Graph Data Modeling Core Principles
About this module
At the end of this module, you will be able to:
-
Describe graph data modeling best practices for modeling:
-
Nodes (entities)
-
Relationships
-
Properties
-
-
Describe data accessibility
Best practices for modeling nodes
Your model must address:
-
Uniqueness of nodes
-
Complex data
Uniqueness of nodes: before
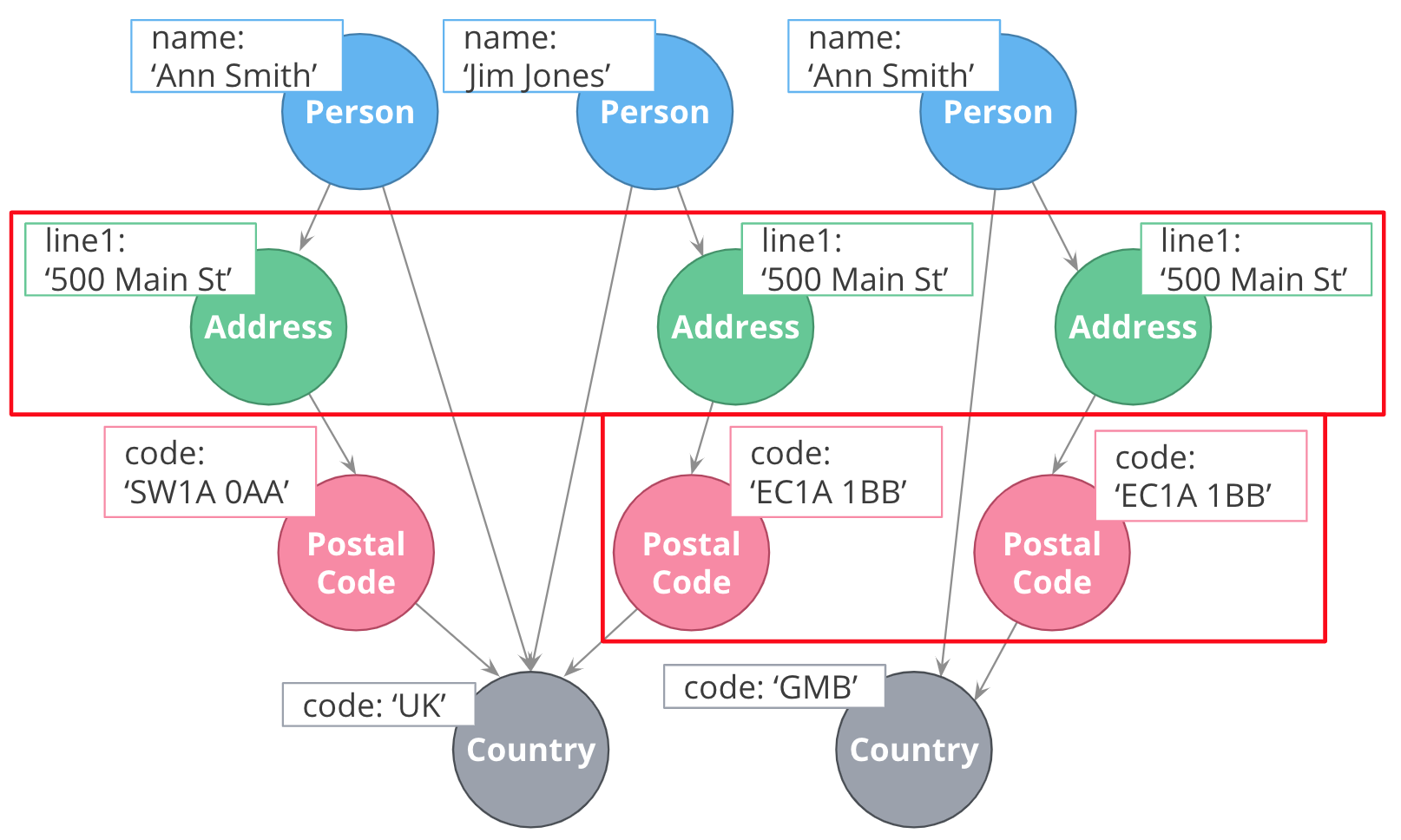
| The Country nodes are considered super nodes (a node with lots of fan-in or fan-out). You need to be careful about using them in your design and developers in particular need to be mindful of queries that might select all paths in or out of the super node. |
In models like this one, an address must be uniquely identified because it represents a single point of data in the graph. This is important in fraud detection applications where variations of the same address may be used to make a fraudulent transaction against the application.
