How to get started with the Neo4j Graph Data Science Python client

Graph ML and GenAI Research, Neo4j
15 min read
Learn the basic syntax of the newly released Python client for Neo4j Graph Data Science
Data scientists like me love Python. It features a wide variety of machine learning and data science libraries that can help you get started on a data science project in minutes. It is not uncommon to use a variety of libraries in a data science workflow.
With the release of version 2.0 of Neo4j Graph Data Science (GDS), a supporting Python client has been introduced. The Python client for Neo4j Graph Data Science is designed to help you seamlessly integrate it into your data science workflow. Instead of having to write Cypher statements to execute graph algorithms, the Python client provides a simple surface that allows you to project and run graph algorithms using pure Python code.
Since the Python client for GDS is relatively new, there are not many examples out there yet. Therefore, I’ve decided to write this blog post to help you get started with the GDS Python client syntax and show some common usage patterns through a simple network analysis.
The Neo4j Graph Data Science Python client can be installed using the pip package installer.
pip install graphdatascience
An important thing to note is that the Python client is only guaranteed to work with GDS versions 2.0 and later. Therefore, if you have a previous version, I suggest you first upgrade Neo4j Graph Data Science to the latest version.
All the code for this blog post is available in a Jupyter Notebook on GitHub.
blogs/gds_python_intro.ipynb at master · tomasonjo/blogs
Neo4j environment setup
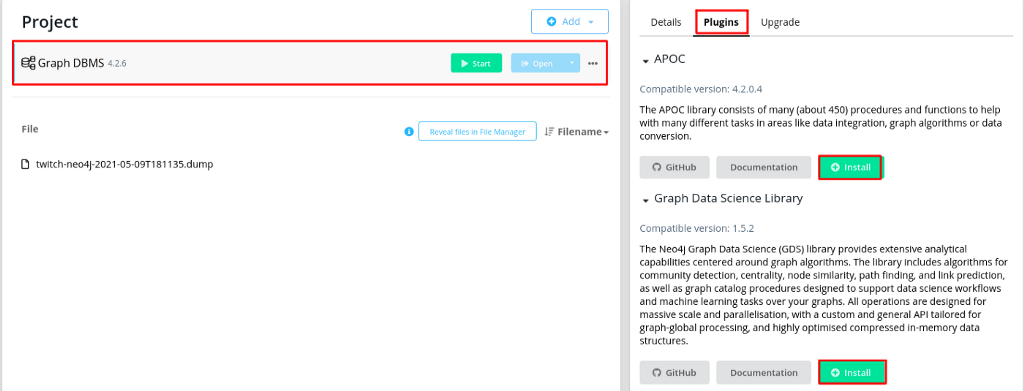
If you want to follow along with the code examples, you need to set up a Neo4j database. I suggest you use a blank project on Neo4j Sandbox for this simple demonstration, but you can also download a Neo4j Desktop application and set up a local database.
Neo4j Sandbox has GDS already installed. However, if you use Neo4j Desktop, you have to install Neo4j Graph Data Science manually.
Setting up the GDS Python client connection
We start by defining the client connection to the Neo4j database. If you have seen any of my previous blog posts that use the official Neo4j Python driver, you can see that the syntax is almost identical.
We have instantiated the connection to the Neo4j instance. If you are using Neo4j Enterprise, you might have multiple databases available in Neo4j. If we want to use any database other than the default one, we can select the required database using the set_database method.
gds.set_database("databaseName")
Lastly, we can verify that the connection is valid and the target Neo4j instance has GDS installed by using the gds.version() method.
print(gds.version())
The version() method should return the version of the installed GDS. If it returns anything else, make sure that you entered the correct credentials and Neo4j Graph Data Science is installed.
Executing Cypher statements
The Python client allows you to execute arbitrary Cypher statements using the run_cypher method. The method takes two parameters to input.

The first and mandatory parameter is the Cypher query you want to execute. The second method parameter is optional and can be used to provide any query parameters.
The run_cypher method can be used to import, transform, or fetch any data from the database. We will begin by populating the database with the Harry Potter network I created in one of my previous blog posts.
