Building a GraphRAG agent with Neo4j and Milvus


7 min read
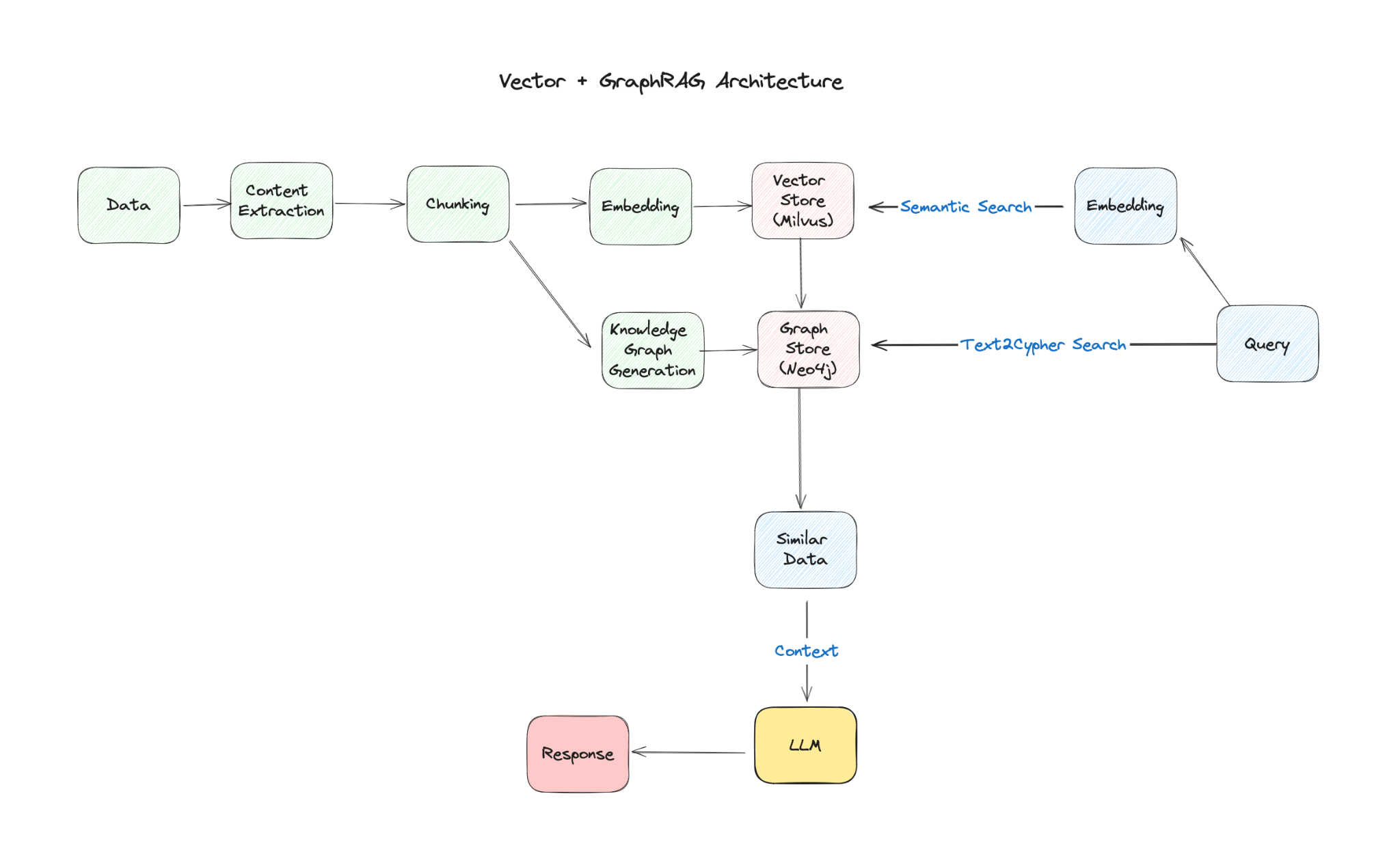
This blog post details how to build a GraphRAG agent using the Neo4j graph database and Milvus vector database. This agent combines the power of graph databases and vector search to provide accurate and relevant answers to user queries. In this example, we will use LangGraph, Llama 3.1 8B with Ollama and GPT-4o.