In this particular example, it is clear from the wider context that the various 500 Main St nodes are all distinct places. We also see that postal code is not unique and we want to provide uniqueness to it by adding the country.
Uniqueness of nodes: after
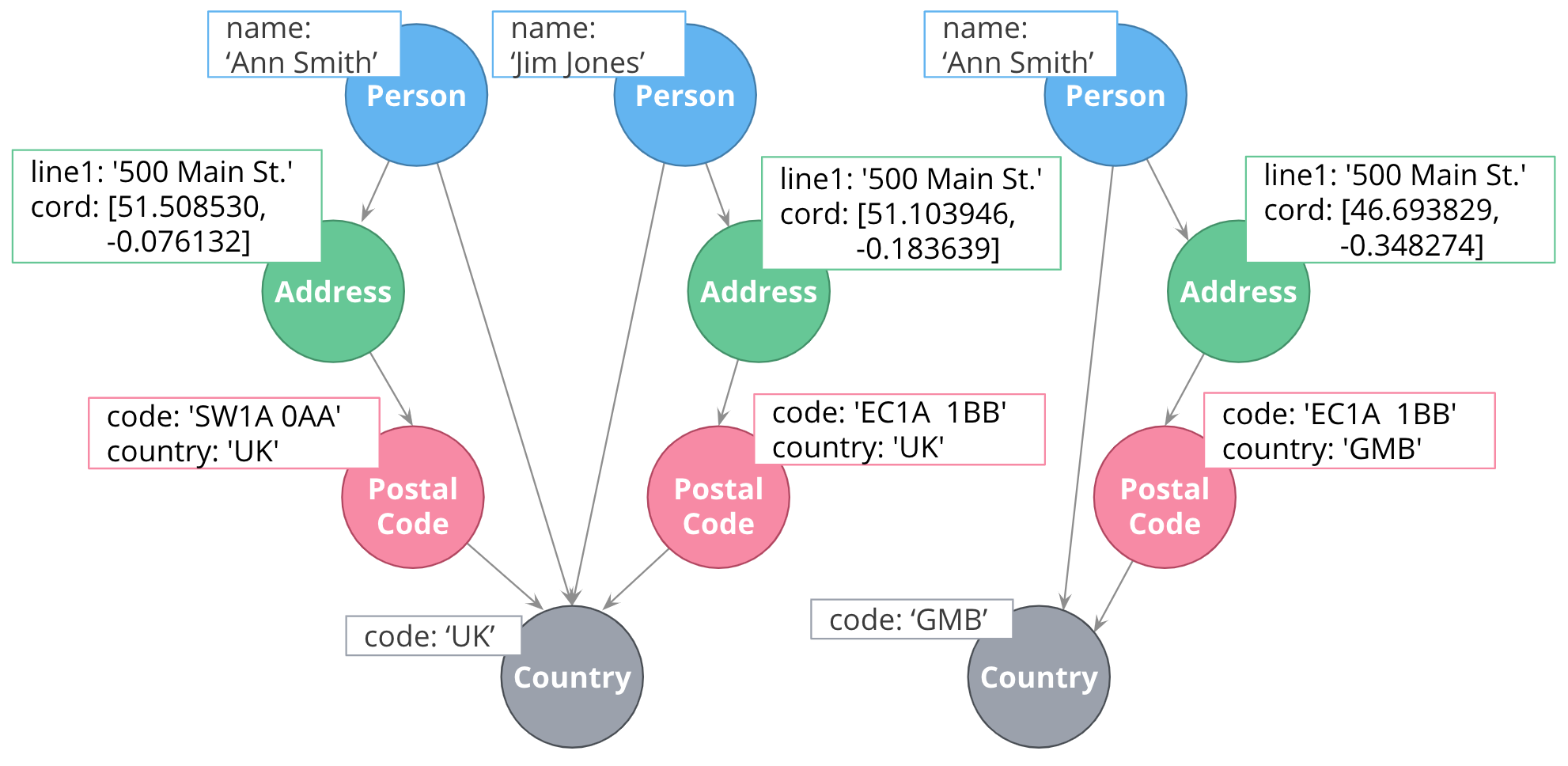
Here is a solution where we have ensured that the Address and PostalCode nodes are unique.
