Centrality Algorithms
Centrality algorithms
In network analysis, centrality measures identify the most important or influential nodes within a graph. The centrality concepts were first introduced in social network analysis to identify key players within a social network, but have since found applications in a variety of industries and fields.
Product supported:
-
PageRank
-
Betweenness Centrality
Labs implementations:
-
Degree Centrality
-
ArticleRank
-
Closeness Centrality
-
Harmonic Centrality
-
Eigenvector Centrality
PageRank
PageRank is Google’s popular web page ranking algorithm.
It works by counting the number and quality of links to a node to estimate its significance. The underlying assumption is that a node is only as important as the nodes that link to it. An example of this type of influence might be having the ear of a general that considers you very credible will likely make you more powerful than being popular with your fellow foot soldiers.
|
PageRank measures importance in comparison to other nodes using an iterative process to update ranks. It starts by assigning values to nodes as 1/n (n is the total number of nodes linked to it) and value to relationships as that nodes value/number of its outgoing links. |
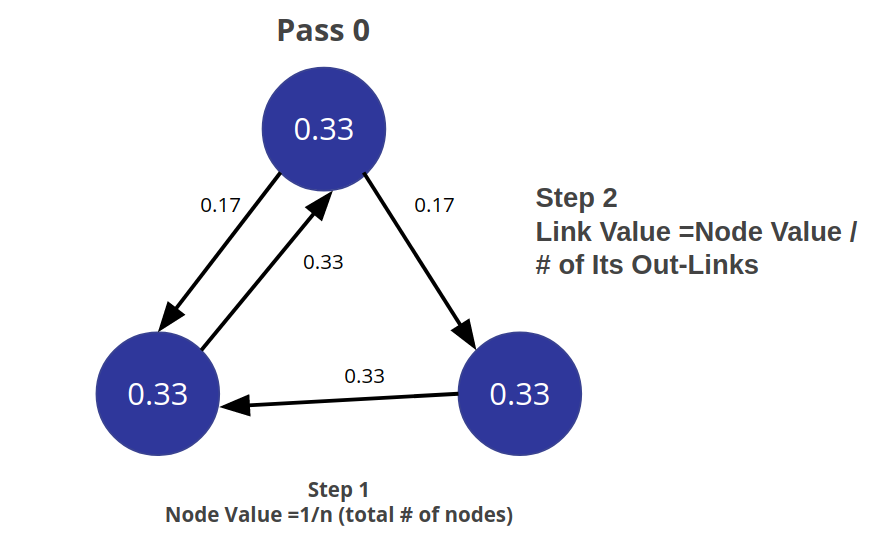
|
It then starts to update values for nodes as the sum of the prior in-link values. The relationship values are updated the same way they were initially assigned. |
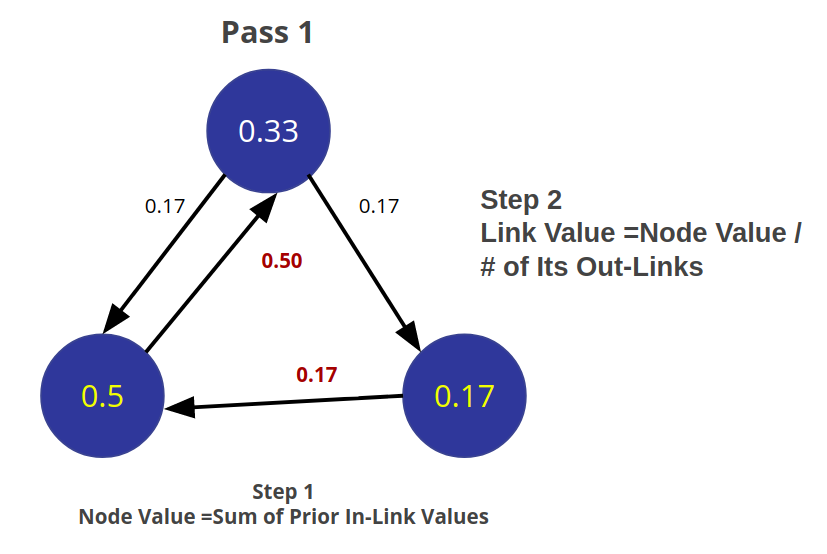
|
PageRank then continues to update values until an iterate value is reached. |
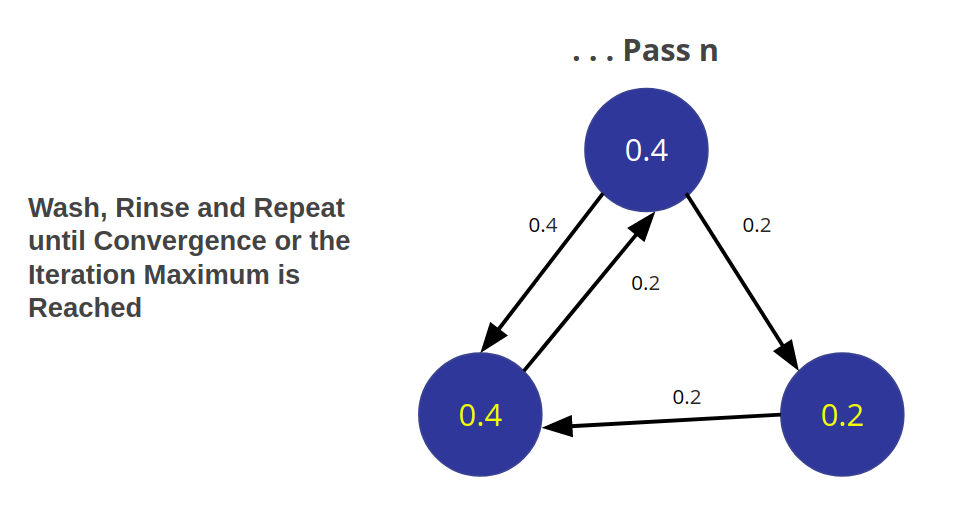
There are many domain-specific variations for differing analyses, e.g. Personalized PageRank for personalized recommendations. Personalized PageRank is a variation of PageRank, which is biased towards a set of predefined source nodes.
