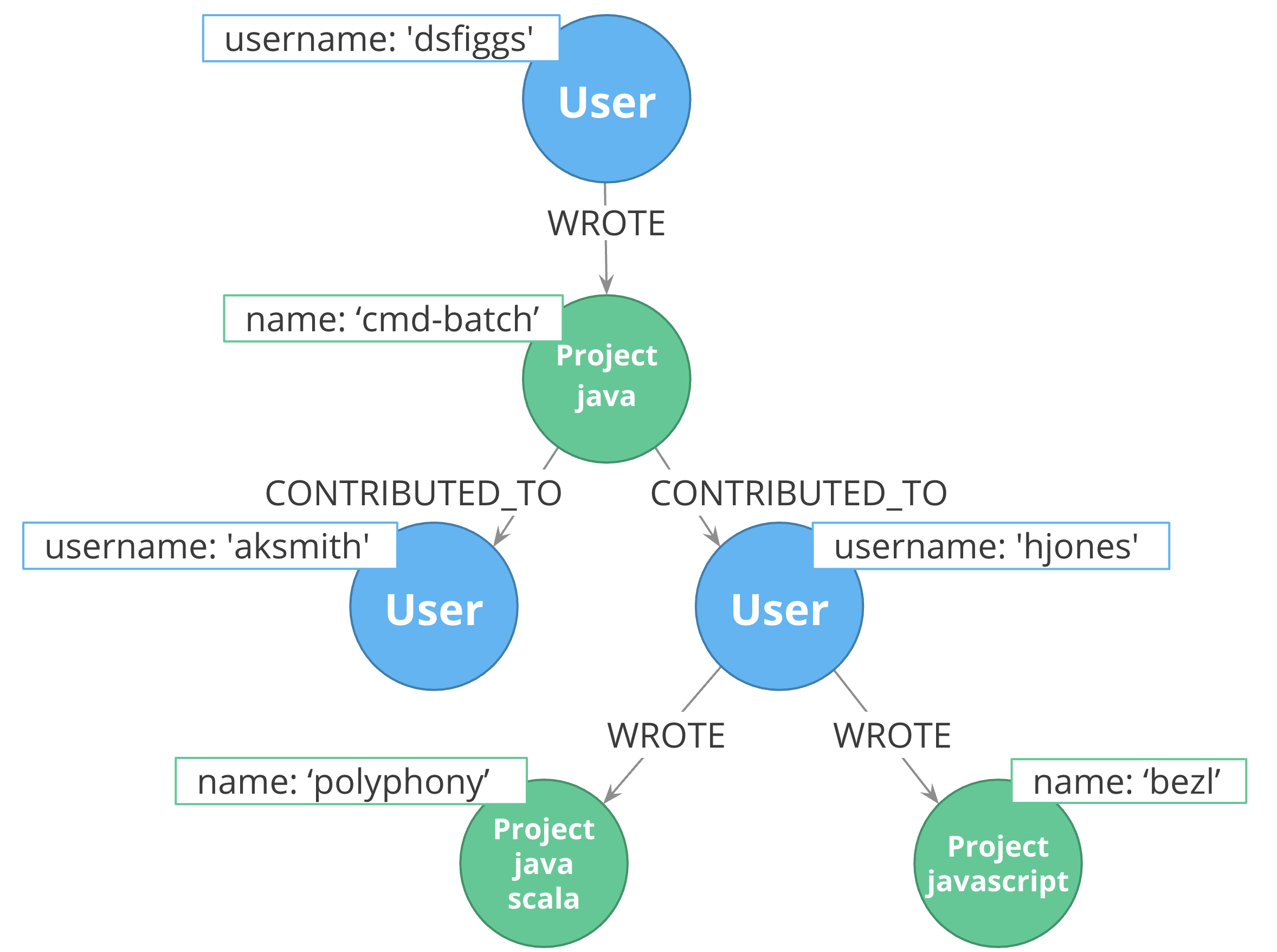
Goal: Use nodes instead of properties for relationships
Previously in this training, you learned that intermediate nodes is sometimes a best practice. Here is the example we saw earlier with the content of the email as a property for the relationship.