We consider it a best practice to always have a property (or set of properties) that uniquely identify a node. Here, we have added a geolocation property to do so. The geolocation property will likely never be used in a read query, but it can be used to differentiate nodes, especially when loading the data.
There is a trade-off, however as adding uniqueness to a node such Address as it is harder to anchor just on the Line1 value, and may be more difficult to modify the graph data later.
Complex data in One Node

You need to strike a balance between number of properties that represent complex data vs. multiple nodes and relationships.
Here we have a property node that contains properties that contain complex data.
Use fanout judiciously for complex data now spread across multiple nodes
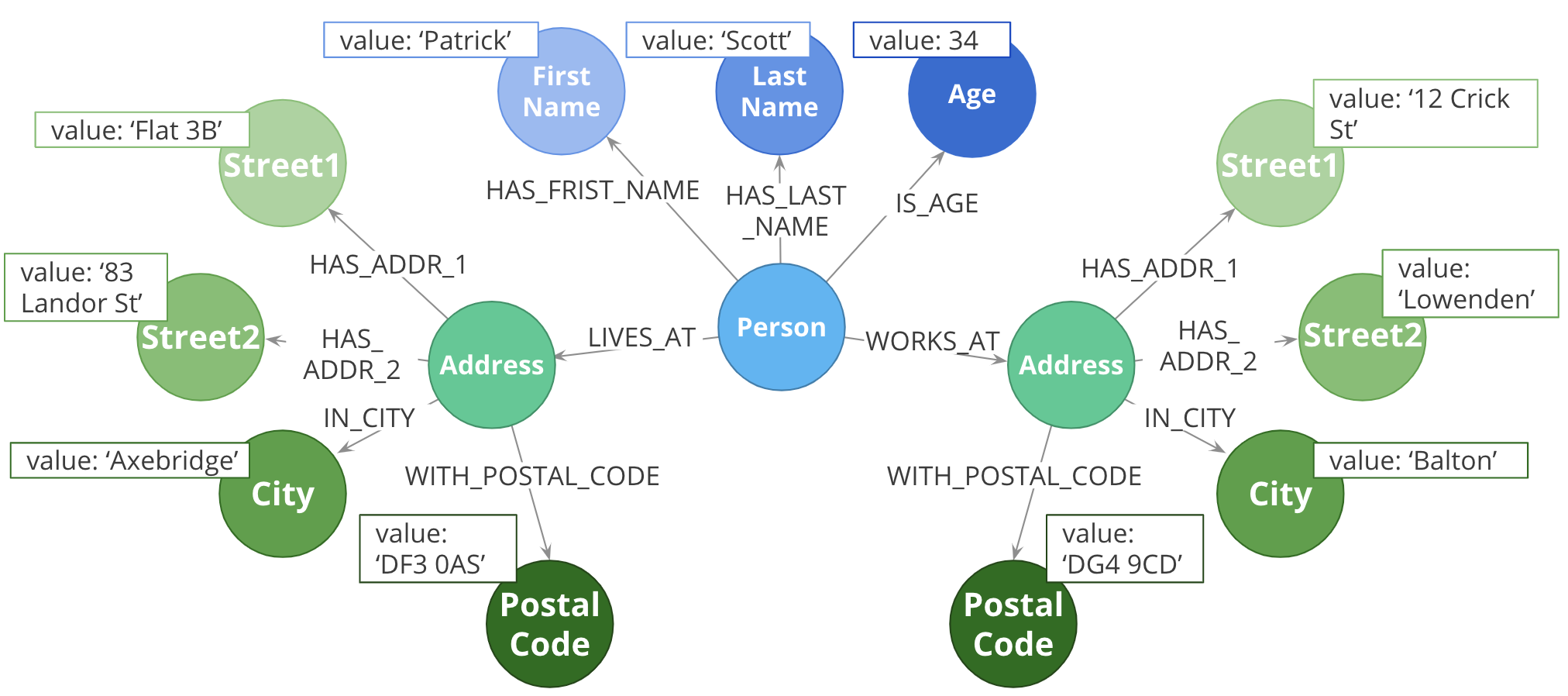
-
Reduce property duplication.
