What is AI-ready data? How a knowledge layer gets you there

Graph Database Product Specialist, Neo4j
15 min read

Most enterprise AI projects stall in production, and the data behind them is usually the reason. Without AI-ready data, AI systems have access to your information but no way to reason over it.
Traditional enterprise data infrastructure was built for deterministic software that takes a fixed input, follows a fixed workflow, and returns a fixed output, all within rigid schemas and siloed systems.
AI systems work differently. You give an AI agent a goal, and it decides what data to pull, plans its own steps, and acts on its own. But most enterprise data today doesn’t support that non-deterministic autonomy.
Gartner reports that 63% of organizations either don’t have or aren’t sure they have the right data management practices for AI. The firm predicts that organizations will abandon 60% of AI projects that lack AI-ready data through 2026.
Organizations that move AI initiatives into production need AI-ready data they can build, maintain, and trust. The knowledge layer provides that foundation by providing data that AI can navigate, understand, and reason about.
More in this guide:
What is AI-ready data?
Put simply, AI-ready data is data that AI agents can use to reliably reason, decide, and act on to produce accurate, explainable, and governable outcomes.
What makes data AI-ready comes down to three qualities: It has to be contextual, flexible, and standardized. Each quality affects whether an agent can navigate your data and do something useful with it.
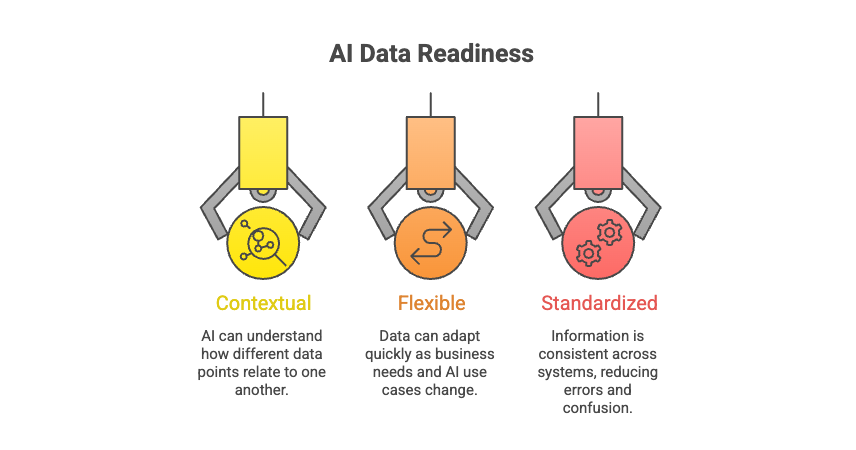
AI-ready data is contextual
Contextual data exposes not only individual facts to your AI agent but also their connections to each other. In other words, the agent sees both the data points and the surrounding context that adds valuable meaning.
Picture a customer support agent handling a refund request. Without context, it retrieves the order details in isolation and walks down a rulebook. The output is generic at best and wrong at worst, neither making for a happy customer.
With contextual data, the same agent navigates the connections and retrieves the order, the customer’s purchase patterns, their support history, their contract terms, and how similar cases were resolved in the past. Now it can reason about this specific customer’s situation and act accordingly.
AI-ready data is flexible
Flexible data adapts as your AI use cases evolve. That means your agent can pick up new signals without waiting for a database refactor.
Imagine you launch an AI agent to flag customers at risk of churning. Two months in, the business wants the agent to also weigh which customers recently changed account managers and which subscription tiers are approaching renewal — two signals you didn’t model originally. Without flexible data, adding these signals means schema migrations across customer, account, and subscription tables, plus rewrites to every query in the churn pipeline. The improved agent ships the next quarter, not the next sprint. Momentum on your AI initiative slows.
With flexible data, your team simply adds two new labels to the model and connects them to the existing entities, with the agent picking up the new signals through the connections. When the business asks for the next use case a month later, your team adds it just as fast. The AI initiative moves at the pace of your use cases, instead of waiting for your databases to catch up.
AI-ready data is standardized
Standardized data carries one consistent meaning across all sources. As a result, your agent reasons from a coherent view of the world rather than stitching identities together at runtime.
