Describing a property graph data model

Senior Staff Software Engineer, Neo4j
11 min read

Problem statement
Almost all client applications we build at Neo4j are interested in knowing what’s in the database. Not the actual data, but the shape of it, its schema.
Since we have no standard way of describing it yet, it leads to a situation where each application has its own representation of what the schema looks like.
Some tools store a schema in memory, some store it in light persistence places (like web browser local storage) and some store it in Neo4j itself. Different approaches exist as well for inferring a schema: Some tools do sampling, and some do full-store scans.
For most applications that are not just based on explorative work, one thing holds true: You can’t have no schema. There will always be a schema.
Either your database provides a schema or your application assumes and enforces it, either through object mapping such as GraphQL schemata or OGMs or implicit assumptions: Your data model implies a schema.
Explorations
When starting this project we gathered all stakeholders within Neo4j to take inventory of:
- how they infer the existing data model
- in what format they store it
- how they store it
- what problems they have run into
- what they would change
What became clear early in the project was that we need to be able to serialize the data model so that it can be transported and persisted. This would also create the possibility for applications to hand off model instances between each other for tighter integrations and a better user experience (more on that further down).
The goal
The goal of this project is to validate the prospect of a JSON based data model. Therefore we built a plugin (procedure) that introspects the database it is called on and creates JSON response that validates against a JSON schema. Finding or creating the perfect inferring algorithm was a non-goal of the project.
Note: This post is a great example of how hard naming can be: We have a JSON-Schema that allows tooling to validate concrete instances of the content of a database scheme (represented as JSON). The latter is referred to as data model in this post.
The schema
The schema is currently published at https://unpkg.com/@neo4j/graph-json-schema/json-schema.json and can be used as a $schema reference both for validating and when authoring a schema by hand.
The JSON schema is based on the idea to separate tokens (node labels and relationship types) and concrete instances of nodes and relationships model elements (object types). Think like classes and concrete object instances.
This approach basically serves multiple purposes already: Having an easy-to-read catalog of all labels and types inside a database instance and a normalized combination thereof.
For the movie graph contained in Neo4j the set of tokens looks like this:
{
"graphSchemaRepresentation": {
"graphSchema": {
"nodeLabels": [
{ "$id": "nl:Person", "token": "Person" },
{ "$id": "nl:Actor", "token": "Actor" },
{ "$id": "nl:Director", "token": "Director" },
{ "$id": "nl:Movie", "token": "Movie" }
],
"relationshipTypes": [
{ "$id": "rt:ACTED_IN", "token": "ACTED_IN" },
{ "$id": "rt:DIRECTED", "token": "DIRECTED" }
],
"nodeObjectTypes": [],
"relationshipObjectTypes": []
}
}
}
The following snipped show — based on the previous tokens — two concrete node object types and one relationship (the actual movie graph is bigger and the content has been edited for brevity)
