When it comes to NoSQL databases, data consistency models can sometimes be strikingly different than those used by relational databases (as well as quite different from other NoSQL stores).
The two most common consistency models are known by the acronyms ACID and BASE. While they’re often pitted against each other in a battle for ultimate victory, both consistency models come with advantages and disadvantages, and neither is always a perfect fit.
This blog post will give you insights into the ACID and BASE models, and help you decide which consistency model is best for you.
Let’s take a closer look at the trade-offs of both database consistency models.
The ACID model
Many developers are familiar with ACID transactions from working with relational databases. As such, the ACID consistency model has been the norm for some time.
The key ACID guarantee is that it provides a safe environment in which to operate your data. The ACID acronym stands for:
- Atomic: All operations in a transaction succeed, or every operation is rolled back.
- Consistent: On the completion or rollback of a transaction, the database is in a consistent state; there are no partial updates or logical corruptions.
- Isolated: Transactions do not contend with one another. Contentious access to data is moderated by the database so that transactions appear to run sequentially.
- Durable: The results of applying a transaction are permanent, even in the presence of failures.
Use cases for ACID databases
ACID-compliant databases are widely used in industries like finance, healthcare, and government administration, where data storage is highly regulated. ACID compliance makes it so that, for example, a bank’s customers don’t have to worry about their account balances displaying incorrectly since an ACID-compliant database will always retrieve up-to-date data.
Many small-to-medium-scale enterprises also use ACID-compliant databases for their ease of use and stability. The relatively small scale of the data these organizations process means that they don’t mind the overhead ACID compliance adds to database operations, such as time to process long JOINs.
Which databases use ACID?
Popular ACID-compliant databases include all SQL engines (Oracle, MySQL, PostgreSQL, and MS SQL server are a few examples), Neo4j, and MongoDB. You can usually find out if a database is ACID-compliant by searching the database’s website for a statement on ACID compliance.
ACID properties mean that once a transaction is complete, its data is consistent (tech lingo: write consistency) and stable on disk, which may involve multiple distinct memory locations.
Write consistency is a wonderful thing for application developers, but it also requires sophisticated locking, which is typically a heavyweight pattern for most use cases.
When it comes to NoSQL technologies, most graph databases (including Neo4j) use an ACID consistency model to ensure data is safe and consistently stored.
The BASE model
For many domains and use cases, ACID transactions are far more pessimistic (i.e., they’re more worried about data safety) than the domain actually requires.
In some NoSQL databases where performance relies on large-scale sharding and horizontal scale-out (MPP) for performance, maintaining ACID compliance is extremely costly (for example, the overhead of 2 Phased Commit/2PC protocols) when a transaction spans possibly dozens of instances. As a result, NoSQL databases that rely heavily on horizontal scaling for performance often use the BASE transaction model.
(Notably, the .NET-based RavenDB has bucked the trend among aggregate stores in supporting ACID transactions.)
Here’s how the BASE acronym breaks down:
- Basic Availability: The database appears to work most of the time.
- Soft-state: Stores don’t have to be write-consistent, nor do different replicas have to be mutually consistent all the time.
- Eventual consistency: Stores exhibit consistency at some later point (e.g., lazily at read time).
Use cases for BASE databases
BASE-compliant databases are almost exclusively used by large companies in relatively unregulated spaces that process several terabytes or more of data every day. The large scale of these companies means that they reach a point where the overhead from enforcing ACID compliance starts to demonstratively hurt operations. Thus, they look for alternative models without such overhead. In fact, many BASE-compliant databases originated as projects by these companies to address this very issue, like DynamoDB (Amazon) and BigTable (Google).
There may also be some niche use cases for BASE-compliant databases for smaller organizations. For example, a startup that predicts that the amount of data it processes will grow quickly may want to use a BASE-compliant database to avoid a potential migration process down the line.
Which databases use BASE?
Popular BASE-compliant databases include BigTable and DynamoDB, as well as Cassandra and Hadoop. You can often find out if a particular database is BASE-compliant by looking around its website.
A BASE data store values availability (since that’s important for scale), but it doesn’t offer guaranteed consistency of replicated data at write time. Overall, the BASE consistency model provides a less strict assurance than ACID: data will be consistent in the future, either at read time (e.g., Riak) or it will always be consistent, but only for certain processed past snapshots (e.g., Datomic).
In addition to the MPP NoSQL use cases, other stores that use the BASE model are ones that are not considered to be the primary system of record and can be rebuilt easily from the original sources. These include aggregate stores, key-value stores (often used to cache data), and, in some cases, document stores.
Navigating ACID vs. BASE trade-offs
There’s no right answer to whether your application needs an ACID versus BASE consistency model. Developers and data architects should select their data consistency trade-offs on a case-by-case basis – not based just on what’s trending or what model was used previously.
Given BASE’s loose consistency, developers need to be more knowledgeable and rigorous about consistent data if they choose a BASE store for their application. It’s essential to be familiar with the BASE behavior of your chosen aggregate store and work within those constraints.
On the other hand, planning around BASE limitations can sometimes be a major disadvantage when compared to the simplicity of ACID transactions. A fully ACID database is the perfect fit for use cases where data reliability and consistency are essential (banking, anyone?).
If you decide on using an ACID-compliant database, you might want to choose a graph database. These types of databases are great for modeling relationships and are very fast compared to traditional RDBMS systems like SQL.
Thinking about building a knowledge graph?
Download The Developer’s Guide: How to Build a Knowledge Graph for a step-by-step walkthrough of everything you need to know to start building with confidence.
Catch up with the rest of the Graph Databases for Beginners series:
- Wait, What Do You Mean by Graph?
- Why Graph Technology Is the Future
- Why Connected Data Matters
- The Basics of Data Modeling
- Data Modeling Pitfalls to Avoid
- Why a Database Query Language Matters (More Than You Think)
- Imperative vs. Declarative Query Languages: What’s the Difference?
- Graph Theory & Predictive Modeling
- Graph Search Algorithm Basics
- Why We Need NoSQL Databases
- A Tour of Aggregate Stores
- Other Graph Data Technologies
- Native vs. Non-Native Graph Technology
Share Article