Why use PageRank?
Here is why you use PageRank:
-
Recommendations
-
Fraud Detection
-
Feature engineering for machine learning
Here are some examples:
-
Twitter uses Personalized PageRank to present users with recommendations of other accounts that they may wish to follow. The algorithm is run over a graph that contains shared interests and common connections.
-
PageRank has been used to rank public spaces or streets, predicting traffic flow and human movement in these areas. The algorithm is run over a graph of road intersections, where the PageRank score reflects the tendency of people to park, or end their journey, on each street.
-
PageRank is also used as part of an anomaly and fraud detection system in the healthcare and insurance industries. It helps reveal doctors or providers that are behaving in an unusual manner and then feeds the score into a machine learning algorithm.
-
Find the most influential features for extraction in machine learning and rank text for entity relevance in natural language processing.
Betweenness Centrality
Sometimes the most critical cog in the system is not the one with the most overt power or the highest status. Sometimes it is the middlemen who connect groups or brokers with the most control over resources or information flow.
Betweenness Centrality is a way of detecting the amount of influence a node has over the flow of information in a network. It is typically used to find nodes that serve as a bridge from one part of a graph to another.
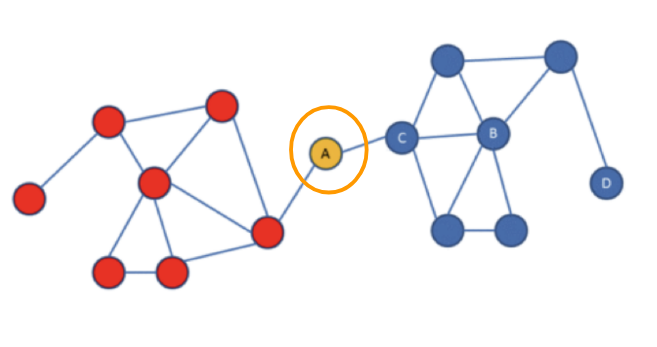
The Betweenness Centrality algorithm first calculates the shortest path between every pair of nodes in a connected graph. Each node receives a score based on the number of these shortest paths that pass through the node. The more shortest paths that a node lies on, the higher its score.
Betweenness Centrality does not scale well on large graphs as the algorithm has to calculate the shortest path between all pairs of nodes in a network. Because of this, approximation algorithms of Betweenness Centrality were developed to allow for a faster calculation. The RA-Brandes algorithm is the best-known algorithm for calculating an approximate score for Betweenness Centrality. Rather than calculating the shortest path between every pair of nodes, the RA-Brandes algorithm considers only a subset of nodes. Brandes defines several strategies for selecting the subset of nodes. The GDSL implementation is based on the random degree selection strategy, which selects nodes with a probability proportional to their degree. The idea behind this strategy is that such nodes are likely to lie on many shortest paths in the graph and thus have a higher contribution to the Betweenness Centrality score.
Why use Betweenness Centrality?
Here is why you use Betweenness Centrality:
-
Identify bridges
-
Uncover control points
-
Find bottlenecks and vulnerabilities
Here are some examples:
-
Betweenness Centrality is used to identify influencers in various organizations. Powerful individuals are not necessarily in management positions, but can be found in “brokerage positions” using Betweeness Centrality. Removal of such influencers seriously destabilize the organization. This might be a welcome disruption by law enforcement if the organization is criminal, or may be a disaster if a business loses key staff it never knew about.
-
Betweenness Centrality uncovers key transfer points in networks such as electrical grids. Counter-intuitively, removal of specific bridges can actually improve overall robustness by “islanding” disturbances.
-
Betweenness Centrality is also used to help micro-bloggers spread their reach on Twitter, with a recommendation engine for targeting influencers.
Check your understanding
Question 1
Which of the following Centrality algorithms are fully-supported?
Select the correct answers.
-
Degree Centrality
-
PageRank
-
Closeness Centrality
-
Betweenness Centrality
Summary
In this lesson, you gained experience with the two Neo4j supported Centrality algorithms:
-
PageRank
-
Betweenness Centrality
You can read more about these algorithms and also the alpha (labs) algorithms in the Graph Data Science documentation
Need help? Ask in the Neo4j Community