
Fetching Large Amount of Data Using the Neo4j Reactive Driver: The Bloom Case

Software Engineer, Neo4j
6 min read
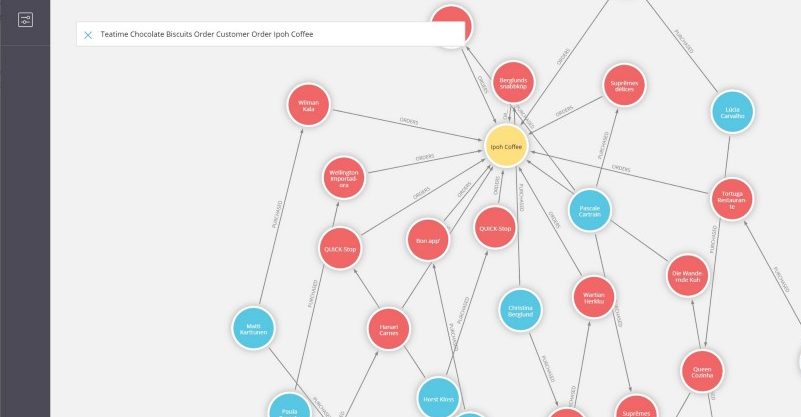
Bloom is a graph exploration tool which displays data in graph format. It’s a Javascript application (React.js based) and uses the Neo4j Javascript driver in order to interact with a Neo4j database.
The users are able to search for graph patterns using a generated vocabulary by the components of their databases (labels, relationships, properties or values) or create their own custom queries. They, also, have access to a very large amount of graph patterns which can lead to a huge amount of results.
The complexity of the queries and the size of the available data in combination with the limitation of the client resources requires restrictions on the size of the response and the number of the displayed nodes. So fetching results has always been a challenge for Bloom.
For that reason, Bloom can display a range between 100 to 10,000 unique nodes and their relationships. The size of a Cypher query response is limited to 10,000 records (rows), as well.
The question is how large the response should be in order to get the maximum available number of unique nodes in a very large space of results.
For example, the user searches for Person — Movie which can be translated in Cypher to MATCH (n:Person)-[r]-(m:Movie) RETURN n, r, m. The selected maximum number of unique nodes, from the Bloom settings, is 10000.
In the below image you can see a visual representation of the response. Each column represents a record. Each unique node has a unique color. The multiple relationship types between a Person and the Movie (for example, a Person can be an ACTOR in a Movie and the same Person can be the PRODUCER of the same Movie) can create many duplicates for the nodes.
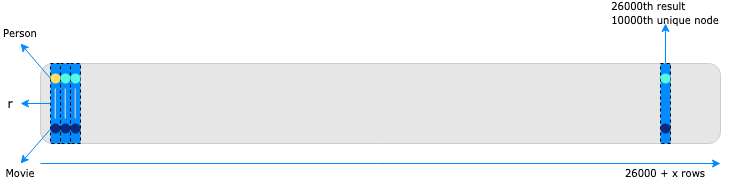
The number of the records to be parsed, in order to get the specified number of unique nodes is not a priori known by the response (if you don’t collect DISTINCT lists), as many records can include duplicates of the same nodes.
After filtering all the records, at the example query, there is a need to fetch 26000 records in order to get the ideal number of 10000 unique nodes. The problem comes up when the size of the records is too large to be filtered at once by the client (for example 100K rows), or even when the server has to parse a huge amount of records which may not be needed. At the same time Bloom needs a common way to fetch results for the pattern search and the custom Cypher queries created by the users.
As mentioned above, you are not able to know a priori which is the ‘right’ limit in order to get exactly 10000 unique nodes (26K rows in this example) and set it as LIMIT in your query. Even if you knew that, a large LIMIT could still cause performance issues at the client.
The question is how can you set the number of the records in your query in order to get a size of response which can be handled by the client and at the same time calculate efficiently the maximum number of unique nodes.
Solution 1: Chunk Approach
At Bloom versions earlier than 1.6.0 we developed a pagination method using SKIP/LIMIT combination. The same method is used in the Bloom version 1.6.0 and later, as well, but only for the older 3.5.x Neo4j databases.
Bloom divided the response in chunks using multiple queries until the desired number of unique nodes was reached or when all the records were consumed.