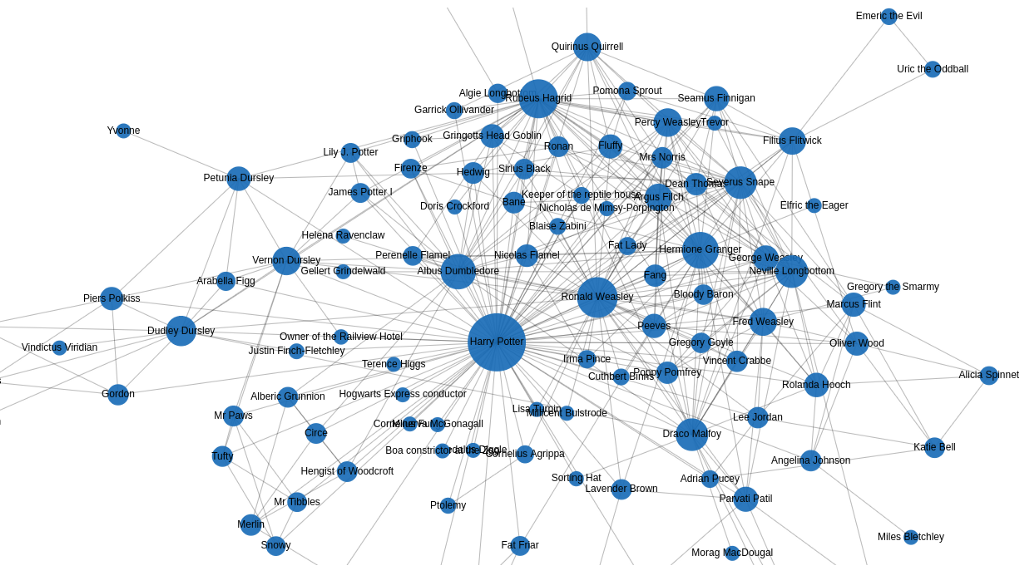
The network contains characters in the first book, and their interactions, which are represented as relationships. The CSV with the relationship is available on my GitHub, so we can use the LOAD CSV clause to retrieve the data from GitHub and store it in Neo4j.
The import script uses the run_cyphermethod to execute the Cypher statement used to import the Harry Potter network. To demonstrate how Cypher parameters work with the run_cyphermethod, I’ve attached the URL of the file as a Cypher parameter. While the Cypher query is represented as a string, the Cypher parameters are defined as a dictionary.
If you have done any data analysis in Python, you have probably used the Pandas library in your workflow. Therefore, when fetching data from a database using the run_cyphermethod, the method conveniently returns a populated Pandas DataFrame. Having the data available as a Pandas DataFrame makes it much easier to integrate the data from Neo4j into your analytical workflow and use it in combination with other libraries.
In this example, we will retrieve the degree (count of relationships) for each character in the network using the run_cypher method.
The degree_df.head() method will visualize the first five rows in your Jupyter Notebook.
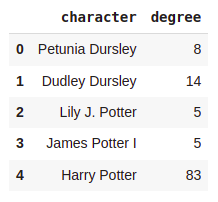
Since the data is available as a Pandas DataFrame, we can easily integrate it into our analytical workflow. For example, we can use the Seaborn library to visualize the node degree distribution.
Results
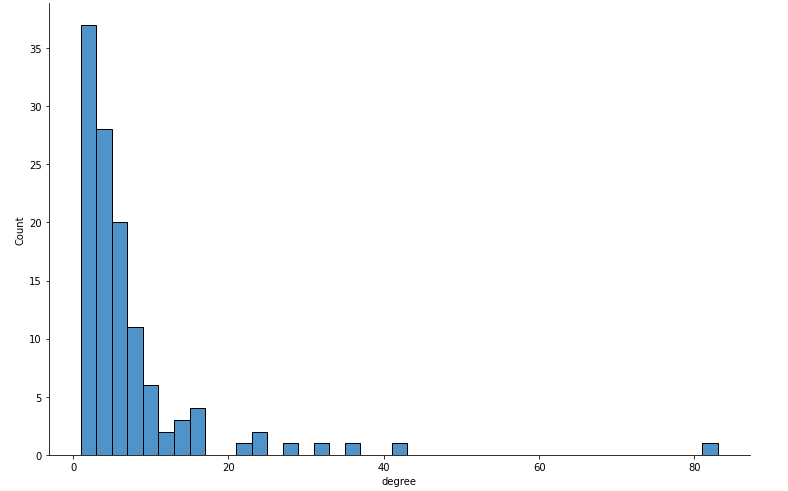
We can easily observe that most nodes have less than 15 relationships. However, there is one outlier in the dataset with 83 connections, and that is, of course, Harry Potter himself.
Projected graph object
The central concept of the GDS Python client is to allow projecting and executing graph algorithms in Neo4j with pure Python code.
Furthermore, the Python client is designed to mimic the GDS Cypher procedures so that we don’t have to learn a new syntax to use the Python client.
