When your agents share a brain: Building multi-agent memory with Neo4j

Senior Product Manager
9 min read
How your agent can share short-term, long-term, and reasoning memory through a single Neo4j graph and what that means for building agents.
If you’ve built AI agents, you know the pattern: each agent gets its own memory, its own context, its own silo. That works fine for demos. But it falls apart the moment you need two agents to collaborate on the same problem.
In financial services, that’s not a theoretical concern. When a KYC analyst agent discovers that a customer has ties to a sanctioned entity, the credit assessment agent needs to know about it immediately — not after a manual handoff, not through an ad-hoc message bus, but through shared, structured memory that both agents can read and write.
Today I want to walk through how we built exactly that: a multi-agent financial services system where a KYC agent, a credit agent, and an orchestrator share all three memory types — short-term, long-term, and reasoning — through a single Neo4j instance using neo4j-agent-memory and AWS Strands.
The architecture: one graph, three agents
The core idea is simple. Instead of giving each agent its own memory store, we create one set of memory tools connected to a single Neo4j Aura database instance, and pass those tools to every agent.
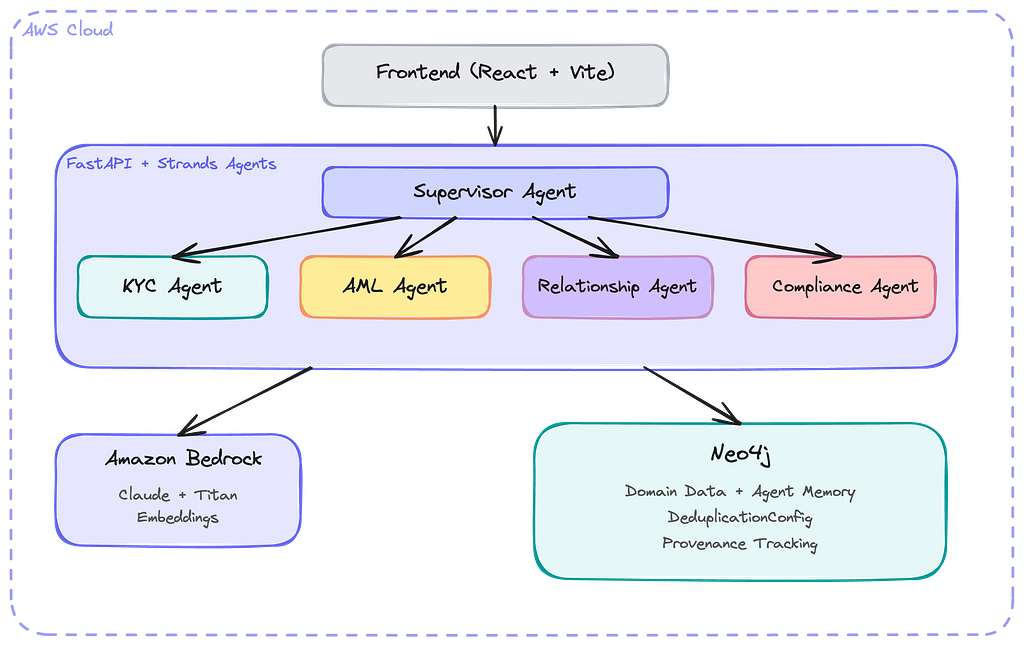
The context_graph_tools() function from the Strands integration returns four tools:
- search_context,
- get_entity_graph,
- add_memory, and
- get_user_preferences.
Because every agent receives the same tool instances, they all read from and write to the same shared graph with a compatible data model.
from neo4j_agent_memory.integrations.strands import context_graph_tools
# One shared tool set for all agents
tools = context_graph_tools(
neo4j_uri=os.environ["NEO4J_URI"],
neo4j_password=os.environ["NEO4J_PASSWORD"],
embedding_provider="bedrock",
aws_region="us-east-1",
)
# Each agent gets the SAME tools
kyc_agent = Agent(model=MODEL, tools=tools, system_prompt=KYC_PROMPT)
credit_agent = Agent(model=MODEL, tools=tools, system_prompt=CREDIT_PROMPT)
orchestrator = Agent(model=MODEL, tools=tools, system_prompt=ORCH_PROMPT)
That’s it. That’s the shared memory layer. No message queues, no pub/sub, no serialization formats. Each agent writes to the graph; every other agent can read it on their next tool call.
