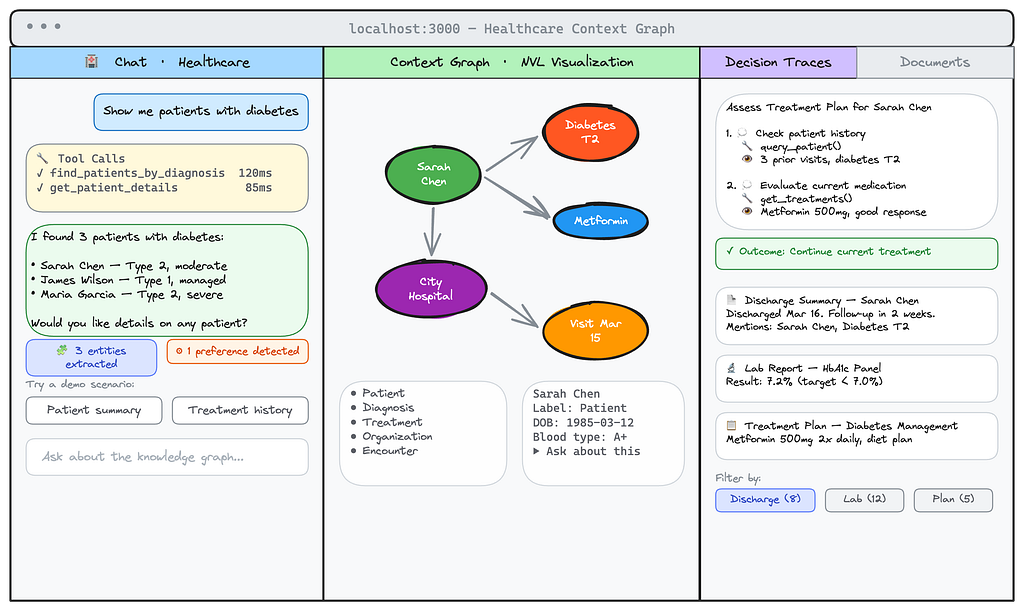
Context graphs: Why AI agents need three types of memory

Chief Scientist, Neo4j
8 min read
The transition from simple chatbots to truly autonomous systems represents the next significant evolutionary step in the field. We’re moving beyond the era of the “AI savant”—models capable of (sometimes) impressive intellectual feats within the confines of a chat interface. Those chatbots were uncoupled from the operational reality of the tasks they describe. While they seem knowledgeable in conversation, they remain systemically isolated.
Agentic AI systems change that dynamic. Agents need to be able to navigate the practicalities of functional execution rather than simply discussing them. Importantly, if we’re going to entrust operational responsibilities to agents, they need to be dependable, even while non-deterministic models are at the heart of their processing loop.
To solve real problems reliably on a continuous, improving basis, agents need structured memory. They need to deal with facts, recency, and the fallout from decision-making, much as humans do. With the advent of context graphs, we have moved in a positive direction.
Many AI agents today are unreliable because their memory, if it even exists, consists of a simple conversation buffer and static knowledge base. They read your goal, plan their actions, look up facts from one store, and run a similarity search in another. After many more loops, they forget the original plan or the reasoning behind their decisions and end up doing something different from the original goal.
Context graphs solve this problem. They provide a knowledge layer that allows agents to reason and act in an accurate, explainable, and governable manner over the long haul for production systems.
What is a context graph?
Foundation Capital identified context graphs as a significant architectural trend in the infrastructure of agentic systems. They found that context graphs serve as sophisticated memory for agents—memory that is both smarter and more capable than simple logs. A context graph works by capturing decision traces and linking them directly to the entities in your data, ensuring that your agent’s reasoning is grounded in the actual state of the world.
Many AI researchers tend to bundle “context” into a single category related to decision-making, but as data practitioners we see a clear opportunity to refine and expand on the idea. Doing so allows us to construct a data architecture that provides a far more stable foundation for autonomous agents to operate within.
We envision context graphs as functionally aligned layers of agentic memory. This allows for simpler implementation and operations while improving the accuracy of the system. We propose a context graph (or agentic memory model) with three components: long-term memory for knowledge, short-term memory for conversation, and reasoning memory for decision traces.
Each type of memory is tailored to a different temporal and functional requirement, but they’re also interconnected. They can be used holistically, presenting a rich and timely world model that helps agents uphold dependability in production over the long haul.