As you might know, before we can execute any graph algorithms, we first have to project an in-memory graph. For example, let’s say we want to project a simple directed network of characters and their interactions with the Python client.
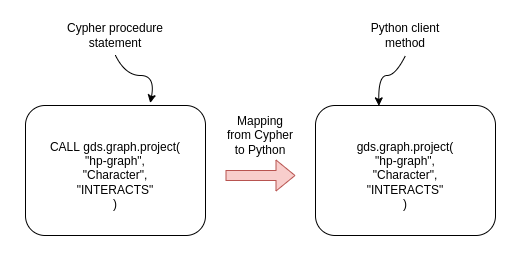
If you are familiar with Cypher procedures of Graph Data Science, you will be able to pick up the Python client syntax easily. For the most part, we remove the CALLclause before the GDS procedures, and we get the Python client syntax to project graphs or execute algorithms.
In our case, we want to project a network of characters where the interaction relationships are treated as undirected. Therefore, we must use the extended map syntax to define undirected relationships.
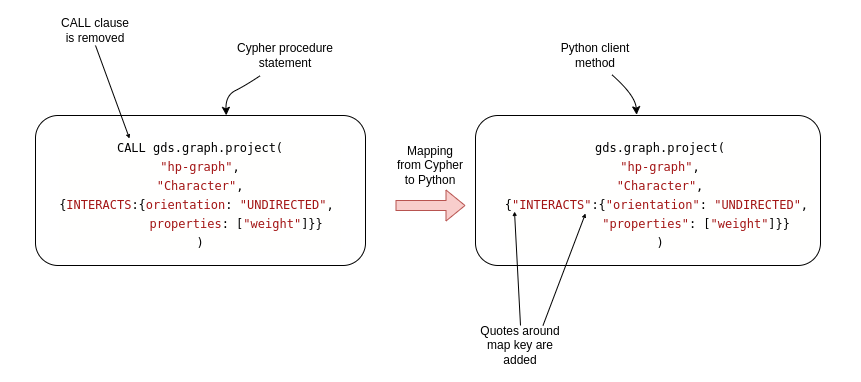
When dealing with map objects, or dictionaries as they are called in Python, we have to add quotes around map keys. Otherwise, the keys would be treated as variables in Python, and you would get a NameError as the key variables are not defined. So, apart from adding quotes and removing the CALLclause, the syntax to project an in-memory graph is identical.
When projecting a graph with the Python client, a client-side reference to the projected graph is returned. We call these references Graph objects. Along with the Graph object, the metadata from the procedure call is returned as Pandas Series.
We have passed the projected graph reference to the G variable and stored the metadata information as the metadata variable. The metadata variable contains information that you normally get as the output of the procedure.
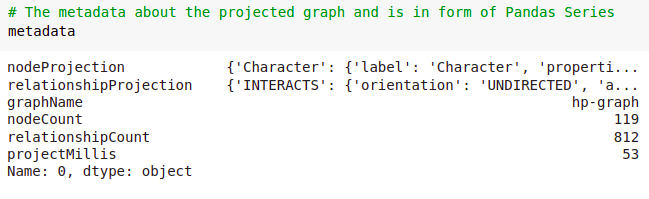
There are 119 nodes and 812 relationships in our projected graph.
The Graph object, available as the variable G, has multiple method that can be used to inspect more information about the projected graph. For a complete list of the methods consult with the official documentation.
For example, we can return the projected graph name using the name() method, inspect the memory usage using the memory_usage() method, or even calculate the density of the graph using the density() method.
Running graph algorithms
Now that we have the projected graph ready and available as the reference variable G, we can go ahead and execute a couple of graph algorithms using the Python client.
We will begin by executing the weighted variant of the PageRank algorithm. The stream mode of the algorithm returns the result of the algorithm as a stream of records.