-
Reduce gather-and-inspect.
Here we show an extreme implementation of fanout. For modeling complex data, the previous example with all properties in a node and this example where each property is in its own node are usually suboptimal.
In general, you use fanout to do one of two things.
-
Reduce duplication of properties. Instead of having a repeated property on every node, you can instead have all of those nodes connected to a shared node with that property. This can make data updates massively easier.
-
Reduce gather-and-inspect behavior during a traversal. In the one node example, if we want to find every address in the city of Axebridge, we would need to check the properties on every Person node, then discard the irrelevant nodes. This is grossly inefficient. In this multiple node case, this is a simple matter of locating the singular Axebridge node, and traversing to every Address node connected to it. This model has no “wasted” hops.
As a result, you generally use fanout for anchors and traversing the graph. You almost never see fanout used for output, unique identifier, or decorator properties, because it makes traversal a few hops longer for no real benefit. This is why this maximum-fanout case is usually undesirable. It is almost never the case that every property is an anchor or used for the traversal!
Best practices for modeling relationships
Your model must address:
-
Using specific relationship types.
-
Reducing symmetric relationships.
-
Using types vs. properties.
Using specific relationship types
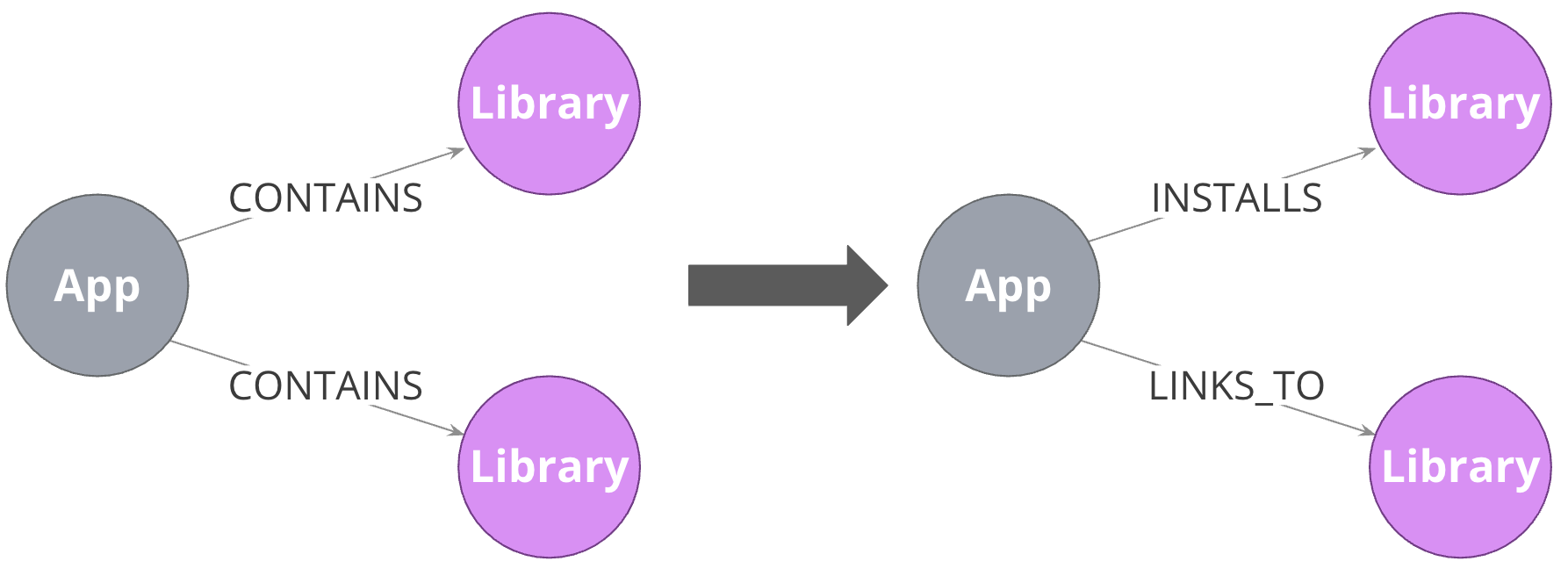
Being specific with relationship types allows you to reduce gather-and-inspect behavior. In this case, if you are only interested in what libraries will be INSTALLED by an app, the specific types on the right saves you some wasted traversal.