Envision an agent asked to summarize a customer’s recent activity. It pulls a customer record from your CRM (where the ID is a string), the latest invoice from your billing system (where the same person has an integer ID), and a recent support ticket (UUID). The agent has to guess which records belong to the same person — adding latency, cost, and the risk of assembling a summary from data that doesn’t actually belong to one customer. That mistake feeds straight into your downstream decisions.
With standardized data, the customer has one canonical definition. All other customer data maps to the canonical definition through relationships. The agent traverses those connections to get a coherent view of the customer, the order, the supplier, and anything else the task requires. The risk of hallucination from data drift goes away. You get more accurate, consistent answers you can rely on.
Why AI-ready data needs a knowledge layer
Think about how you make decisions. Your brain doesn’t store facts in isolated rows. You connect multiple facts to context (the current situation, past experiences, related knowledge) to arrive at a good decision. AI systems also need a structure that helps it make these connections and reason about data the same way.
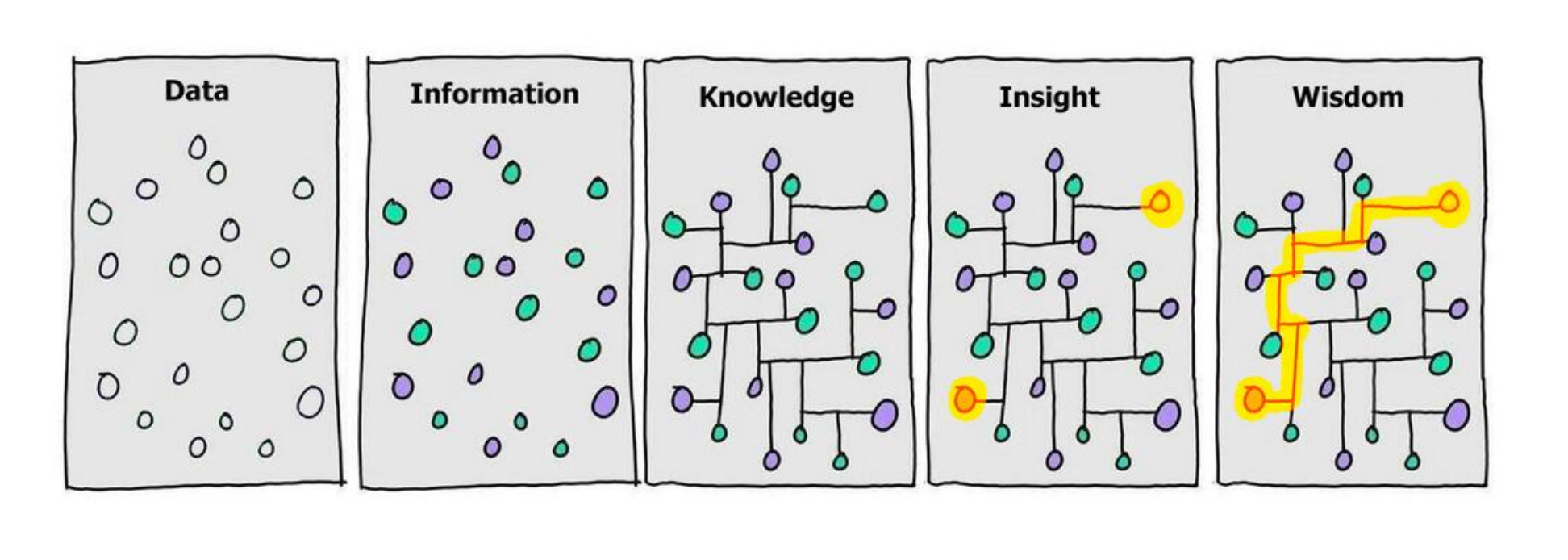
A knowledge layer sits between your existing data infrastructure and your AI systems so that your data is ready for AI. Graphs provide the structure for the knowledge layer, allowing agents to navigate, understand, and reason about your data.