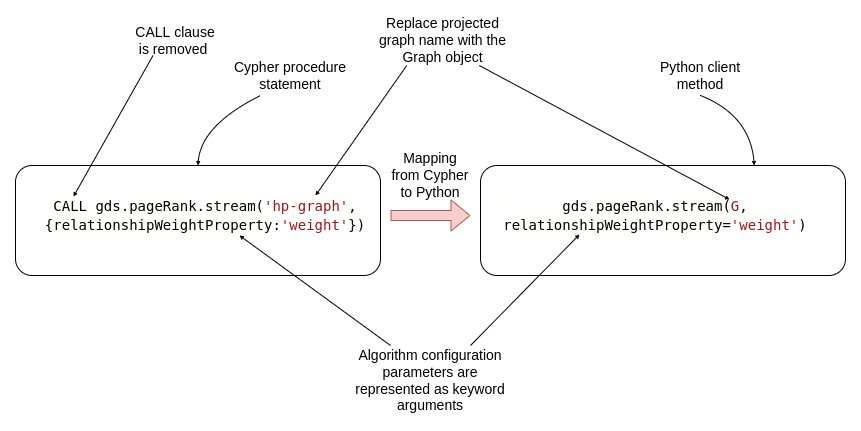
Similar to before, when we were projecting an in-memory graph, we need to remove the CALLclause in the Python client for all algorithm executions. We reference the projected graph by its name with the Cypher procedure statement. However, using the Python client, we pass the Graph object as the reference to the projected in-memory graph instead of its name. Lastly, any algorithm configuration parameters can be specified as keyword arguments in the Python client.
We can use the following Python script to execute the streammode of the weighted PageRank algorithm.
The stream mode of any algorithm in Neo4j Graph Data Science returns a stream of records. Python client then automatically converts the output into a Pandas DataFrame.
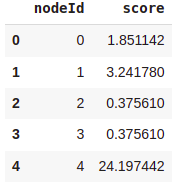
If you have ever executed the stream mode of the graph algorithms in Neo4j Graph Data Science, you might be aware that the result contains internal node ids as a reference to nodes instead of actual node objects. The pagerank_dfDataFrame contains two columns:
- nodeId: Internal node ids used to reference nodes
- score: PageRank score
We can retrieve the referenced node objects using the nodeId column without constructing a Cypher statement by using the gds.util.asNodes() method. The gds.util.asNodes() method takes a list of internal node ids as input and outputs a list of node objects.
The node_object column now contains the referenced node objects. Node objects are defined in the underlying Neo4j Python driver. You can reference the official documentation if you want to examine all the possible methods of the node object.
In this example, we will extract the nameproperty from node objects and then visualize a bar chart of the top ten characters with the highest PageRank score.
Results
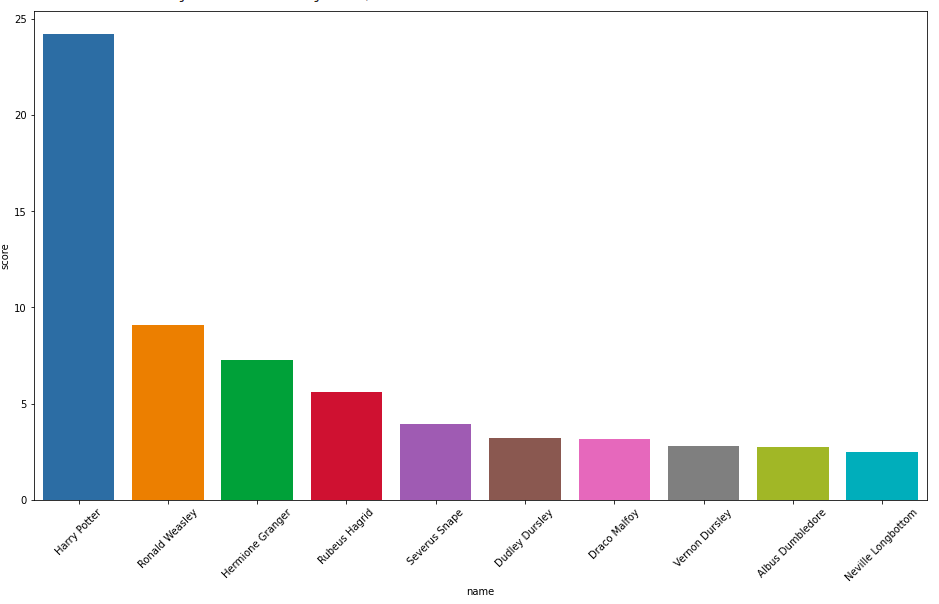
An additional benefit of having the graph algorithm output available in the Pandas DataFrame is that if you are not experienced with Cypher aggregations, you can simply skip them and do your aggregations in Pandas.
As opposed to the stream mode of algorithms, the stats, mutate, and write modes do not produce a stream of results. Therefore, the results of Python client methods are not Pandas DataFrame. Instead, those methods output the algorithm metadata in Pandas Series format.
For example, let’s say we want to execute the mutate mode of the Louvain algorithm.
The mapping from Cypher to Python is identical as in the PageRank example. The Graph object replaces the name of the projected graph, and additional algorithm configuration parameters are specified using the keyword arguments.