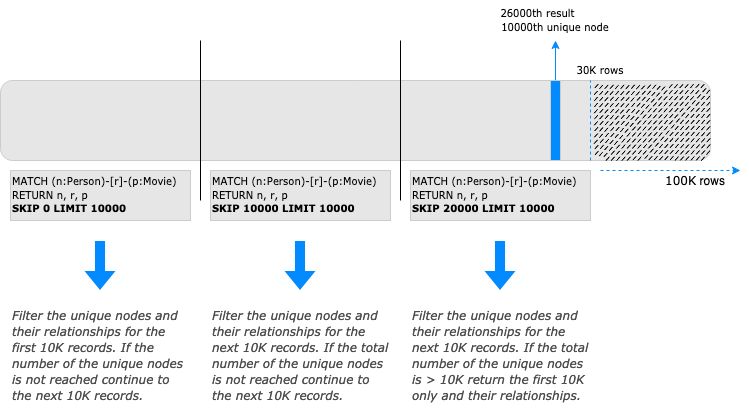
So, despite fetching all the rows that match the pattern of the Cypher query calling a simple transaction,
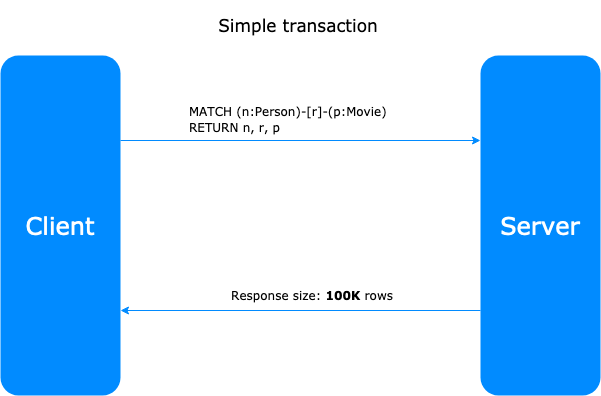
using the chunk approach we divide the response size calling different transactions with a specified SKIP and LIMIT.
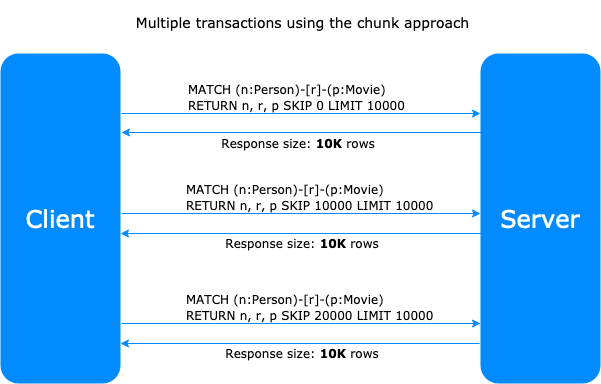
The Chunk Approach enables the client to manage the size of the response and calculate the maximum number of unique nodes efficiently, but the generation of multiple queries and the use of SKIP adds more complexity to the code and raises the execution time. And the server still needs to process the data to be skipped time and again.
Solution 2: Reactive Drivers
In version 4.0 Neo4j database’s reactive drivers were introduced. You can imagine them as a gate between the client and the server in which you control the flow of data and adjust it accordingly. The results return to the client as quickly as they are generated by the server. Reactive drivers are used in Bloom since the 1.6.0 version.
Bloom uses the Reactive API of the Neo4j Javascript driver (check out the Neo4j Javascript driver manual) which is an extension of ReactiveX, so it would be good to get familiarised with reactive programming and streams of data. A reactive session should be established, using rxSession(), in order to use reactive programming API provided by the neo4j driver.
The basic components of a reactive session are the Publisher, which emits data (records()), the Subscriber, which watches the flow of the data and the Processor which is between publisher and the subscriber and represents the state of values processing.
The basic operators we use are bufferCount(<buffer_size>) and takeUntil(<notifier>) by ReactiveX — RxJS (reactive extensions library for javascript). Using bufferCount(<buffer_size>) you can define the size of results you can accept each time.
Technically, the values of the stream of data are packed in arrays with a specified size at bufferCount(<buffer_size>). This procedure continues until the notifier defined at takeUntil(<notifier>) emits a value or when all the possible results are consumed by the server.