Context graphs for agentic memory
A context graph connects three levels of memory:
- The foundation: Long-term memory for enterprise knowledge
- The middle: Short-term memory for conversation history
- The apex: Reasoning memory for decision traces
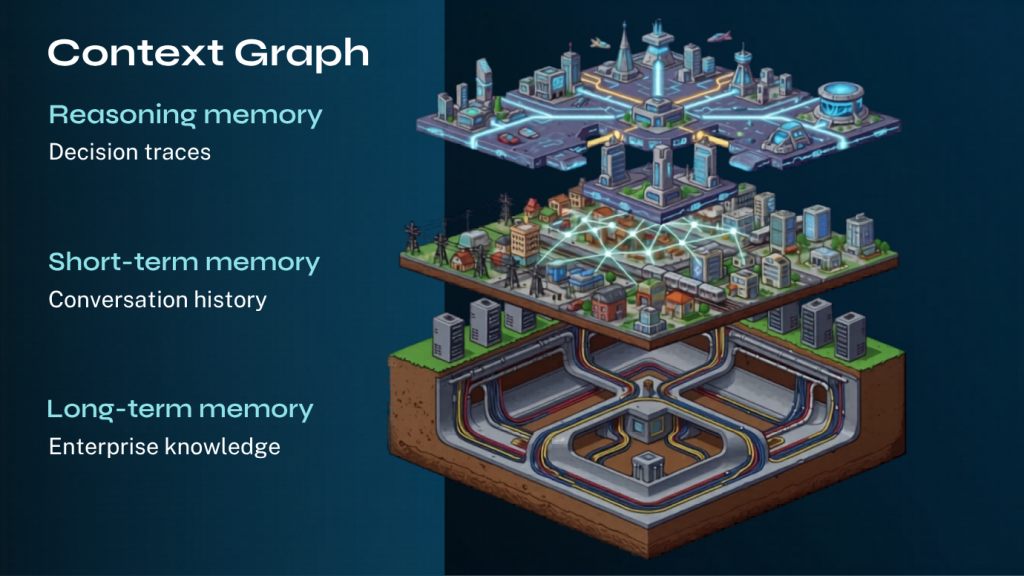
Our view of agentic memory is composable; each layer of memory connects to the others in a unified context graph. This “Sim City data model” allows for a highly flexible system in which an agent can query any or all graphs simultaneously, depending on its needs. Crucially, it enables us to scale and process each graph independently: storing one for rapid memory access, inspecting another through specific graph queries, or curating a third using graph algorithms.
Ultimately, the dependability of an autonomous agent over time is not merely a product of the model itself, but a direct reflection of the quality of this curated data infrastructure. Let’s take a closer look at each type of memory.
Long-term memory: Enterprise knowledge
At the base of the agent’s memory sits enterprise knowledge, made up of slow-moving facts—immutable truths that rarely require updating, such as a building’s geographic location or a nation’s capital. This is the agent’s long-term memory.
Many enterprises today have knowledge graphs. They tend to be high-fidelity and highly curated (by both experts and algorithms). While knowledge graphs are rich and mutable, the velocity of change in the data tends to be low. Good examples of knowledge graphs include bioinformatics that stores interactions between molecules and receptors, a digital twin of public transport systems that shows which rail lines might be delayed or a bridge closed for the day, and more. Both are rich and dynamic, but with relatively few updates per second.
The value is that knowledge graphs provide ground truth for your business domain. They augment and correct for the lossy training of the agent’s model by providing hard, curated facts about the domain to close gaps and help prevent hallucinations.
Short-term memory: Conversation history
In the middle sits the conversation history, which handles more volatile information, such as what the user asked, what the agent is working on, what it’s already done in previous sessions, or what knowledge it needs to accomplish the current task. This is the agent’s short-term memory.
Short-term memory captures the agent’s state, as well as conversation, session, and message history. It bridges the gap between general knowledge and specific action. The agent gains the context it needs to take actions, while avoiding context drift issues such as forgetting which tasks it’s already done or which related knowledge it used. Knowing a truck’s meaning is useless unless the agent knows what was discussed about it and where to find it, so it can make a useful decision. With a durable conversation history, an agent can reference its own state and messages and easily navigate to relevant knowledge. It also provides a durable context for multi-agent orchestration, enabling agents to understand what other agents are working on in real time.