The metadata of the Louvain algorithm is the following:

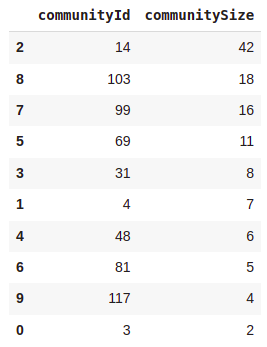
We can observe that the algorithm identified ten communities, while the modularity score is relatively low.
The mutate mode of the algorithm stores the results in the projected in-memory graph. One of the Graph object methods is the node_properties() method, which can be used to inspect which node properties are present in the in-memory graph.
The result of the node_properties() method verifies that the communityId node property was added to the projected graph.
Sometimes we want to retrieve the node properties from the projected in-memory graph. Luckily, there is a gds.graph.streamNodeProperty()method that fetches node properties from the projected in-memory graph and outputs them as a Pandas DataFrame.
The first parameter of the gds.graph.streamNodeProperty()method is the referenced Graph object. As the second parameter, we define which property we want to retrieve from the in-memory graph.
Results
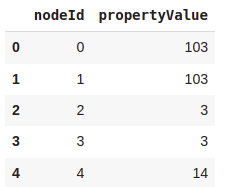
Again, we get the internal node ids in the nodeId column. We could use the gds.util.asNodes() method to fetch the node objects that the internal node ids reference. Unfortunately, the column with the retrieved node properties has a generic name propertyValue. In our case, it would make sense to name the column with the results communityId. However, we can do that manually if we need to.
Like mentioned before, the added benefit of dealing with Pandas DataFrames as algorithm output is that you can apply all your Python skills to transform or manipulate the results. In this example, we simply grouped the DataFrame by the communityId column and count the members of each community.
Helpful methods
In the last part of this post, we will go over some of the helpful methods. The first one that comes to mind is listing all of the already projected in-memory graph with the gds.graph.list() method.

Sometimes there are already projected in-memory graphs present in the database. If you don’t have a reference to the projected graphs in the form of a Graph object, you cannot execute any graph algorithm. To avoid having to drop and recreate projected graphs, you can use the gds.graph.get()method.
When using the shortest path algorithms, you need to provide source and target nodes ids. You could use Cypher statements or you could use the gds.find_node_id() method.
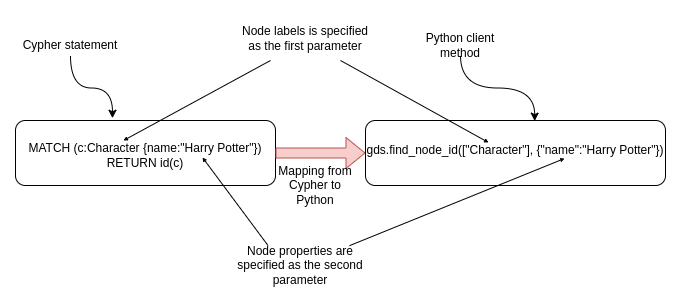
The gds.find_node_id()takes in two arguments. The first argument defines the node label we are searching for. In our example, we are searching for the Characternode label. The second parameter specifies the node properties used to identify the particular node. The node properties are defined as a dictionary or map of key-value pairs, similar to the inline MATCH clause. The only difference is that we must add quotes around the key values of properties since otherwise, we would get a NameError in Python.
The last useful method I will present here is the drop() method of a Graph object. It is used to release the projected graph from memory.
Conclusion
The Neo4j Graph Data Science Python client is designed to help you integrate Neo4j and its graph algorithms into your Python analytical workflows. The syntax of the Python client mimics the GDS Cypher procedures. Since not all graph algorithms are documented to be used as Python client method, you need to take into account the following guidelines when translating a Cypher procedure to a Python client method:
- When specifying a map or a dictionary as a parameter to any method, make sure to add quotes around the keys
- Instead of referencing the projected graph by its name, you need to input the Graph object as the first parameter of graph algorithms
- Algorithm specific configuration parameter can be specified using keyword arguments
- The streammode of graph algorithms outputs a Pandas DataFrame
- Other algorithm modes like stats, write, and mutate output the metadata of the algorithm call as a Pandas Series
I am very excited about the new Python client and will be definitely using it in my workflows. Try it out and if you have any feedback please report it to the official GitHub repository of the Python client.
As always, the code is available on GitHub.
How to Get Started With the Neo4j Graph Data Science Python Client was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3