But… not too specific
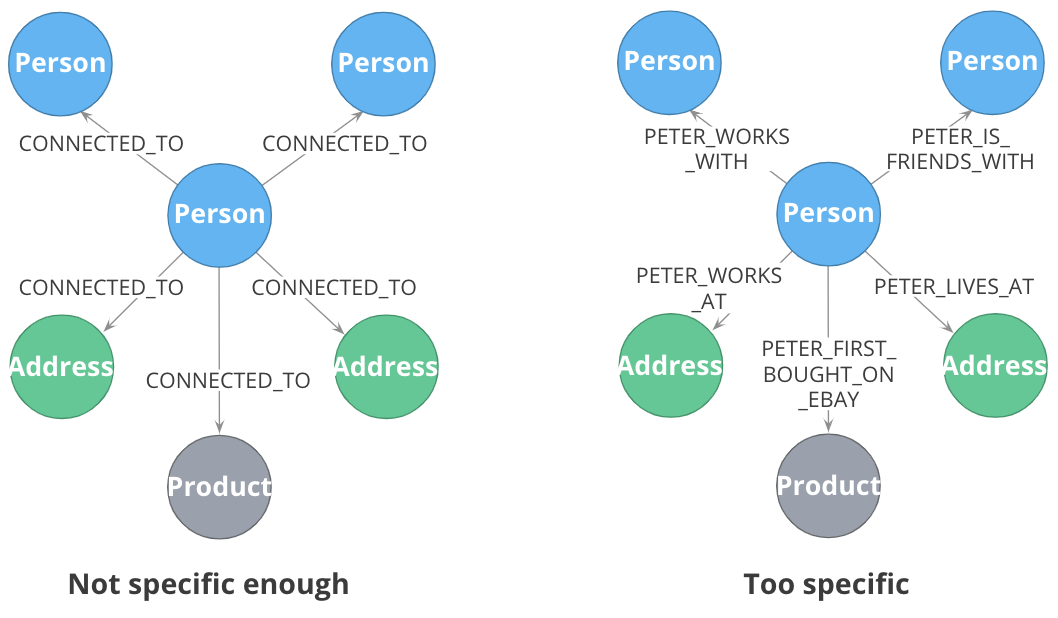
But it is possible to be too specific! The model on the right makes it impossible to write generalized queries. If you want to find every person who works at a given address, you would need to write a massive WHERE clause (using OR) to include every person’s name in the relationship type
No symmetric relationships
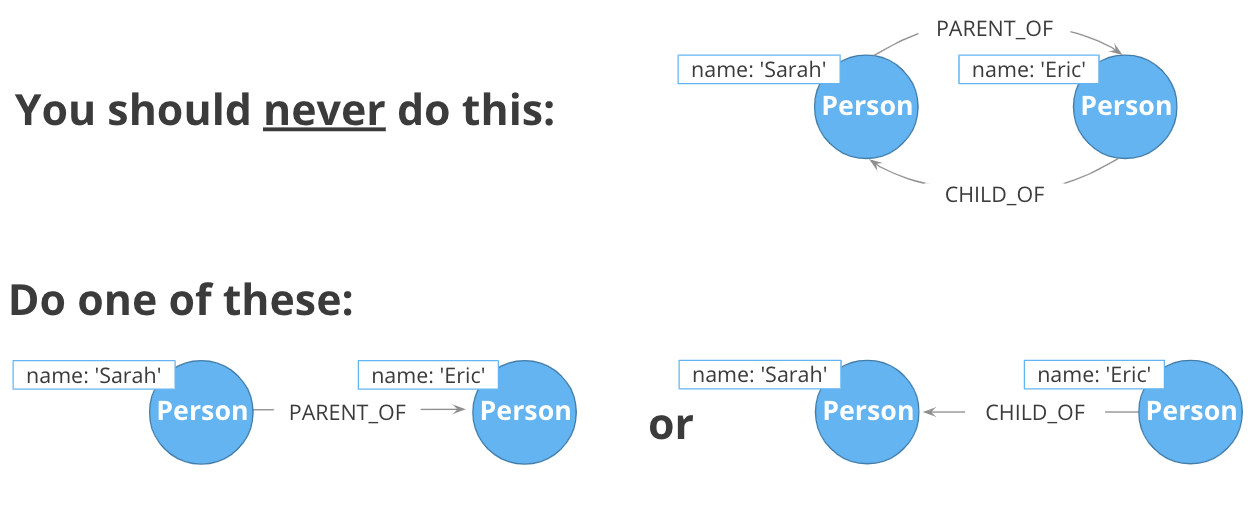
Semantically symmetric relationships present two problems.