Reasoning memory: Decision traces
Finally, at the top, we have the decision traces, or line-of-reasoning data, which capture the agent’s internal decision-making processes and its historical decision records. This three-tiered graph architecture isn’t just “more data.” It’s the navigational structure that allows an agent to work autonomously. This is the agent’s decisioning memory.
The decision graph provides transparency and explainability for both humans and agents to audit. The reasoning memory supports many concurrent decision-making processes, but once a decision is made, the decision, along with the reasons and tool uses, is stored as a decision trace. Through self-referential activity, the agent can tie together knowledge and conversations with its own decision traces to make good decisions and improve its decision-making capabilities over time.
Graphs, in context
You might reasonably ask if we have encountered this before in the form of graph databases. The answer is yes, with a caveat. All three graph layers in this architecture can be implemented with a graph database and easily queried with a query language like Cypher or GQL.
However, a movement towards APIs, like Neo4j Agent Memory, that both encapsulate database queries and offer useful functionality like entity resolution on behalf of the agent, while keeping the underlying data well-curated. Agentic memory APIs allow an agent to simply “remember” a fact (including entities and their associations), which is then mapped by underlying tools (such as entity resolvers) to the appropriate records in the appropriate tiers of the graph.
How to build a context graph
Neo4j Agent Memory makes it easy to build context graphs. It’s an open-source library that runs on top of any Neo4j instance and packages all three types of memory in the context graph.
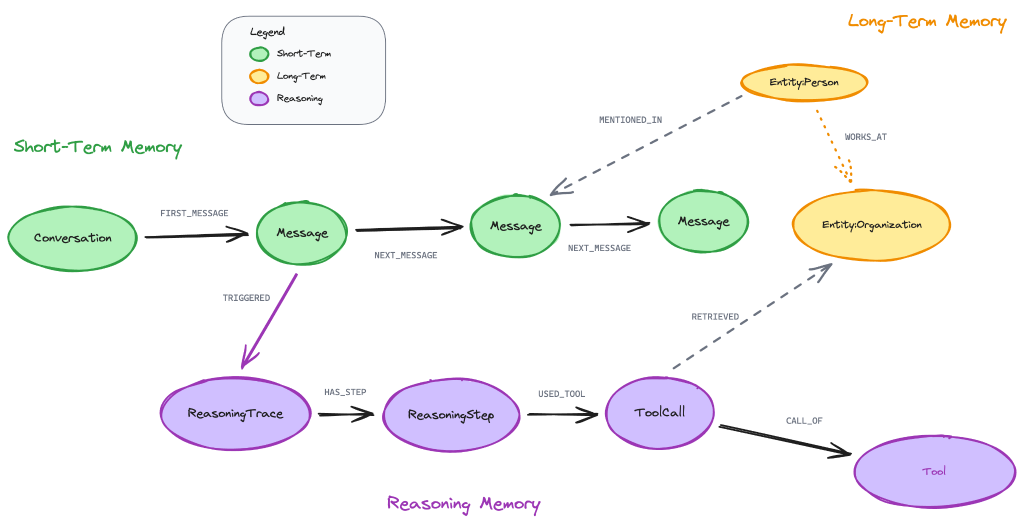
Neo4j Agent Memory handles everything from modeling the graph schema, writing Cypher queries, and managing entity resolution to adding connections, summaries, and metadata, while keeping the underlying data clean and well-curated. It also plugs into existing agent frameworks like LangChain, Pydantic AI, LlamaIndex, CrewAI, and OpenAI Agents, so teams can add a context graph to an agent they’ve already built without rewriting the architecture.
An agent can simply call these memory tools via MCP or API to store something in its memory. Or you can also use create-context-graph to easily build a full-stack agentic AI application from scratch—including a backend with a configured agent, a frontend with graph visualization, and a context graph of your domain.
Get started with context graphs
Autonomous, goal-oriented agents are the future of information systems. Building autonomous agents to be dependable is a challenge, but it can be met and exceeded by supporting your agents with the right platform.
Context graphs give your agents a durable understanding of all your knowledge, conversations, and decisions. The three-tiered model works well because it allows agents to pick the right level(s) of data they need, while the connections in the graphs provide the context necessary for dependable agentic processing.
Share Article



Explore
Related Articles



Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report