An AI-ready architecture uses the knowledge layer to connect existing systems, retrieval, and agent memory in one governed foundation. You ingest data from your existing operational databases and unstructured content stores into an enterprise knowledge graph, extract entities, and index them with vector embeddings for rapid retrieval. Using virtual graphs, the system reads your data warehouses in the context of your knowledge graph to derive intelligence without requiring a migration. The agent writes its conversation and decision history into the graph for additional context, connecting everything to your existing knowledge. The AI then reasons from this knowledge layer, which sits on top of your current data infrastructure.
For this to happen, the knowledge layer uses multiple components, including knowledge graph, context graph, and GraphRAG.
Knowledge graph for flexible and standardized enterprise knowledge
Your business data is scattered across CRM, ERP, warehouses, and dozens of databases. A knowledge graph pulls data from those structured and unstructured sources, resolves entities so the same entity is recognized consistently, maps the connections between entities, enriches the entities and relationships with metadata that reflects your business ontology, and stores it all as one navigable graph.
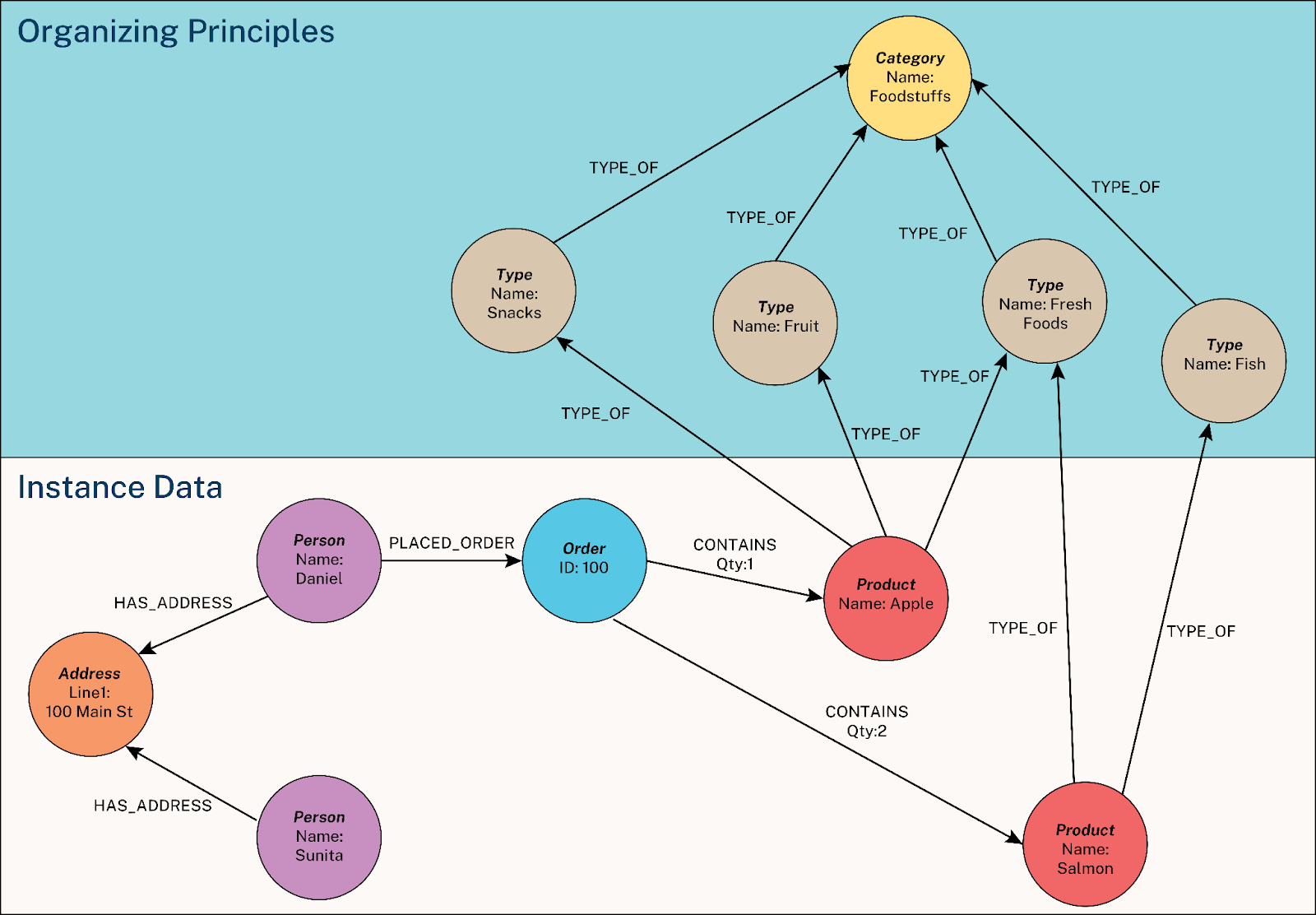
This becomes your AI’s long-term memory. Everything your business knows is interconnected and available in one place. Your AI can easily navigate all the relevant knowledge by traversing the relationships and reasoning over them with the metadata. But business knowledge alone only gets the agent partway there.