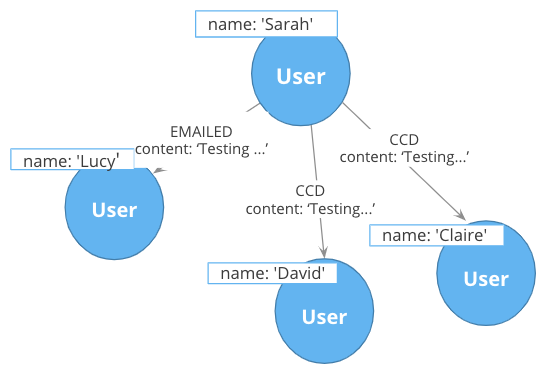
Refactor: Extract nodes from relationship properties
Here is what the graph would look like after we went through all EMAILED and CCD relationships to create the intermediate nodes for the content.
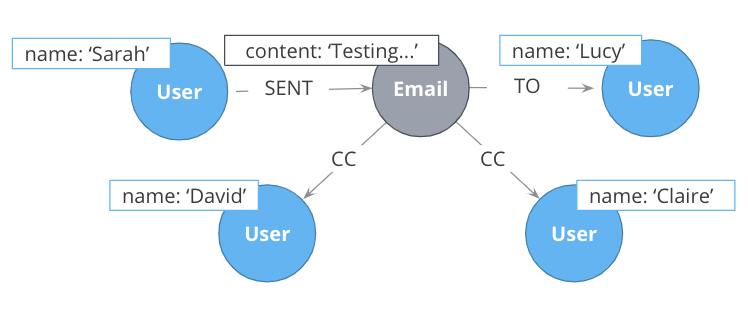
Intermediate nodes are also a frequent result of refactoring. What was previously a relationship property is now a node property, which is not necessarily any more accessible from a query processing standpoint. But it makes the model simpler by reducing the number of relationships connected to each Person node.
Notice that not only is the new node with the label Email, but also relationship types are recreated with different types.
Refactoring example: Modeling airline flights
Here is a very good example of how to model and refactor a model.
Credit: Max De Marzi https://maxdemarzi.com/2015/08/26/modeling-airline-flights-in-neo4j/
We will now walk through an iterative process of graph development and refactoring. We will use, as an example, modeling airline flights for an Orbitz-style use case: that is, answering the problem, “I want to fly from Malmo to New York on Friday”.
You can read in depth about this on Max’s blog.
Initial question for our model
Question: What flights will take me from Malmo to New York on Friday?
Ask yourself:
-
What are the entities?
-
What are the connections between the entities?
-
What properties do we need?
Here, we begin by following the modeling process: identifying entities and connection based on the question. The entities will be Airports, and the connections FLYING_TO, with one connection per flight. Airport data like city and flight data like airline, flight number, departure, etc. are necessary properties.
Initial model
Question: What flights will take me from Malmo to New York on Friday?
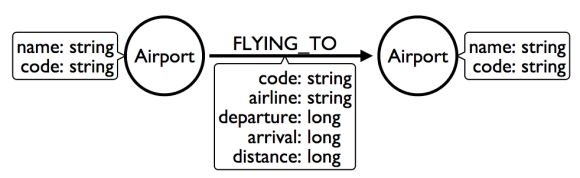
This model answers the first question just fine. But suppose we had to answer a new question?
New Question: Mom is on flight AY189. When will she land?
What must Neo4j traverse to find this answer?
This is a painful one. To find flight AY189, we need to traverse every relationship in the graph, because it is impossible to anchor on relationships. What can we do to make flight data available as an anchor?
Refactor: Create intermediate Flight nodes
This is a perfect use case for adding intermediate nodes. Adding Flight nodes allows us to anchor on flight data, dramatically reducing traversal.