Why shared memory matters for compliance
In a traditional multi-agent system without shared memory, each agent operates in isolation. Three specific problems emerge in regulated industries:
- Duplicated entity extraction. Both the KYC agent and the credit agent might process the same customer data, extracting the same entities independently. This wastes compute and creates inconsistencies when extractions differ.
- Blind spots. The KYC agent flags a customer for suspicious activity, but the credit agent never sees the flag. It approves a loan that should have been held for review.
- No audit trail. Regulators ask: “Why did the agent approve this credit application?” You can’t answer, because the credit agent’s reasoning was never connected to the KYC agent’s findings.
Shared graph memory solves all three. Entities are extracted once and deduplicated. Findings from any agent are immediately visible to every other agent. And reasoning traces are connected to the entities and messages that informed them — creating a full provenance chain.
How it works: KYC writes, Credit reads
Let me trace a concrete interaction through the system to show what shared memory looks like in practice.
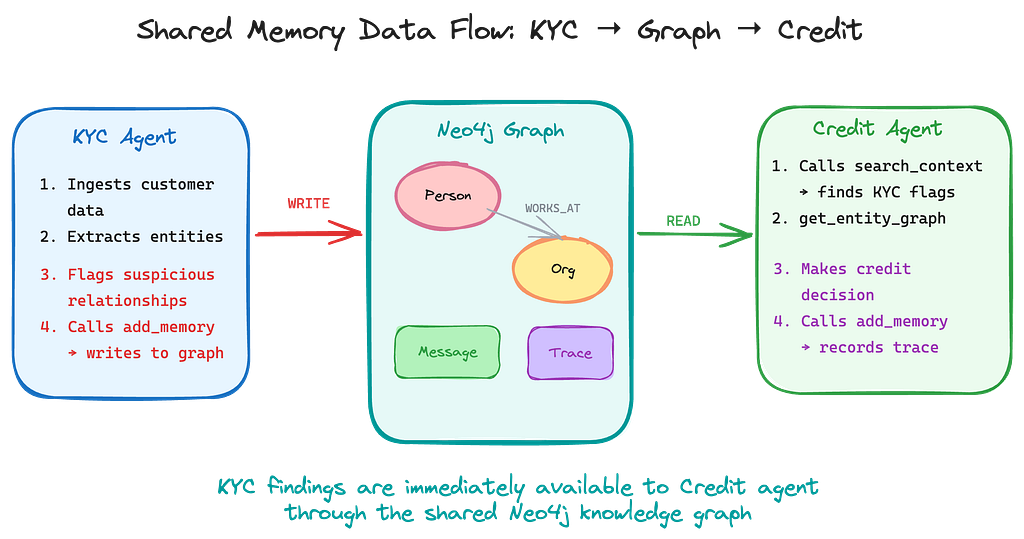
Step 1: KYC processes a new customer
A user submits customer data to the KYC agent:
“New customer John Mercer, CEO of Meridian Capital LLC, based in Zurich. Account opened with $2.4M initial deposit.”
The KYC agent’s system prompt instructs it to use memory tools for every finding. It:
- Calls add_memory to store the customer data. The tool automatically extracts entities: John Mercer (:Person), Meridian Capital LLC (:Organization), Zurich (:Location).
- Creates relationships: WORKS_AT, LOCATED_IN.
- Flags the high initial deposit as a risk indicator and stores that finding.
Step 2: Credit agent sees the KYC findings
When the credit agent later receives:
“Evaluate credit application for John Mercer, requesting $5M line of credit,”
it:
- Calls search_context for “John Mercer” — and immediately finds the KYC agent’s findings, including the high-deposit flag.
- Calls get_entity_graph to see all of Meridian Capital’s connections: the Zurich location, the CEO relationship, any other entities linked in the graph.
- Makes a credit decision informed by the full picture — not just the credit application data.
- Calls add_memory to record its decision with complete reasoning, creating a reasoning trace in the graph.
The key insight: The credit agent never needed to ask the KYC agent for its findings. It found them through the shared graph. This is the difference between shared memory and message passing — the knowledge is always there, queryable by any agent, at any time.
The provenance chain: How the graph enables auditability
This is where the graph architecture really pays off. When a compliance officer asks “Why was this credit application approved?”, you can answer with a single Cypher query that traverses from the decision, through the shared entities, back to the original KYC findings.