{
"graphSchemaRepresentation": {
"graphSchema": {
"nodeLabels": [],
"relationshipTypes": [],
"nodeObjectTypes": [
{
"$id": "n:Person",
"labels": [{ "$ref": "#nl:Person" }],
"properties": [
{
"token": "born",
"type": { "type": "integer" },
"nullable": false
},
{ "token": "name", "type": { "type": "string" }, "nullable": false }
]
},
{
"$id": "n:Movie",
"labels": [{ "$ref": "#nl:Movie" }],
"properties": [
{
"token": "title",
"type": { "type": "string" },
"nullable": false
},
{
"token": "release",
"type": { "type": "date" },
"nullable": false
}
]
}
],
"relationshipObjectTypes": [
{
"$id": "r:ACTED_IN",
"type": { "$ref": "#rt:ACTED_IN" },
"from": { "$ref": "#n:Actor:Person" },
"to": { "$ref": "#n:Movie" },
"properties": [
{
"token": "roles",
"type": { "type": "array", "items": { "type": "string" } },
"nullable": false
}
]
}
]
}
}
}
A graphy visualization of the JSON schema instance for the movie graphs data model looks like this:
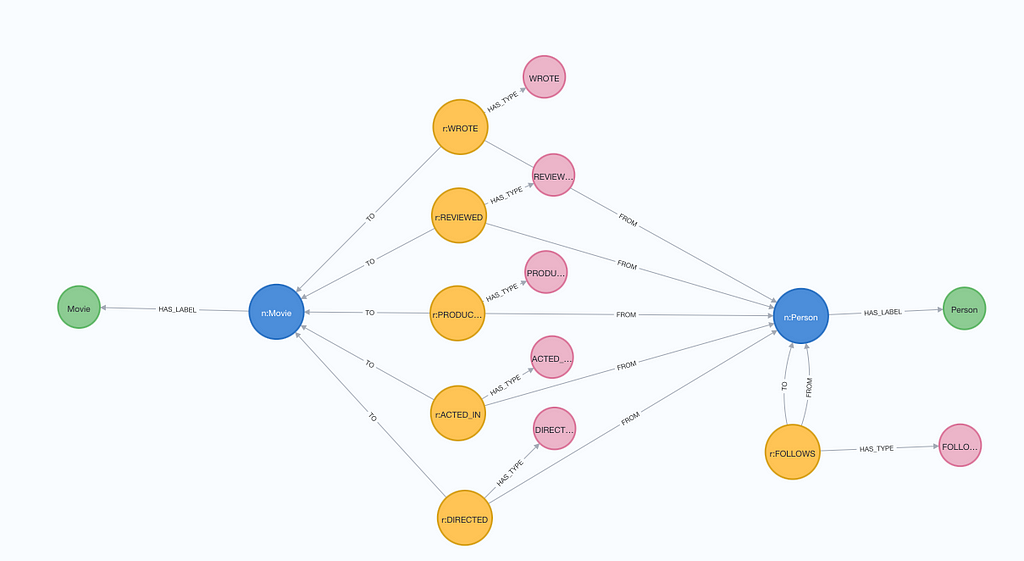
The algorithm
The proof of concept uses an algorithm similar to what Neo4j offers in Neo4j-GraphQL:
- Use official kernel APIS to retrieve labels and relationship types in use
- Use existing db.schema.nodeTypeProperties for retrieving all properties for all combinations of labels. Group by sorted combinations of labels to create node object instances
- Use existing db.schema.relTypeProperties for retrieving all relationship properties plus a full store scan for evaluating the correct start and end node of the existing types. Group by type and the target of the relationship to create relationship instances.
This step does sampling by default and compares only 100 concrete relationships per type and property by default (concrete relationship here means (n:LabelA) -[:TYPE]-> (b:Label2) and not only :TYPE )
The set-based approach with grouping on both relationship type and the target is superior to what is currently available as db.schema.visualization as relationships with the same type won’t be merged into each other.
The schema makes heavy use of references and thus requires all items to have IDs. In the printed examples above the IDs have been derived from the tokens and can be easily shared and remembered. The algorithm can however also generate ids for you. It will use Time-Sorted Unique Identifiers (TSID) for it. These are readable and sort nicely. The IDs in the schema have no other meaning than being identifiers. The value is derived from the tokens.
All tokens that require a quotation and/or sanitization when used in Cypher statements will be quoted and sanitized by default. So everything in the scheme is safe to build Cypher statements with (in case you are interested in that topic, you might want to have a look at the schema name support of the Cypher-DSL).
Our proof of concept can also visualize the data model itself, without materializing the JSON schema as such:
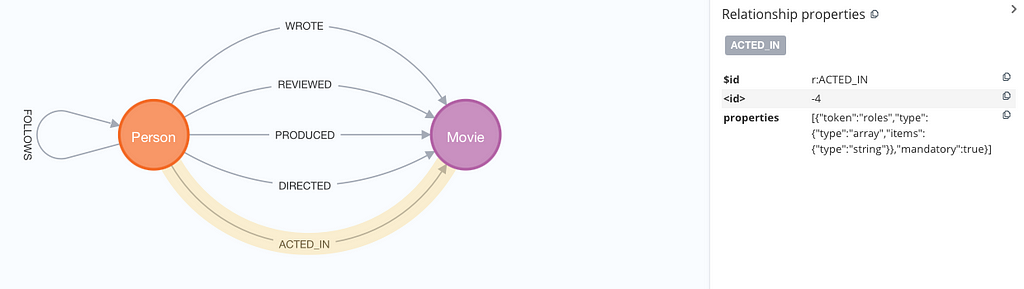
Use cases
Neo4j workspace
All of the workspace’s sub-applications: Import, Query, and Explore will use the graph schema for different purposes.
Import
The Neo4j importer tool is a place where users can create their data model and map/import data from CSV files to fit the model. In this case, the model would be stored in the schema format for users to be able to revisit and diff existing models. For incremental imports, inferring the existing schema in the database to create the import model/mapping would save time.
