ElasticSearch
Interacting with Elastic Search
| Qualified Name | Type | Release |
|---|---|---|
|
- elastic search statistics |
|
|
|
- perform a GET operation on elastic search |
|
|
|
- perform a SEARCH operation on elastic search |
|
|
|
- perform a raw GET operation on elastic search |
|
|
|
- perform a raw POST operation on elastic search |
|
|
|
- perform a POST operation on elastic search |
|
|
|
- perform a PUT operation on elastic search |
|
|
Example
call apoc.es.post("localhost","tweets","users",null,{name:"Chris"})call apoc.es.put("localhost","tweets","users","1",null,{name:"Chris"})call apoc.es.get("localhost","tweets","users","1",null,null)call apoc.es.stats("localhost")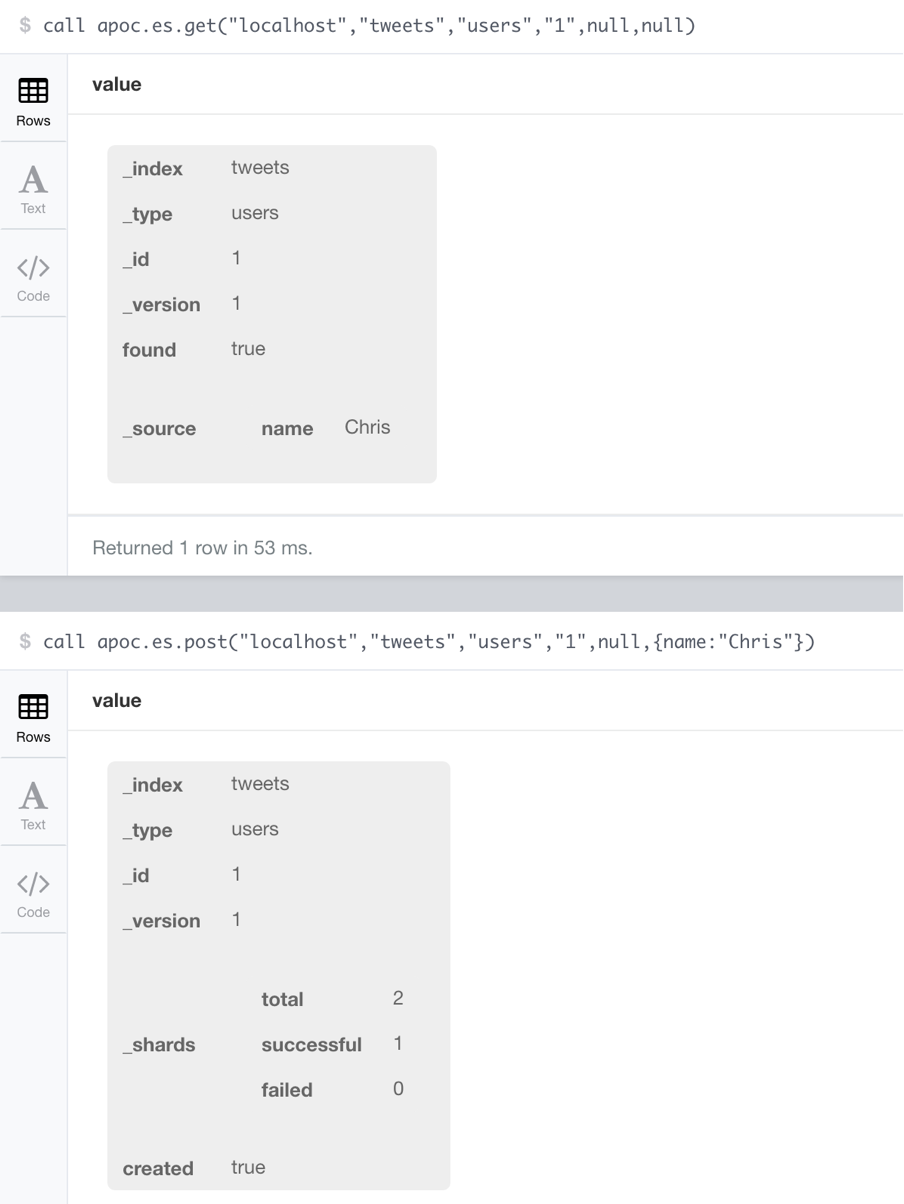
Pagination
To use the pagination feature of Elasticsearch you have to follow these steps:
-
Call apoc.es.query to get the first chunk of data and obtain also the scroll_id (in order to enable the pagination).
-
Do your merge/create etc. operations with the first N hits
-
Use the range(start,end,step) function to repeat a second call to get all the other chunks until the end. For example, if you have 1000 documents and you want to retrieve 10 documents for each request, you cand do range(11,1000,10). You start from 11 because the first 10 documents are already processed. If you don’t know the exact upper bound (the total size of your documents) you can set a number that is bigger than the real total size.
-
The second call to repeat is apoc.es.get. Remember to set the scroll_id as a parameter.
-
Then process the result of each chunk of data as the first one.
Here an example:
// It's important to create an index to improve performance
CREATE INDEX ON :Document(id)
// First query: get first chunk of data + the scroll_id for pagination
CALL apoc.es.query('localhost','test-index','test-type','name:Neo4j&size=1&scroll=5m',null) yield value with value._scroll_id as scrollId, value.hits.hits as hits
// Do something with hits
UNWIND hits as hit
// Here we simply create a document and a relation to a company
MERGE (doc:Document {id: hit._id, description: hit._source.description, name: hit._source.name})
MERGE (company:Company {name: hit._source.company})
MERGE (doc)-[:IS_FROM]->(company)
// Then call for the other docs and use the scrollId value from previous query
// Use a range to count our chunk of data (i.e. i want to get chunks from 2 to 10)
WITH range(2,10,1) as list, scrollId
UNWIND list as count
CALL apoc.es.get("localhost","_search","scroll",null,{scroll:"5m",scroll_id:scrollId},null) yield value with value._scoll_id as scrollId, value.hits.hits as nextHits
// Again, do something with hits
UNWIND nextHits as hit
MERGE (doc:Document {id: hit._id, description: hit._source.description, name: hit._source.name})
MERGE (company:Company {name: hit._source.company})
MERGE (doc)-[:IS_FROM]->(company) return scrollId, doc, companyThis example was tested on a Mac Book Pro with 16GB of RAM. Loading 20000 documents from ES to Neo4j (100 documents for each request) took 1 minute.
General Structure and Parameters
call apoc.es.post(host-or-port,index-or-null,type-or-null,id-or-null,query-or-null,payload-or-null) yield value
// GET/PUT/POST url/index/type/id?query -d payloadhost or port parameter
The parameter can be a direct host or url, or an entry to be lookup up in apoc.conf
-
host
-
host:port
-
lookup via key to apoc.es.<key>.url
-
lookup via key apoc.es.<key>.host
-
lookup apoc.es.url
-
lookup apoc.es.host
index parameter
Main ES index, will be sent directly, if null then "_all" multiple indexes can be separated by comma in the string.
type parameter
Document type, will be sent directly, if null then "_all" multiple types can be separated by comma in the string.
query parameter
Query can be a map which is turned into a query string, a direct string or null then it is left off.