Context graph for contextual agent memory
Business knowledge gets the agent partway there. To operate reliably over time, the agent also needs to remember what it decided on, what it acted on, and what it learned.
A context graph extends the knowledge graph with two additional memory types.
- Short-term memory captures the conversation in progress: what the user just asked, what tasks are open, and what context the agent has gathered for this turn.
- Reasoning memory captures the agent’s decision history: the plan it tried, the tools it called, the results it observed, and the corrections you gave it after the first attempt failed. Every decision becomes a traceable path through the graph.
Short-term and reasoning memory live in the same graph as your business knowledge, connected by explicit relationships. Every decision and action can be replayed, audited, and learned from.
Long-term memory, short-term memory, and reasoning memory together form the complete agent memory that any production AI system needs. The agent also needs to retrieve the right context from that memory at query time. For that, you need GraphRAG.
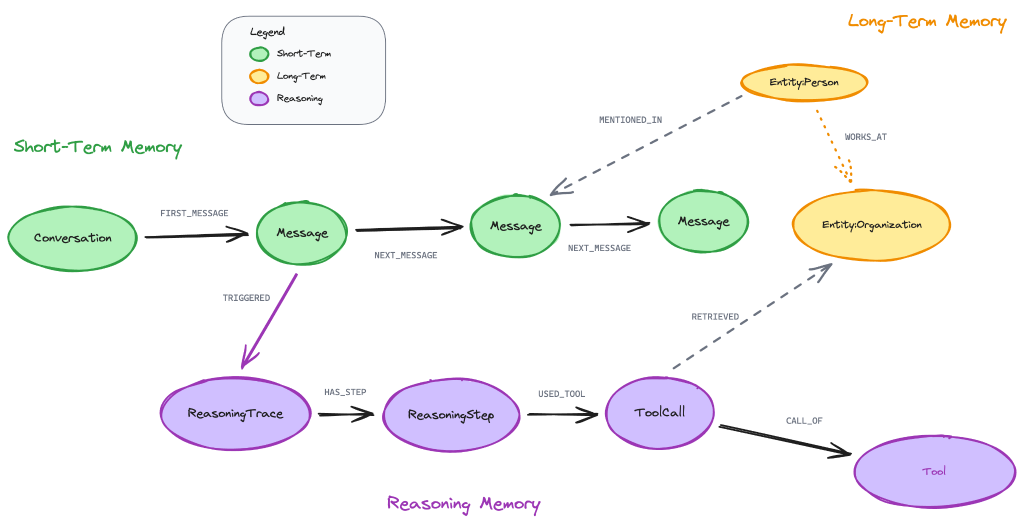
GraphRAG for graph retrieval and multi-step reasoning
Standard vector RAG retrieves text chunks based on semantic similarity. For straightforward questions, the answer may appear in a similar passage. But complex questions that depend on multi-step reasoning, like “What is this customer’s supplier risk based on order history?” may not match any single text passage. The AI needs to look up the customer, review their orders and products, connect those products to suppliers, and evaluate their delivery history to provide an informed answer.
GraphRAG enables AI agents to traverse multiple hops through chains of relationships in your knowledge graph to find all the relevant information, even if they’re not semantically similar. It performs multi-step reasoning to arrive at a more accurate, grounded answer.