First, they are a form of needless data duplication. PARENT_OF and CHILD_OF mean exactly the same thing. You cannot have one be true and the other not.
Second, they allow you to violate the Cypher expectation of relationship uniqueness. Semantically, you have two identical relationships—they just look different technically. This allows you to traverse the same relationship twice.
Relationships require space in the graph so minimizing their numbers is always a good thing.
Semantics of symmetry are important
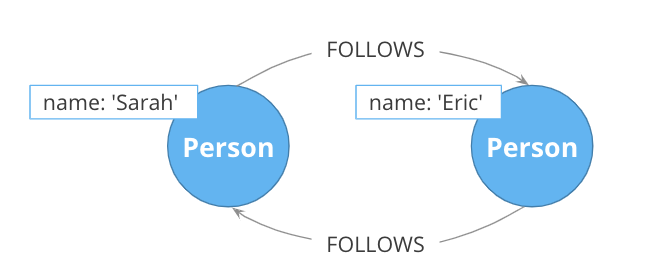
Not all mutual relationships are semantically symmetric.
Here is an example where the direction of the FOLLOWS relationship on Twitter is significant. It matters who has followed who.
Using types vs. properties
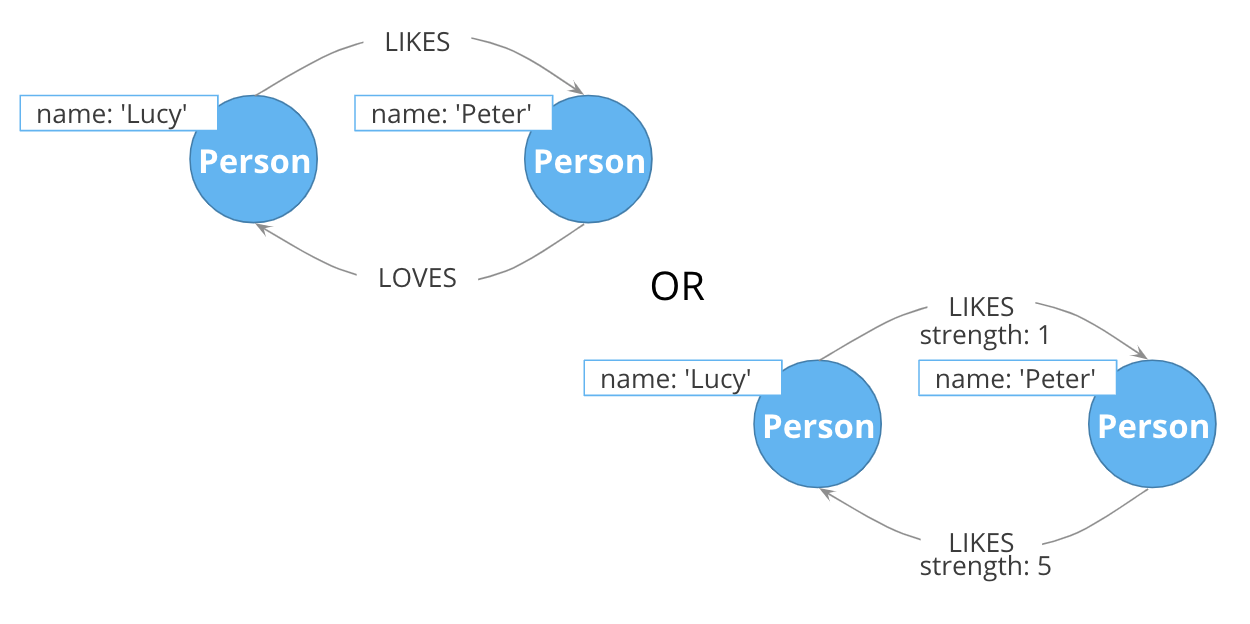
Both of these models represent the same idea in different ways. Neither is strictly superior; both are optimized for a certain kind of question.