Explore
Related Articles
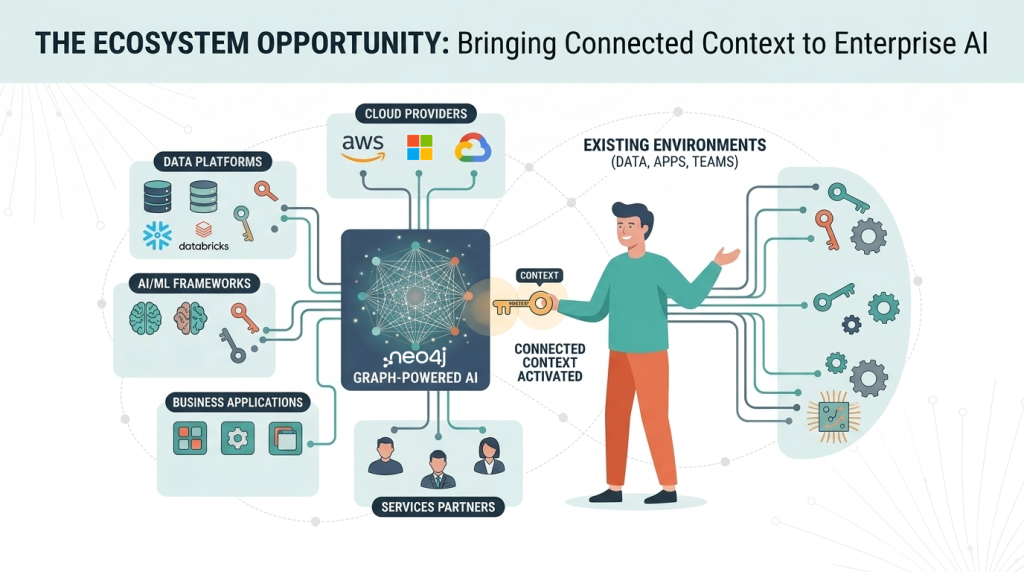
Introducing MCP for Aura: Hosted MCP, built into every Aura instance

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks

A workbench for teams to query, explore, and visualize graph data
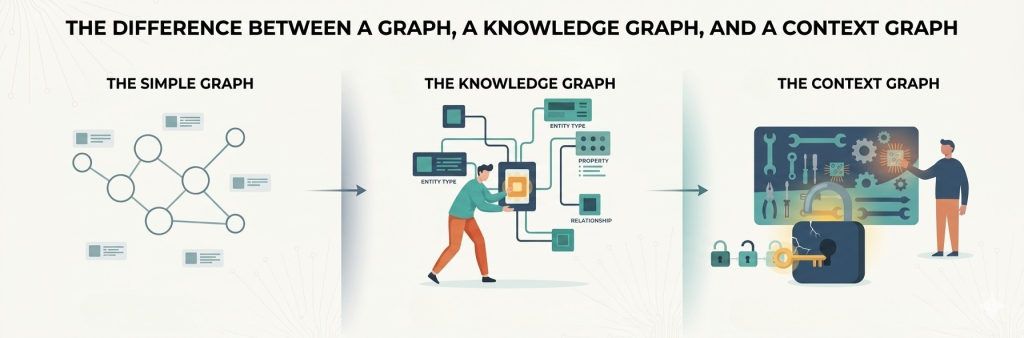
1 of 3: The difference between a graph, a knowledge graph, and a context graph
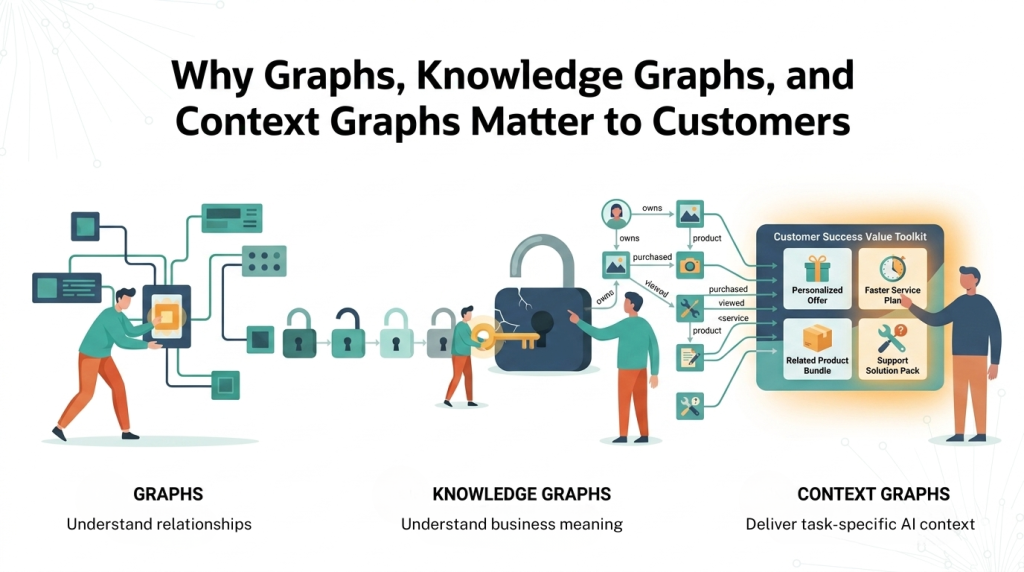
2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers