Similarity Algorithms
Similarity algorithms
Similarity algorithms evaluate how alike nodes are at an individual level based on node properties, neighboring nodes, or relationship properties.
Product supported:
-
Node Similarity (Jaccard Index)
Labs implementations:
-
Cosine Similarity
-
Euclidean Similarity
-
Overlap Similarity
-
Pearson Similarity
-
Approximate Nearest Neighbors
Node Similarity algorithm
The Node Similarity algorithm computes similarities between pairs of nodes based on the Jaccard Similarity Score. Two nodes are considered similar if they share many of the same neighbors.
The input of this algorithm is usually a bipartite graph containing two disjoint node sets. The Node Similarity algorithm compares all nodes from the first node set based on their relationships to nodes in the second set. The output of the algorithm is a unipartite network between nodes in the first node set. We can think of this process as translating indirect relationships to direct ones. Mathematically, Jaccard Similarity Score is defined as the size of the intersection divided by the size of the union of two sets.
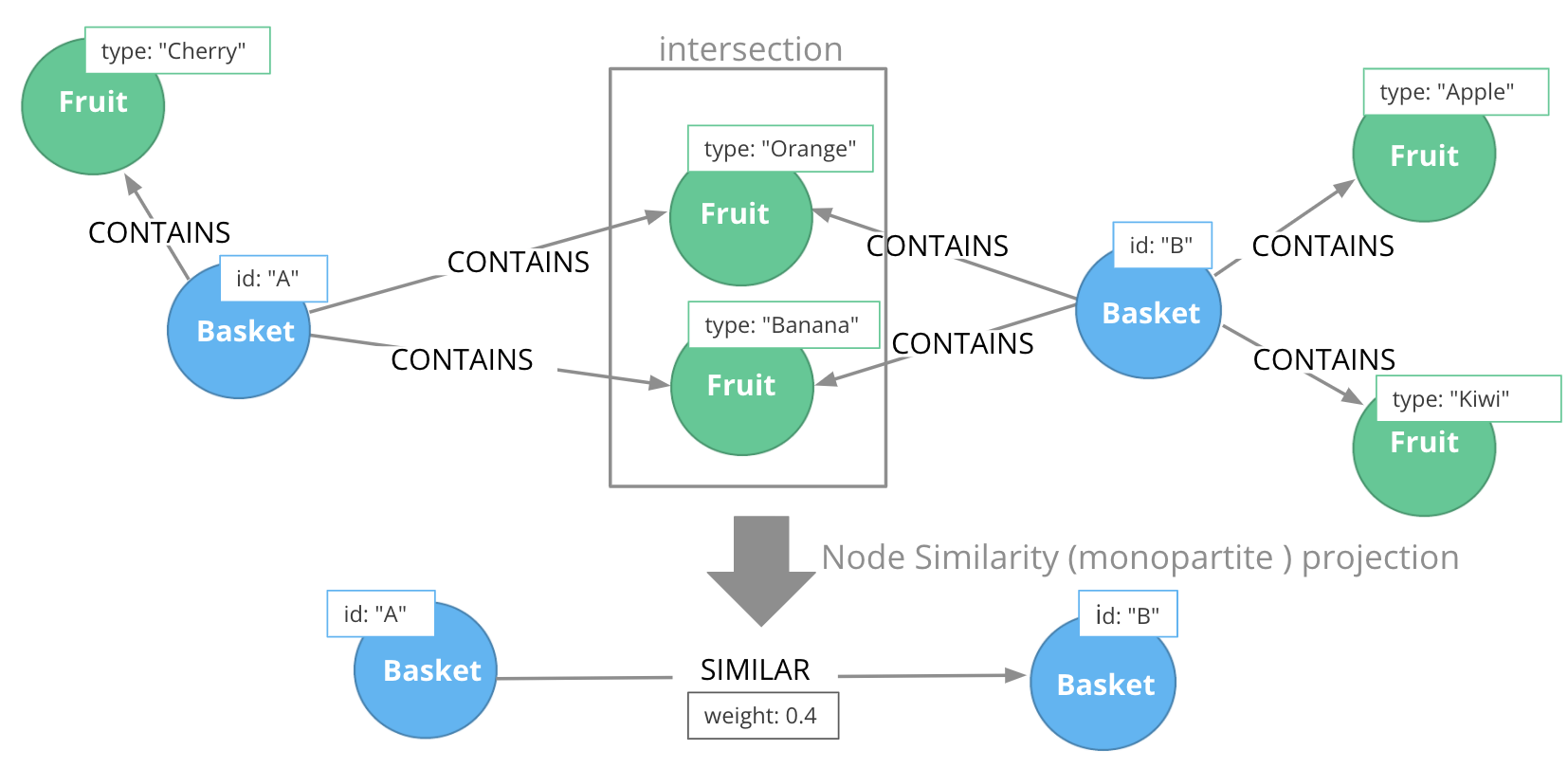
Example: Node Similarity
For example, if Basket A contains {Orange, Banana, Cherry} and Basket B contains {Orange, Banana, Apple, Kiwi} then the Jaccard algorithm counts 2 co-occurrences {Orange, Banana} and divides that count by the number of items in A and B (while not double-counting items), in this case 5 {Orange, Banana, Apple, Cherry, Kiwi}. The resulting Jaccard Similarity Coefficient is 2/5 which is 0.4. A coefficient of 1 indicates that the compared sets are identical.
Exercise: Node Similarity
-
In NEuler:
-
Try various algorithm configurations for the Questions dataset.
-
Try other datasets.
-
-
In Neo4j Browser: :play 4.0-intro-graph-algos-exercises and follow the instructions for Node Similarity.
| Estimated time to complete: 20 minutes |
Check your understanding
Question 1
Which Similarity algorithm is fully supported in the Graph Data Science Library?
Select the correct answer.
-
Pearson Similarity
-
Euclidean Similarity
-
Node Similarity (Jaccard Index)
-
Overlap Similarity
Summary
In this lesson you gained some experience with the Neo4j supported Node Similarity (Jaccard Index) algorithm.
You can read more about this algorithm and also the alpha (labs) algorithms in the Graph Data Science documentation
Need help? Ask in the Neo4j Community