For example, if you want to find all LOVES relationships, but ignore the weaker LIKES ones, the top model is better. Traversal will not involve any gather-and-inspect. On the other hand, if you want to rank the strength of all relationships, the below model is better. The Cypher string required is much simpler, and we know there will not be any gather-and-inspect discards because we want everything anyway.
Property best practices
-
Property lookups have a cost.
-
Parsing a complex property adds more cost.
-
Anchors and properties used for traversal will be as simple as possible.
-
Identifiers, outputs, and decoration are OK as complex values.
When talking about properties, every best practice has exceptions. In the case of property value complexity, it depends on how the property is used.
Anchors and traversal paths that use property values need to be parsed at query time. If the cost of parsing them is high, querying slows down. Other properties, though, just need to be returned as-is because they do not require parsing. Complexity there does not matter much.
In other words, this "bad model" from before might actually be OK. If those addresses are never used as an anchor or for determining how to traverse the graph, and only as an output, then their complexity will not be an issue.
Data accessibility
For each query, how much work must Neo4j do to evaluate if the traversal represents a “good” path or a “bad” one?
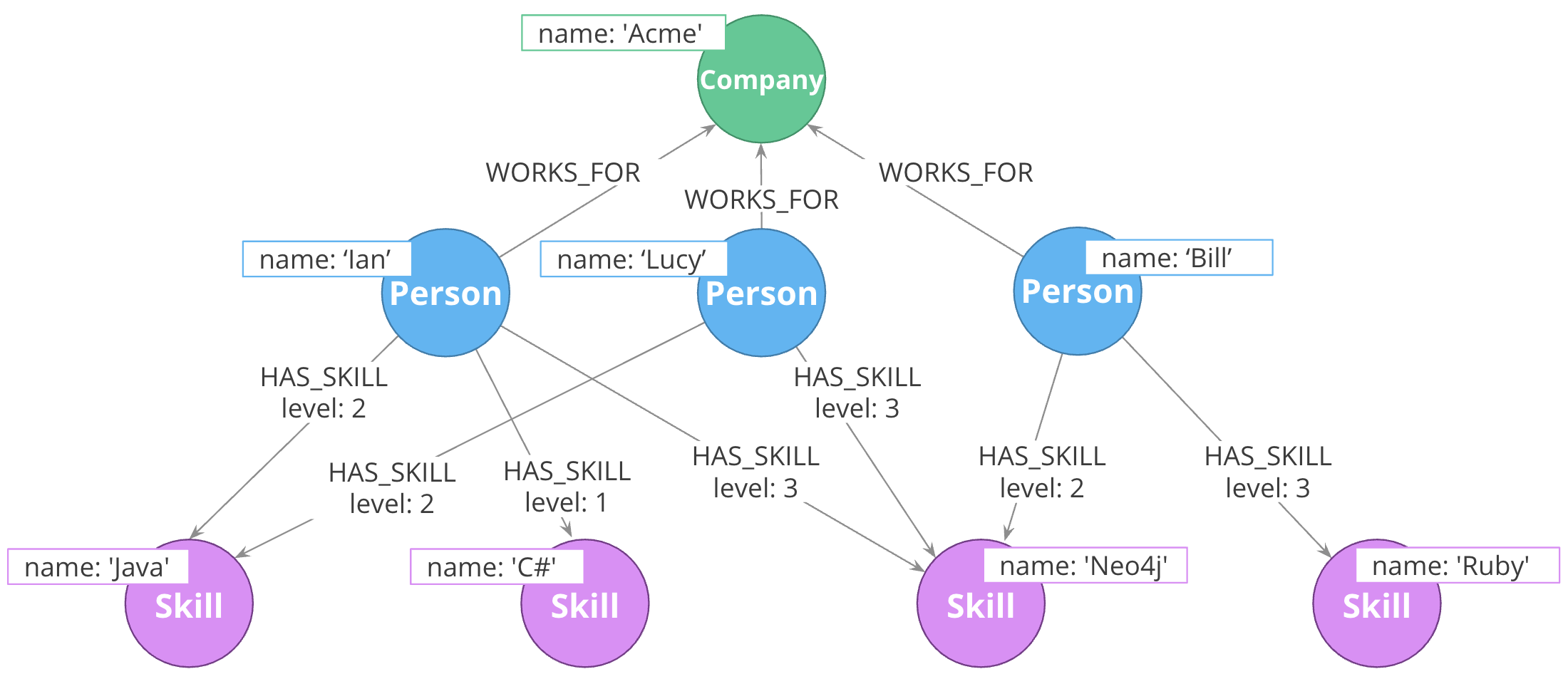
Neo4j allows you to data or information as labels, properties, and relationship types. In most cases, there is a way you can model your graph so that data being queried is in any one of these three locations.