Query
In Query, there’s a sidebar that informs the user on what labels, relationship types and property keys exist in the database that’s connected. This reassures the user that they’re connected to the expected database, and also access to execute queries with a simple mouse click.
Explore
The Explore feature of Workspace relies on knowing the database schema for assisting the user when creating perspectives and scenes and authoring search queries. It is adding styling metadata on top of the core graph model.
Cypher editor
The Cypher editor can provide better and faster smart-sense capabilities based on the preloaded schema without going back and forth to the database. Such capabilities include for example autocompletion (as used to) for labels and types, but also properties and while writing DML statements hints when mandatory properties are missing.
Neo4j GraphQL introspector
As the algorithm used in the project is mostly identical to what is in the Neo4j GraphQL introspector today, Neo4j GraphQL could seamlessly switch to something that is maintained in the core product itself, not suffering from network latencies, potentially using faster kernel APIs without sacrificing any of its capabilities our users like.
Neo4j-OGM
Neo4j-OGM for Java is a Graph-Object-Mapping framework. It basically defines a schema for Neo4j through annotated Java classes. Those Java classes are mostly written by hand or sometimes generated by modeling tools. The proposed schema can be used to steer source generators for Java such as JavaPoet to generate those classes, and thus, turn responsibilities the other way around. While often generated sources are not always to the liking or needs of power users, it would offer a huge benefit to the 80% cohort who just wants their graph mapped to a class graph reassembling the existing database’s shape.
General mapper generation
All official language drivers, Neo4j-OGM and Spring Data Neo4j support pluggable mapping mechanisms from records to objects in the corresponding language. Such a mapper can be generated in its simplest form when the shape of a record or at least the shape of nodes in such a record is known. While the code generated with the help of a schema is not sophisticated code at all (it won’t be a general OGM approach that will take care of recreating the local graph based on relationships etc), it will be helpful nevertheless as it takes away from users. It can also be faster than solutions based on dynamically introspecting fields of classes client slide.
Try out the proof-of-concepts procedure
The plugin generating the JSON instance is called “Neo4j Schema Introspector” and its source code is available on GitHub: neo4j/graph-schema-introspector.
In case you just want to run it inside your Neo4j installation, you can grab the early access release from the release pages. Look out for the single jar-file named graph-schema-introspector-1.0.0-SNAPSHOT.jar.
If you are familiar with Java development and have Java 17 installed, you can follow the introductions in the README to build it yourself.
Download that file to a location you can find and copy it like this to your Neo4j installation:
cp ~/Downloads/graph-schema-introspector-1.0.0-SNAPSHOT.jar
~/Applications/Neo4j/neo4j-enterprise-5.5.0/plugins
Your paths as well as the version and edition of Neo4j might vary, but the plugin will work with both community and enterprise editions in the range of the 5.x Neo4j series. After you copied the file you need to restart Neo4j.
If you are doing your experiments in Docker, follow this flow:
mkdir -p $HOME/neo4j/plugins
cp ~/Downloads/graph-schema-introspector-1.0.0-SNAPSHOT.jar $HOME/neo4j/plugins
docker run
--publish=7474:7474 --publish=7687:7687
--volume=$HOME/neo4j/plugins:/plugins
neo4j:5.5.0
The introspector can be run like this:
Pretty printing the schema as JSON
CALL experimental.introspect.asJson({prettyPrint: true})
Visualizing the schema (only in browser)
CALL experimental.introspect.asGraph({})
Visualizing the schema analog to existing visualization (only in browser)
CALL experimental.introspect.asGraph({flat:true})
There are more options for those procedures, please refer to the README for them.
Working with the JSON Schema
Utility library
Since JSON is a serialized format, there can’t be any hot reference paths inside it (as shown in the examples above) but references by strings
($ref -> $id).
This makes it hard to work with programmatically and to accommodate that we’ve started to build a utility library graph-schema-json-js-utils in TypeScript.
With this utility library, you can seamlessly go from JSON to a JS graph (i.e. the $refs are connected) and back to JSON.
See the README for example code or install via npm install @neo4j/graph-schema-utils .
To validate a graph schema in the JSON format, the utility library also comes with a validation function. This makes it easy to be able to trust input before you start using it.
Feedback
We would appreciate your feedback on both the JSON schema and how the data model materializes as well as on the introspector algorithm and the utilities around it.
You can do this as comments under this post and of course as a ticket on https://github.com/neo4j/graph-schema-introspector/issues.
Thanks to my colleague Oskar Hane for working together with me on this topic and story.
Describing a Property Graph Data Model was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