// Trace a credit decision back to its source findings
MATCH (decision:Message)
WHERE decision.content CONTAINS 'credit decision'
MATCH (decision)-[:MENTIONS]->(entity:Entity)
MATCH (entity)<-[:MENTIONS]-(finding:Message)
WHERE finding.createdAt < decision.createdAt
RETURN decision.content AS decision,
entity.name AS shared_entity,
finding.content AS source_finding
ORDER BY finding.createdAt
In a vector-only memory system, the credit decision and the KYC finding would both be stored as embeddings. To find connections between them, you’d need to do a similarity search and hope the vectors are close enough in embedding space. That’s probabilistic retrieval — it might work, it might not.

With a graph, the connection is explicit and deterministic. The credit decision directly refers to John Mercer. John Mercer was concretely linked in the KYC finding. The traversal is guaranteed to find it. No similarity threshold to tune, no results to rerank — just a graph traversal that returns exactly the provenance chain you need.
Graph handles understanding; vector handles similarity. Neo4j stores the structured relationships — who is connected to whom, what decisions referenced which entities. Vector search finds content that’s semantically similar. Together, they give agents both precise graph traversal and fuzzy semantic recall. Neo4j Agent Memory provides both.
The three memory types
Every agent in the system reads and writes to three memory layers, all stored as nodes and relationships in Neo4j.
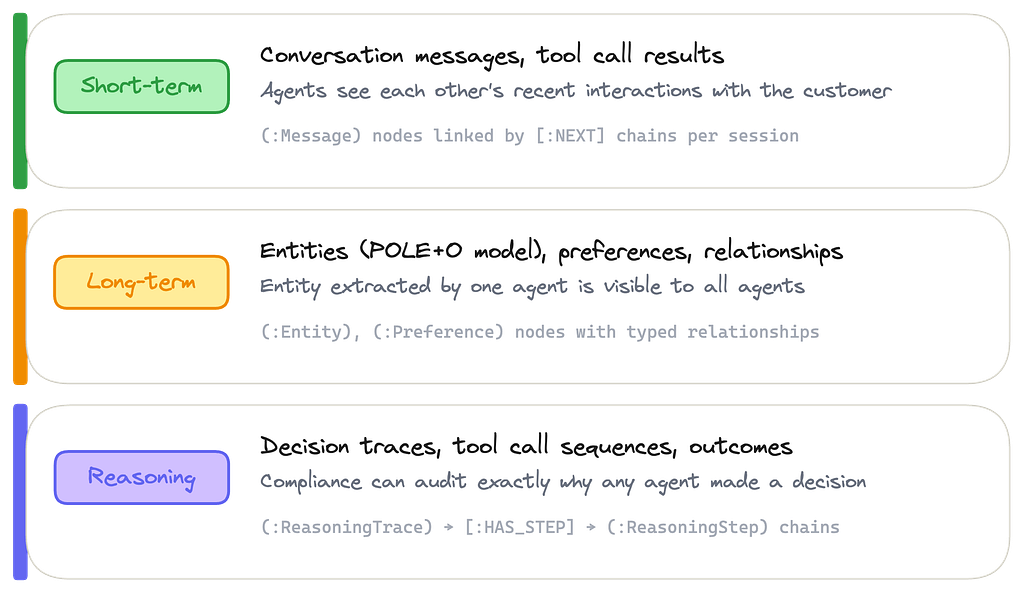
Short-term — Conversation messages and tool call results. Every agent’s interactions are stored as (:Message) nodes linked by [:NEXT] chains per session. When one agent talks to a customer, every other agent can see what was said.
Long-term — Entities extracted using the POLE+O model (Person, Organization, Location, Event, Object), user preferences, and typed relationships between entities. When the KYC agent extracts “John Mercer” as a :Person who WORKS_AT “Meridian Capital,” that knowledge is immediately available to every agent in the system.
Reasoning — Decision traces, tool call sequences, and outcomes. Stored as (:ReasoningTrace) → [:HAS_STEP] → (:ReasoningStep) chains with provenance links back to the entities and messages that informed each decision. This is what makes agent behavior explainable and auditable.
Why reasoning memory matters: Most agent memory systems handle conversations and entities. But without structured reasoning traces, you can’t answer the question that regulators always ask: why did the agent make this decision? Reasoning memory stored as first-class graph nodes — with provenance links to the entities and messages that informed the decision — is what turns an AI system from a black box into an auditable one.
What graph memory gives you
When your agents share a Neo4j context graph, you get capabilities that aren’t possible with flat memory stores or vector-only systems.