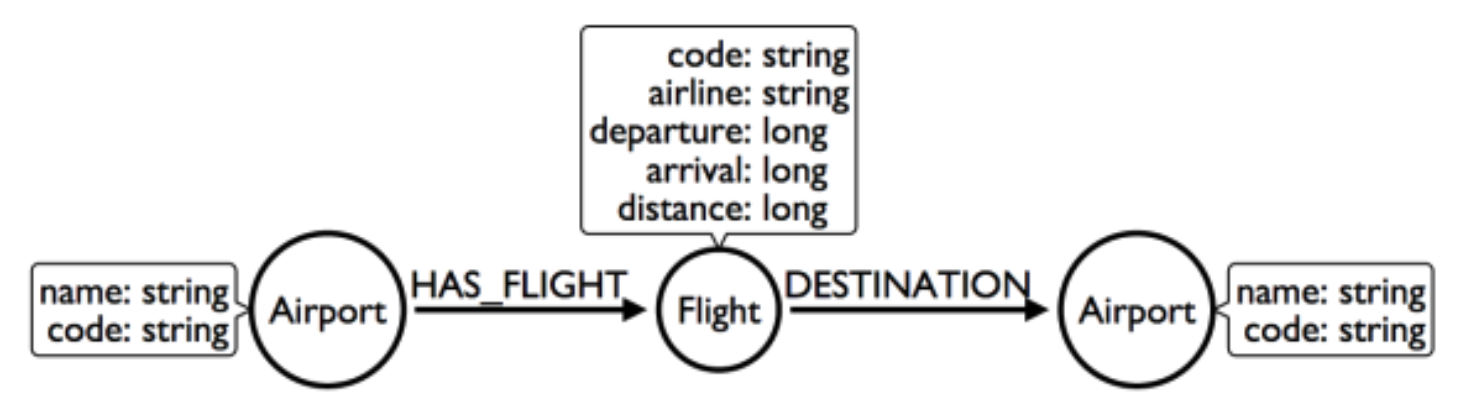
Question 1: What flights will take me from Malmo to New York on Friday?
Question 2: Mom is on flight AY189. When will she land?
But we are still not satisfied with the way we are handling Q1. Airlines are required to publish flight plans 12 months or more in advance. How much work must Neo4j do to answer Q1?
Again, the answer is painful. Neo4j must check every flight leaving Malmo, then consult the flight data to see which ones leave on the appropriate day. That’s even before we check to see which of those flights land in the desired place! How can we elevate the flight date in order to reduce the amount of wasted hops?
Refactor: Create AirportDay intermediate nodes
Again, intermediate nodes come to the rescue. AirportDay nodes reduce the density of Airport nodes, as there are many fewer days in the graph than there are flights. We still need to check every AirportDay to find the right date, but the scope of wasted traversal is lessened.
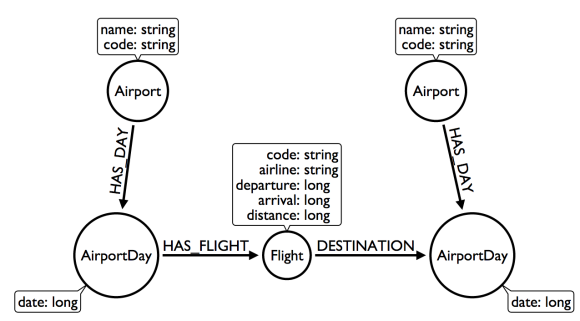
Question 1: What flights will take me from Malmo to New York on Friday?
Question 2: Mom is on flight AY189. When will she land?
Whenever we execute a model change, we also need to check that our older queries are not disrupted. What about Q2?
As long as we continue to be able to anchor on Flight, Q2 is unaffected. This refactor causes no problems.
But thinking more on Q1. How might we arrange things to reduce wasted traversal even further? In other words, how might we elevate flight date even higher on the hierarchy of accessibility?
There are only two ways to do this:
-
Anchor somehow on AirportDay.
-
Make date into a relationship type.
We will refactor to make date a relationship type.
Possible refactor: Change relationship type to date
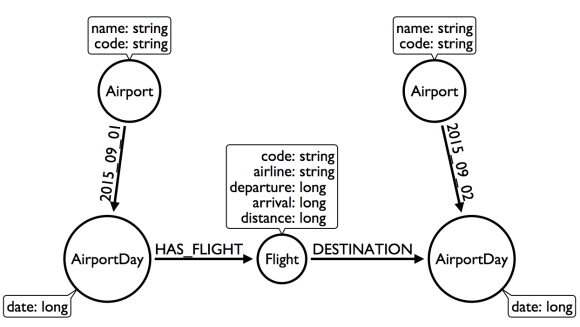
Question 1: What flights will take me from Malmo to New York on Friday?
Question 2: Mom is on flight AY189. When will she land?
Date as the relationship type hardly changes the model at all, with drastic performance improvements. Now, we can traverse only to the relevant AirportDay. Again, Q2 is unaffected.
This is one of the two solutions we had. The other was to anchor on AirportDay. How would the model need to change to make that possible?
Possible refactor: Remove Airport nodes
We could eliminate the Airport nodes entirely, and store airport data on the AirportDay nodes. This shrinks the graph by removing a modest number of Airport nodes, and a large number of Date-typed HAS_DAY relationships. This also performs 2 fewer hops per traversal—a tiny improvement, but one that could add up at scale. We would need to test this benefit more rigorously in production.