Benefits of the knowledge layer for AI
By replacing isolated data with an interconnected graph, you provide AI agents with the knowledge layer they need for holistic context and complex reasoning. This architectural shift results in AI outcomes that are more accurate, explainable, and governable.
More accurate answers
AI grounded in a knowledge graph can retrieve related facts rather than only semantically similar text. The AI can follow relationships to gather the context a question needs before generating an answer. A May 2026 IDC study found that grounding AI in Neo4j knowledge graphs reduced hallucination rates by an average of 44%, with one life sciences customer reducing hallucination rates from 20-40% to 2-5%.
Explainable reasoning
When an AI agent follows a path to retrieve context, that path is recorded. It can show which entities the agent retrieved, which relationships it traversed, which tools it called, and which facts supported the answer. This makes it easy to trace, visualize, and review the AI’s reasoning along the way.
Governable AI
Governance cannot depend on prompts alone. A knowledge layer makes definitions, lineage, permissions, rules, and decision traces explicit in the data architecture. Teams can control which data agents can access, trace what they used, and audit how outputs were produced. As use cases grow, the same graph can evolve with new entities and relationships without forcing teams to rebuild the governance model from scratch.
Case studies: AI-ready data in enterprise production systems
Looking at data management practices, what do AI-ready enterprises have in common? They stop trying to move all data into one warehouse or database and build a knowledge layer that maps entities, relationships, and meaning across sources.
Klarna connects internal knowledge for 85% AI assistant adoption
Klarna’s organizational knowledge was spread across more than 1,200 SaaS systems, including Salesforce and Workday. That fragmentation made AI answers harder to ground.
To solve that, Klarna built Kiki, an internal AI assistant powered by Neo4j knowledge graph technology and integrated with OpenAI large language models. Kiki connects knowledge across people, projects, processes, and systems.
Kiki has answered more than 250,000 inquiries since launching, 85% of employees use it, and Klarna has deprecated more than 1,200 SaaS systems.
“Feeding an LLM the fractioned, fragmented, and dispersed world of corporate data will result in a very confused LLM.”
Data² gives analysts an explainable GraphRAG evidence trail
Data² works with high-stakes defense, intelligence, and energy data, where valuable information often lives in unstructured sources such as drilling reports, facilities records, and maintenance logs that relational databases struggle to analyze across relationships.
The Data² team developed reView, an analytics and reasoning platform with a knowledge graph built on Neo4j AuraDB. The platform uses Neo4j GraphRAG for question answering and evidence review, with separate evidence and question graphs that help prevent language models from ingesting incorrect data. Analysts can drill into the evidence behind each answer and follow how the system reached a conclusion.
Data² estimates reView frees up 50% of analyst workload.
Cummins builds an AI-ready digital core with graph
Cummins needed to connect more than 100 years of legacy data across disparate systems. Employees spent 50-70% of their time assembling data across tools and sources.
To address the fragmentation problem, the company built an AI-ready digital core with a cloud platform, a Neo4j Knowledge Layer as a mind map, and an AI sandbox. The system connects data across Snowflake, Databricks, and other sources, using ontologies to map contextual relationships, such as how a construction site in China can affect a specific engine component in a US warehouse.
As a result, data-wrangling time reduced from 60% to 10%. By asking natural language questions of the mind map, they were able to mitigate tariff and supply risks within two weeks.
How to make your data AI-ready in 5 steps
To make your data AI-ready, you need to build a knowledge layer — the connected, contextual foundation your AI needs to reason and act reliably.
Start with one AI use case and the data it needs, then go from there. This practical sequence is more useful than a broad data modernization program, as it lets you model the entities, relationships, context, and retrieval patterns around a question the business actually needs answered.
1. Define the use case and graph schema
Choose the question or task the AI system needs to support, such as identifying customers likely to churn, suppliers that create risk for a specific order, support responses an agent should recommend, or internal policies that apply to a specific case.
Define the data schema that supports the use case, including the entities, how they relate to each other, and their properties. Decide what counts as a customer, how a customer relates to an order, supplier, support ticket, contract, or account owner, and which definitions, rules, and permissions apply. Model the domain around the use case, then expand the schema as more questions emerge.