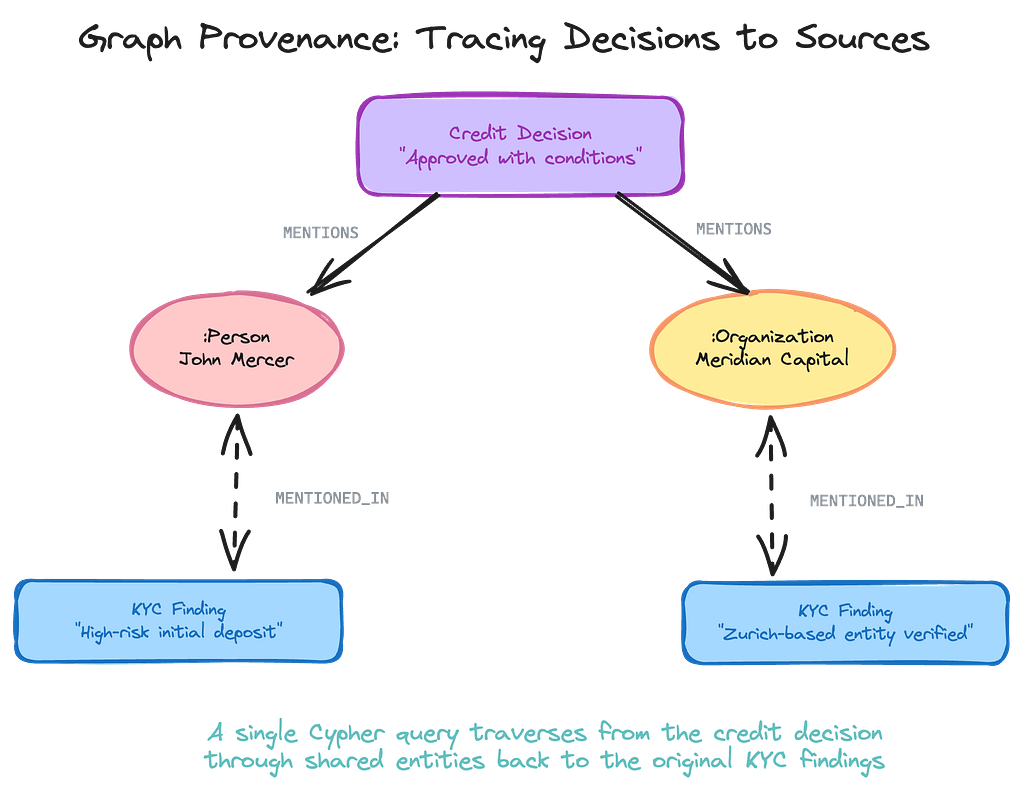
- Cross-agent entity linking. An entity extracted by one agent is automatically visible to every other agent. No integration work, no sync jobs — they share the graph.
- Graph-connected provenance. Every decision traces back through the entities it references to the original findings. A single Cypher query reconstructs the full audit trail.
- Deterministic retrieval. Graph traversals return exact connections, not probabilistic similarity matches. When compliance needs to know what informed a decision, the answer is definitive.
- Queryable memory. Because everything is stored in Neo4j, you can run arbitrary Cypher queries against the full memory of all your agents — analytics, reporting, pattern detection across the entire context graph.
- Reasoning traces as first-class citizens. Decision traces aren’t buried in log files. They’re graph nodes with typed relationships to the entities and messages that informed them.
- Strong security guarantees: The database access control mechanisms can protect sensitive data and provide agents only with the minimal permissions they need to do their work, with escalation layers to a human as needed.
Try it yourself
The complete example is available on GitHub:
git clone https://github.com/neo4j-labs/agent-memory.git
cd agent-memory/examples/aws-financial-services-advisor
pip install neo4j-agent-memory[aws,strands] python-dotenv
# Configure .env with Neo4j Aura + AWS credentials
python main.py
You’ll need a Neo4j Aura instance (the free tier works) and an AWS account with Bedrock model access. The full setup takes about 30 minutes.
For a deeper technical walkthrough of every file in the example, see the step-by-step tutorial in the Neo4j Agent Memory documentation.
We’re just getting started. If you build something with neo4j-agent-memory, we want to see it — share on the community forum or open a PR on GitHub. The context graph grows with every contribution — and so does ours.
Resources
- Documentation
- AWS Strands memory integration guide
- AWS Strands / AWS Agent Core Neo4j Integrations
- Strands agent tutorial
- Example repository
- Community forum
When Your Agents Share a Brain: Building Multi-Agent Memory with Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI

Digital twins that learn: connected asset intelligence with Neo4j and Databricks

Building retail assistants customers can trust with Databricks and Neo4j