When designing or refactoring a model, you can estimate performance by checking how “accessible” the data is that represents the important queries of your application.
Hierarchy of accessibility
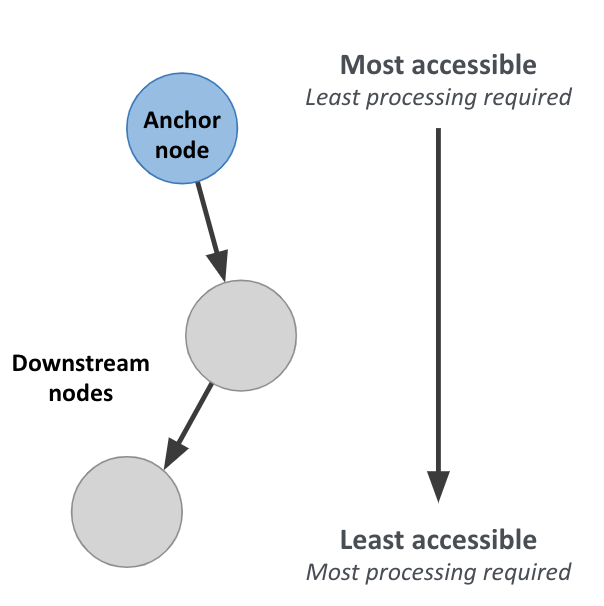
For data in the query, how much work must Neo4j do to evaluate if this is a “good” path or a “bad” one?
-
Anchor node label, indexed anchor node properties
-
Relationship types
-
Non-indexed anchor node properties
-
Downstream node labels
-
Relationship properties, downstream node properties
Anchor node data, which could be a node label or a node property value, is cheapest to access—it involves no traversal at all, and thus no wasted traversal. Indexed anchor properties are much more accessible than non-indexed anchor properties.
Neo4j is designed for easy traversal, so relationship types are also very cheap to access. In fact, we recommend using types in Cypher queries always, because the cost of the type lookup is minimal. And if you do not use a type name in your traversal path, you will likely use something even less accessible, like downstream properties.
Downstream information such as labels and properties further down the traversal path are the most expensive thing to access. The further downstream, the more expensive they are. That is not to say they are necessarily deal-breakers, but elevating downstream data via a model change is one of the most reliable ways to improve query performance. For example, reduce how far downstream a query traversal must go to get the necessary data, or change the model so that the downstream data is available in a relationship type instead of a node label or property.
Keep in mind, however, that query performance is not the only metric that matters! Query simplicity, write/update speed, and the human-intuitiveness of a model are also important factors. When considering whether to elevate some data along this hierarchy, speed must be weighed against the impact this will have on those other factors.
Check your understanding
Question 1
What are some benefits of using fanout for your nodes?
Select the correct answers.
-
Reduces the number of nodes in the graph.
-
Reduces duplication of property values.
-
Reduces the number of relationships defined in the graph.
-
Reduces gather-and-inspect traversals during a query.
Question 2
Why is naming relationship types to be as specific as possible a benefit?
Select the correct answers.
-
Reduces the number of relationships in the graph.
-
Reduces traversals through nodes that are not necessary for the query.
-
Reduces gather-and-inspect traversals during a query.
-
Reduces the number of nodes in the graph.
Summary
You can now:
-
Describe graph data modeling best practices for modeling:
-
Nodes (entities)
-
Relationships
-
Properties
-
-
Describe data accessibility
Need help? Ask in the Neo4j Community