Traditional Retrieval Augmented Generation (RAG) systems rely solely on vector databases to retrieve relevant documents. Our approach goes further by incorporating Neo4j to capture relationships between entities and concepts, offering a more nuanced understanding of the information. We want to create a more robust and informative RAG system by combining these two techniques.
Building the RAG agent
Our agent follows three key concepts: routing, fallback mechanisms, and self-correction. These principles are implemented through a series of LangGraph components:
- Routing – A dedicated routing mechanism decides whether to use the vector database, the knowledge graph, or a combination of both based on the query.
- Fallback – In situations where the initial retrieval is insufficient, the agent falls back to a web search using Tavily.
- Self-correction – The agent evaluates its own answers and attempts to correct hallucinations or inaccuracies.
We then have other components, such as:
- Retrieval – We use Milvus, an open-source and high-performance vector database, to store and retrieve document chunks based on semantic similarity to the user’s query.
- Graph enhancement – Neo4j is used to construct a knowledge graph from the retrieved documents, enriching the context with relationships and entities.
- LLMs integration – Llama 3.1 8B, a local LLM, is used for generating answers and evaluating the relevance and accuracy of retrieved information, while GPT-4o is used to generate Cypher, the query language used by Neo4j.
The GraphRAG architecture
The architecture of our GraphRAG agent can be visualized as a workflow with several interconnected nodes:
- Question routing – The agent first analyzes the question to determine the best retrieval strategy (vector search, graph search, or both).
- Retrieval – Based on the routing decision, relevant documents are retrieved from Milvus, or information is extracted from the Neo4j graph.
- Generation – The LLM generates an answer using the retrieved context.
- Evaluation – The agent evaluates the generated answer for relevance, accuracy, and potential hallucinations.
- Refinement (if needed) – If the answer is deemed unsatisfactory, the agent may refine its search or attempt to correct errors.
The developer’s guide to GraphRAG
Build a knowledge graph to feed your LLM with valuable context for your GenAI application. Learn the three main patterns and how to get started.
Examples of agents
To showcase the capabilities of our LLM agents, let’s look into two different components: Graph Generation and Composite Agent.
While the full code is available at the bottom of this post, these snippets will provide a better understanding of how these agents work within the LangChain framework.
Graph generation
This component is designed to improve the question-answering process by using the capabilities of a Neo4j. It answers questions by leveraging the knowledge embedded within the Neo4j graph database. Here is how it works:
GraphCypherQAChain– Allows the LLM to interact with the Neo4j graph database. It uses the LLM in two ways:
cypher_llm– This instance of the LLM is responsible for generating Cypher queries to extract relevant information from the graph based on the user’s question.- Validation – Makes sure the Cypher queries are validated to ensure that they are syntactically correct.
- Context retrieval – The validated queries are executed on the Neo4j graph to retrieve the necessary context.
- Answer generation – The language model uses the retrieved context to generate an answer to the user’s question.
### Generate Cypher Query
llm = ChatOllama(model=local_llm, temperature=0)
# Chain
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm,
qa_llm=llm,
validate_cypher=True,
graph=graph,
verbose=True,
return_intermediate_steps=True,
return_direct=True,
)
# Run
question = "agent memory"
generation = graph_rag_chain.invoke({"query": question})
This component enables the RAG system to tap into Neo4j, which can help provide more comprehensive and accurate answers.
Composite agent, graph and vector 🪄
This is where the magic happens: Our agent can combine results from Milvus and Neo4j, allowing for a better understanding of the information and leading to more accurate and nuanced answers. Here is how it works:
- Prompts – We define a prompt that instructs the LLM to use the context from both Milvus and Neo4j to answer the question.
- Retrieval – The agent retrieves relevant information from Milvus (using vector search) and Neo4j (using Graph Generation).
- Answer generation – Llama 3.1 8B processes the prompt and generates a concise answer, leveraging the combined knowledge from the vector and graph databases with the composite chain.
### Composite Vector + Graph Generations
cypher_prompt = PromptTemplate(
template="""You are an expert at generating Cypher queries for Neo4j.
Use the following schema to generate a Cypher query that answers the given question.
Make the query flexible by using case-insensitive matching and partial string matching where appropriate.
Focus on searching paper titles as they contain the most relevant information.