2. Build a knowledge graph from structured and unstructured sources
Ingest the data sources. A practical pipeline should extract entities, resolve duplicates, add relationships between entities, add metadata, and ingest the data into the knowledge graph.
Avoid trying to model the whole enterprise at once. Start with the high-value data to address the use cases. The graph schema is flexible, so it can adapt easily without significant refactoring.
3. Index your data and set up retrieval patterns
Different questions need different retrieval paths, and most production systems will use more than one. A stronger retrieval setup routes each question to the correct pattern rather than querying every source every time.
Vector or full-text indexes help AI agents find accurate entry points. Cypher query templates help agents handle common retrieval paths more quickly and reliably.
4. Build a context graph so AI can learn
Production AI needs stateful memory. It needs to record what happened during a task, including the evidence retrieved, the tools called, the outcomes observed, and the decisions made. The context graph provides AI with memory for conversation history and decision traces — all connected to the knowledge graph. Neo4j Agent Memory provides graph-based patterns for storing conversations, building knowledge graphs, and supporting reasoning over prior agent activity.
5. Evaluate the use case success and improve
Build an evaluation set for the most common questions or use cases you’d expect the AI system to receive. Define the success criteria for the use case and select evaluation metrics, such as answer relevance, context relevance, context recall, latency, and token cost. If the results don’t meet the criteria, iterate steps 1 to 4 and repeat. Evaluate after every iteration to measure improvement or regression until it meets the success criteria.
Build the knowledge layer for AI-ready data
Moving from fragmented, stall-prone experiments to production-grade intelligence doesn’t require ripping out your existing data infrastructure. It requires a knowledge layer that sits on top of what you’ve already built.
By mapping the relationships, context, and meaning of your enterprise data — from your databases and warehouses to your CRM and support tickets — the knowledge layer provides the memory and reasoning foundation your AI needs.
Neo4j is the knowledge layer for enterprise AI. It works with your current data infrastructure through a modular portfolio of graph and AI capabilities:
- Neo4j Graph Database stores data as nodes and relationships, so applications can follow connections directly instead of forcing every relationship-heavy question through joins
- Neo4j Graph Data Science adds 65+ graph algorithms and graph-native ML pipelines to surface patterns, score influence, and turn graph structure into features for downstream models
- Neo4j AuraDB runs graph database workloads as a fully managed cloud service
- Neo4j Agent Memory give agents stateful memory by connecting persistent business knowledge with conversation history, decisions, and reasoning traces from each interaction
- Neo4j GraphRAG Python Package allows AI to traverse graphs to retrieve related facts and perform multi-hop reasoning
- Neo4j Virtual Graph connects data from existing warehouse and lakehouse environments to entities in the knowledge graph, adding intelligence without migration
Use these resources to go deeper:
- Developer’s guide: How to build a knowledge graph
- Essential GraphRAG
- Context graphs: Why your AI agents need three types of memory
Build your knowledge layer for AI-ready data
Start with Neo4j AuraDB and see how connected data helps AI systems retrieve, reason, and act with trusted context.
AI-ready data FAQs
AI-ready data is data that AI agents can use to reliably reason, decide, and act on to produce accurate, explainable, and governable outcomes.
Many AI projects fail because AI can access data without understanding how different pieces of information are related to each other. Production AI systems need consistent data definitions, connected context, governed access, and retrieval patterns suited to users’ questions.
AI-ready data should be contextual, flexible, and standardized. Contextual data exposes relationships. Flexible data adapts as use cases evolve. Standardized data gives entities and concepts consistent meaning across sources.
A knowledge layer connects data across existing systems so that AI can navigate, understand, and reason about it. It standardizes entities, maps relationships, adds context, provides durable memory, and enables multi-step reasoning.
Build a knowledge layer for AI-ready data. Start with a specific use case. Define the entities, relationships, rules, and data sources the AI system needs. Ingest your business knowledge into the graph. Set up agent memory for conversation and reasoning context. Implement GraphRAG retrieval patterns. Evaluate and improve.
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI
