
Exploring the Updated Neo4j-Java-Driver: Finding Trees in the Forest

Senior Staff Software Engineer, Neo4j
5 min read

How to turn a list of flat elements into a hierarchy with Java, Cypher, and the updated Neo4j driver for Java

Richard Macaskill wrote about The New Steer for the Neo4j-Drivers a while back, and I would like to pick up on that topic, focussing on the Java Driver.
I would like to take the post from my friend Lukas Eder from Data Geekery as an inspiration.
Creating the Test Data
We are dealing with a parent/child relationship as it occurs in a hierarchical file system:
create (:Path {name: 'child'}) -[:HAS_PARENT] ->(:Path {name: 'parent'})
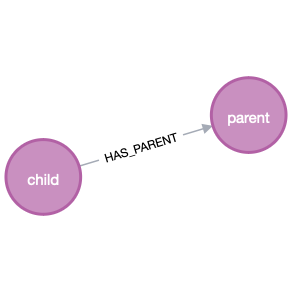
Traversing a path with Java and turning the result into a Neo4j graph looks like this when using the new executableQuery API present in the 5.7 version of the Neo4j-Java-Driver:
var paths = Files.walk(root)
.map(p -> Map.of(
"parent_id", p.getParent().toString(),
"id", p.toString(),
"name", p.getFileName().toString()))
.toList();
driver
// creates an executable query
.executableQuery("MATCH (n) DETACH DELETE n")
// and executes it. There is no need to consume or close the result
.execute();
// Using an eager result
var result = driver
// Again, creating the executable query
.executableQuery("""
UNWIND $paths AS path WITH path
MERGE (c:Path {id: path.id, name: path.name})
MERGE (p:Path {id: path.parent_id})
MERGE (c)-[r:HAS_PARENT]->(p)
RETURN c, r, p
""")
// but enriching it with parameters
.withParameters(Map.of("paths", paths))
.execute();
// Gives you access to the result summary, including counters and more,
// no need to consume something upfront
var counters = result.summary().counters();
System.out.println(
counters.nodesCreated() + " nodes and " +
counters.relationshipsCreated() + " relationships have been created");
// The returned records are already materialized, iterating them multiple
// times is safe and does not involve multiple round trips
// the summaryStatistics here is a Java Streams API, not Neo4j Driver
var c1 = result.records().stream()
.mapToInt(r -> r.get("c").get("name").asString().length())
.summaryStatistics().getMax();
var c2 = result.records().stream()
.mapToInt(r -> r.get("p").get("name").asString().length())
.summaryStatistics().getMax();
var format = "| %1$-" + c1 + "s | %2$-" + c2 + "s |%n";
System.out.printf((format), "Name", "Parent");
System.out.println("|" + "-".repeat(c1 + 2) + "|" + "-".repeat(c2 + 2) + "|");
result.records().forEach(r -> {
var c = r.get("c").asNode();
var p = r.get("p").asNode();
System.out.printf(format, c.get("name").asString(), p.get("name").asString());
});
}
The above content demonstrates a couple of different topics already:
- There is no need to think about transactional functions or retries
- The executableQuery method creates a query that might or might not be enriched with parameters prior to execution
- When executed without a Collector, there is no need to consume the result further
- The eager result however can be used as many times as necessary
- The result summaries are always available, no further action is necessary
This API is an excellent choice for scripts, simple Java programs (or any Java program that does not need to hook into external transaction boundaries, such as Spring or Quarkus transactions).
The program above gives me for the project in which I created the demo for this post the following output:
22 nodes and 21 relationships have been created
| Name | Parent |
|--------------------------|--------------------|
| testride52 | null |
| pom.xml | testride52 |
| .idea | testride52 |
| encodings.xml | .idea |
| uiDesigner.xml | .idea |
| jarRepositories.xml | .idea |
| inspectionProfiles | .idea |
| Project_Default.xml | inspectionProfiles |
| .gitignore | .idea |
| workspace.xml | .idea |
| misc.xml | .idea |
| compiler.xml | .idea |
| src | testride52 |
| test | src |
| java | test |
| main | src |
| resources | main |
| java | main |
| ac | java |
| simons | ac |
| ExecuteQueryApiDemo.java | simons |
The most beautiful part of that API however is that it has native support for Java’s fantastic Collectors API. In the first example, we used it with a built-in Java collector.
For example, retrieve all the names as a list:
List<String> names = driver
.executableQuery("MATCH (n:Path) RETURN n.name AS name")
.execute(
Collectors.mapping(r -> r.get("name").asString(),
Collectors.toList())
);
But honestly, for this use case, you can use the eager result and a simple mapping function on the list of records.
The collectors API is relevant for all client-side grouping and counting tasks. Jump back to the beginning and have a look at Lukas’ post. Notice the several suggestion to turn a hierarchy of paths into a hierarchy of Java objects.
Can we follow them? First, with more or less pure Cypher, such as Lukas did with SQL? Of course, we can rather easily query the graph and return a tree as JSON:
static void printWithApocAndComplexStatement(Path root, Driver driver) {
var result = driver.executableQuery("""
MATCH (r:Path {name: $nameOfRoot})
MATCH (l:Path) WHERE NOT (EXISTS {MATCH (l)<-[:HAS_PARENT]-(:Path)})
MATCH path=(r) <-[:HAS_PARENT*]-(l)
WITH collect(path) AS paths
CALL apoc.convert.toTree(paths, false, {nodes: {Path: ['-id']}}) YIELD value
RETURN apoc.convert.toJson(value) AS result
""")
.withParameters(Map.of("nameOfRoot", root.getFileName().toString()))
.execute();
System.out.println(result.records().get(0).get("result").asString());
}
However, that requires us to have APOC installed in our database. We can do much better with the new executableQuery API. Given this record:
record File(
@JsonIgnore String id,
String name,
@JsonInclude(JsonInclude.Include.NON_EMPTY) List<File> children) {
}
and verbatim taking the intoHierarchy Collector from the jOOQ post, we can just do this:
static void intoHierachyAndPrint(Driver driver) throws IOException {
var result = driver
.executableQuery("""
MATCH (p:Path) <-[:HAS_PARENT]-(c:Path)
RETURN
elementId(c) AS id,
elementId(p) AS parentId,
c.name AS name
""")
// This will take care of iterating a non-eager-result-set
// for us plus all the added benefits of using retries internally
// It won't allow us to take the non-eager-result set out of
// transaction scope which is an excellent thing
.execute(intoHierarchy(
r -> r.get("id").asString(),
r -> r.get("parentId").asString(),
r -> new File(r.get("id").asString(), r.get("name").asString(), new ArrayList<>()),
(p, c) -> p.children().add(c)
));
new ObjectMapper()
.writerWithDefaultPrettyPrinter()
.writeValue(System.out, result);
}
The result of that method — formatted as JSON — looks like this:
[ {
"name" : "testride52",
"children" : [ {
"name" : ".idea",
"children" : [ {
"name" : ".gitignore"
}, {
"name" : "inspectionProfiles",
"children" : [ {
"name" : "Project_Default.xml"
} ]
}, {
"name" : "jarRepositories.xml"
}, {
"name" : "uiDesigner.xml"
}, {
"name" : "encodings.xml"
}, {
"name" : "compiler.xml"
}, {
"name" : "misc.xml"
}, {
"name" : "workspace.xml"
} ]
}, {
"name" : "src",
"children" : [ {
"name" : "main",
"children" : [ {
"name" : "java",
"children" : [ {
"name" : "ac",
"children" : [ {
"name" : "simons",
"children" : [ {
"name" : "ExecuteQueryApiDemo.java"
} ]
} ]
} ]
}, {
"name" : "resources"
} ]
}, {
"name" : "test",
"children" : [ {
"name" : "java"
} ]
} ]
}, {
"name" : "pom.xml"
} ]
} ]
The full source of the example is available as a GitHub Gist, directly runnable via JBang.
Happy coding!
Exploring the Updated Neo4j-Java-Driver — Finding Trees in the Forest was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English