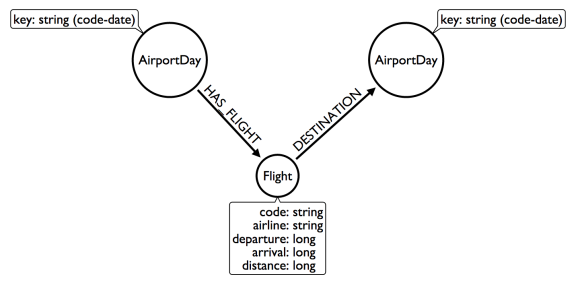
Question 1: What flights will take me from Malmo to New York on Friday?
Question 2: Mom is on flight AY189. When will she land?
The downside to this model is that it is far less intuitive to a human looking at it. As mentioned earlier, refactoring is rarely pure positive; the gains you make in one area often involve sacrifices in others.
So we have a model that seems to work well for Q1. But we have been making one dangerous assumption: that there is a direct flight available. What will Neo4j need to do in order to find an itinerary with 2, 3, 4, or more legs?
This is an expensive problem for this model. Neo4j will traverse every flight leaving that day, and look at destinations. But in the non-direct case, none of the destinations is the correct one. So Neo4j will need to check all the HAS_FLIGHT relationships on those destinations, and see if the second-order destinations include the desired one. If that is not the case, repeat until you find the desired destination. The size of the traversed graph increases exponentially as more and more layovers are added. What can we do to reduce this?
Refactor: Add Destination intermediate nodes
Once again, intermediate nodes come to the rescue! In this case, we are doing two things, further subdividing flights based on destination, but more importantly, we are elevating flight destinations from a 3-hop downstream object to a 1-hop downstream object.
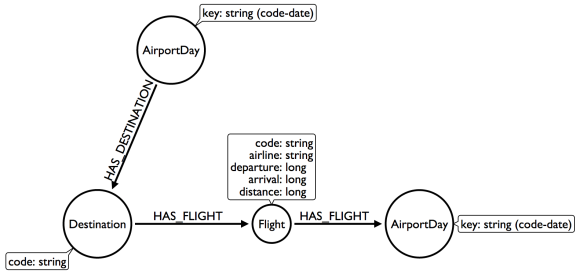
Question 1: What flights will take me from Malmo to New York on Friday?
Question 2: Mom is on flight AY189. When will she land?
How does the non-direct traversal work in this case?
First, Neo4j will check every Destination served by that AirportDay. If the target destination is not there, follow ONE Flight chain to the Airport Day of the destination, then check the served Destinations of that AirportDay. The scope of the graph still grows, but it grows at a rate proportional to the number of Destinations served by an airport, not the number of Flights. And airports tend to have multiple flights per destination, leaving at different times of day.
Once an itinerary leading to the target destination is found, Neo4j can branch out and traverse all the flights connecting those AirportDays.
As always, we must consider: how does this refactor affect Q2?
Once again, the answer is that it does not—we can still anchor on Flight, so Q2 is not disrupted.
Note that this model could never have been produced by simply following our “build initial model” paradigm. AirportDay and Destination nodes are completely opaque relative to the questions we asked. We are OK with that, because, as you will learn that when you implement the model in Cypher, refactoring a graph is relatively inexpensive. Moreover, getting a rough first model quickly reduces the total time we would need to reach this more refined version.
Check your understanding
Question 1
What tasks can be done during the refactoring of a graph data model?
Select the correct answers.
-
Data is moved from one structure in the existing graph to another.
-
A new graph is created from an existing graph.
-
Statistics are collected about the numbers of nodes, properties, and relationships.
-
Data may be added to the graph from other sources.
Question 2
Why do you refactor a graph data model?
Select the correct answers.
-
Improve query performance.
-
Simplify the model to make it more intuitive.
-
Allow for simpler Cypher queries.
-
Make updates to the data in the graph easier.
Question 3
When thinking about refactoring a graph data model. What is the most common type of refactoring you typically do?
Select the correct answer.
-
Rename node labels.
-
Duplicate property values where they will be queried most.
-
Extract property values to change the structure of the graph.
-
Create indexes that will speed up queries for the most important questions.
Summary
You can now:
-
Describe why you would refactor a graph data model.
-
Refactor a model to:
-
Eliminate duplicate data in nodes.
-
Use node labels rather than properties.
-
Extract property values to create nodes.
-
Need help? Ask in the Neo4j Community