Schema:
{schema}
Question: {question}
Cypher Query:""",
input_variables=["schema", "question"],
)
# QA prompt
qa_prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following Cypher query results to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise. If topic information is not available, focus on the paper titles.
Question: {question}
Cypher Query: {query}
Query Results: {context}
Answer:""",
input_variables=["question", "query", "context"],
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Chain
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm,
qa_llm=llm,
validate_cypher=True,
graph=graph,
verbose=True,
return_intermediate_steps=True,
return_direct=True,
cypher_prompt=cypher_prompt,
qa_prompt=qa_prompt,
)
Let’s have a look at the results of our search, combining the strengths of graph and vector databases to enhance our research paper discovery.
We begin with our graph search using Neo4j:
# Example input data
question = "What paper talks about Multi-Agent?"
generation = graph_rag_chain.invoke({"query": question})
print(generation)
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (p:Paper)
WHERE toLower(p.title) CONTAINS toLower("Multi-Agent")
RETURN p.title AS PaperTitle, p.summary AS Summary, p.url AS URL
> Finished chain.
{'query': 'What paper talks about Multi-Agent?', 'result': [{'PaperTitle':
'Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework', 'Summary':
'In this work, we aim to push the upper bound of the reasoning capability of LLMs by
proposing a collaborative multi-agent, multi-reasoning-path (CoMM) prompting framework.
Specifically, we prompt LLMs to play different roles in a problem-solving team, and
encourage different role-play agents to collaboratively solve the target task.
In particular, we discover that applying different reasoning paths for different roles
is an effective strategy to implement few-shot prompting approaches in the multi-agent
scenarios. Empirical results demonstrate the effectiveness of the proposed methods on
two college-level science problems over competitive baselines. Our further analysis shows
the necessity of prompting LLMs to play different roles or experts independently.',
'URL': 'https://github.com/amazon-science/comm-prompt'}]The graph search excels at finding relationships and metadata. It can quickly identify papers based on titles, authors, or predefined categories, providing a structured view of the data.
Next, we turn to our vector search for a different perspective:
# Example input data
question = "What paper talks about Multi-Agent?"
# Get vector + graph answers
docs = retriever.invoke(question)
vector_context = rag_chain.invoke({"context": docs, "question": question})
> The paper discusses "Adaptive In-conversation Team Building for Language Model Agents"
and talks about Multi-Agent. It presents a new adaptive team-building paradigm
that offers a flexible solution for building teams of LLM agents to solve complex
tasks effectively. The approach, called Captain Agent, dynamically forms and manages
teams for each step of the task-solving process, utilizing nested group conversations
and reflection to ensure diverse expertise and prevent stereotypical outputs.Vector search is really good in understanding context and semantic similarity. It can uncover papers that are conceptually related to the query, even if they don’t explicitly contain the search terms.
Finally, we combine both search methods:
This is a crucial part of our RAG agent, making it possible to use both vector and graph databases.
composite_chain = prompt | llm | StrOutputParser()
answer = composite_chain.invoke({"question": question, "context": vector_context, "graph_context": graph_context})
print(answer)
> The paper "Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework"
talks about Multi-Agent. It proposes a framework that prompts LLMs to play different roles
in a problem-solving team and encourages different role-play agents to collaboratively solve
the target task. The paper presents empirical results demonstrating the effectiveness of the
proposed methods on two college-level science problems.By integrating graph and vector searches, we leverage the strengths of both approaches. The graph search provides precision and navigates structured relationships, while the vector search adds depth through semantic understanding.
This combined method offers several advantages:
- Improved recall: It finds relevant papers that might be missed by either method alone.
- Enhanced context: It provides a more nuanced understanding of how papers relate to each other.
- Flexibility: It can adapt to different types of queries, from specific keyword searches to broader conceptual explorations.
Summing it up
In this blog post, we have shown how to build a GraphRAG Agent using Neo4j and Milvus. By combining the strengths of graph databases and vector search, this agent provides accurate and relevant answers to user queries.
The architecture of our RAG agent, with its dedicated routing, fallback mechanisms, and self-correction capabilities, makes it robust and reliable. The examples of the Graph Generation and Composite Agent components demonstrate how this agent can tap into both vector and graph databases to provide comprehensive and nuanced answers.
We hope this guide has been helpful and inspires you to check out the possibilities of combining graph databases and vector search in your own projects.
The current code is available on GitHub.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