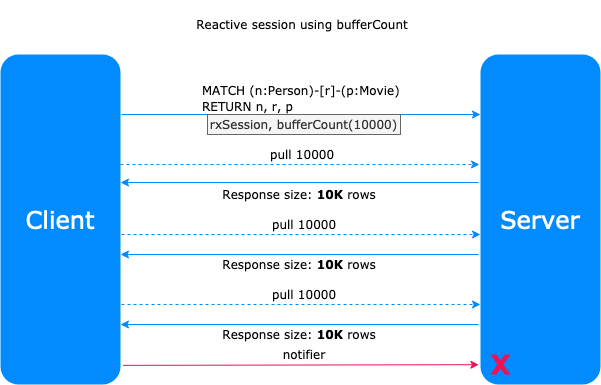
At the Subscriber level, when the desired number of unique nodes is reached, Bloom forces the notifier in order to emit a value and the transaction is completed declaratively. In case there are not more results the transaction is completed automatically.
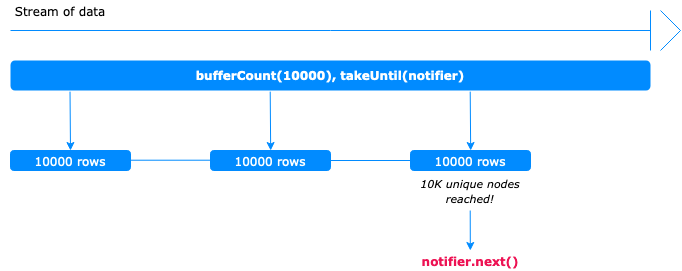
This technique can be used for any data processing you need in the client side using data size limitations.
In the example code below you can find a simple way for calculating unique nodes using reactive drivers (in combination with bufferSize() and takeUntil() operators), in the client side.
import neo4j from 'neo4j-driver'
import { Subject } from 'rxjs'
import { bufferCount, takeUntil } from 'rxjs/operators'
import { concat, flatten, uniqBy, slice } from 'lodash'
const MAXIMUM_UNIQUE_NODES = 10000
const BUFFER_SIZE = 10000
let uniqueNodes = []
const driver = neo4j.driver(
'neo4j://localhost',
neo4j.auth.basic('neo4j', 'password')
)
const query = `MATCH (n:Person)-->(p:Movie)
RETURN id(n) as idn, id(p) as idp`
const rxSession = driver.rxSession({ database: 'myDatabase' })
const notifier = new Subject()
const emitNotifier = () => {
notifier.next()
notifier.complete()
}
const filterUniqueNodes = records => {
const newNodes = records.map(d =>
[d.toObject()['idn'].toInt(), d.toObject()['idp'].toInt()])
// filter out the new unique nodes
const newUniqueNodes = uniqBy(flatten(newNodes))
// compare with the existing unique nodes and update the uniqueNodes
uniqueNodes = uniqBy(concat(newUniqueNodes, uniqueNodes))
if (uniqueNodes.length === MAXIMUM_UNIQUE_NODES){
emitNotifier()
}
if (uniqueNodes.length > MAXIMUM_UNIQUE_NODES) {
uniqueNodes = slice(uniqueNodes, 0, MAXIMUM_UNIQUE_NODES)
emitNotifier()
}
}
export const fetchResultsUsingReactiveDrivers = () =>
rxSession.readTransaction(tx => tx
.run(query, {})
.records()
.pipe(
bufferCount(BUFFER_SIZE),
takeUntil(notifier)
))
.subscribe({
next: records => {
// here you can add your own function for manipulating the incoming data
filterUniqueNodes(records)
},
complete: () => {
console.log('completed', uniqueNodes)
},
error: error => {
console.error(error)
}
})
Another advantage of the use of the reactive drivers is that gives the flexibility to the client to request data with specified size until they are totally consumed or terminate the transaction when needed.
There are, also, a plethora of operators provided by RxJS that you can use and customise your Neo4j transactions to the needs of your application.
For a more in-depth explanation of the reactive driver model provided by Neo4j 4.x drivers, Greg Woods presents the details in this session:
So we were really happy and impressed how well we could change our data-fetching code to be more efficient and making use of the reactive dataflow to only fetch as much as we needed without overloading client or server.
You can see the results of this work in our latest Neo4j Bloom release 1.7.0 which also brings a lot of other great features.
Fetching Large Amount of Data Using the Neo4j Reactive Driver: The Bloom Case was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
