
Using LangChain and Neo4j to Process YouTube Playlists and Perform Q&A Flow

Senior Software Developer, infinCUBE
8 min read

Learn faster with use of LangChain and Neo4j
Motivation
In a world of lengthy YouTube playlists, traditional learning can feel time-consuming and dull. Our motivation is to transform this process by making it dynamic and engaging. Rather than passively consuming content, I believe that sparking conversations can make learning more enjoyable and efficient.
Goal
Our goal is to revolutionize how people interact with YouTube playlists. Users will actively engage in dynamic conversations inspired by the playlist content. We’ll extract valuable information from video captions, process it, and integrate it into the Neo4j vector database. The conversational chain serves as a guide that leads users through a dialogue rooted in playlist content. My mission is to provide an interactive and personalized educational dialog, where users actively shape their learning journey.
Technologies Used
Embarking on the exciting journey of conversational AI requires a firm grasp of the technological foundations, that meet the needs of our mission. For our purpose, we use the synergy of two cutting-edge technologies: LangChain, an open-source framework simplifying the orchestration of Large Language Models (LLMs), and Neo4j, a robust graph database made for optimal node and relationship traversal.
LangChain serves as the backbone in our quest for seamless interaction with LLMs. Its open-source nature enables developers to easily create and use the capabilities of these expansive language models. In our demo application, LangChain acts as the provider of an interface and construction of a conversational chain.
At the heart of this interaction lies Neo4j, a graph database designed to unravel the complexities of interconnected nodes and relationships.
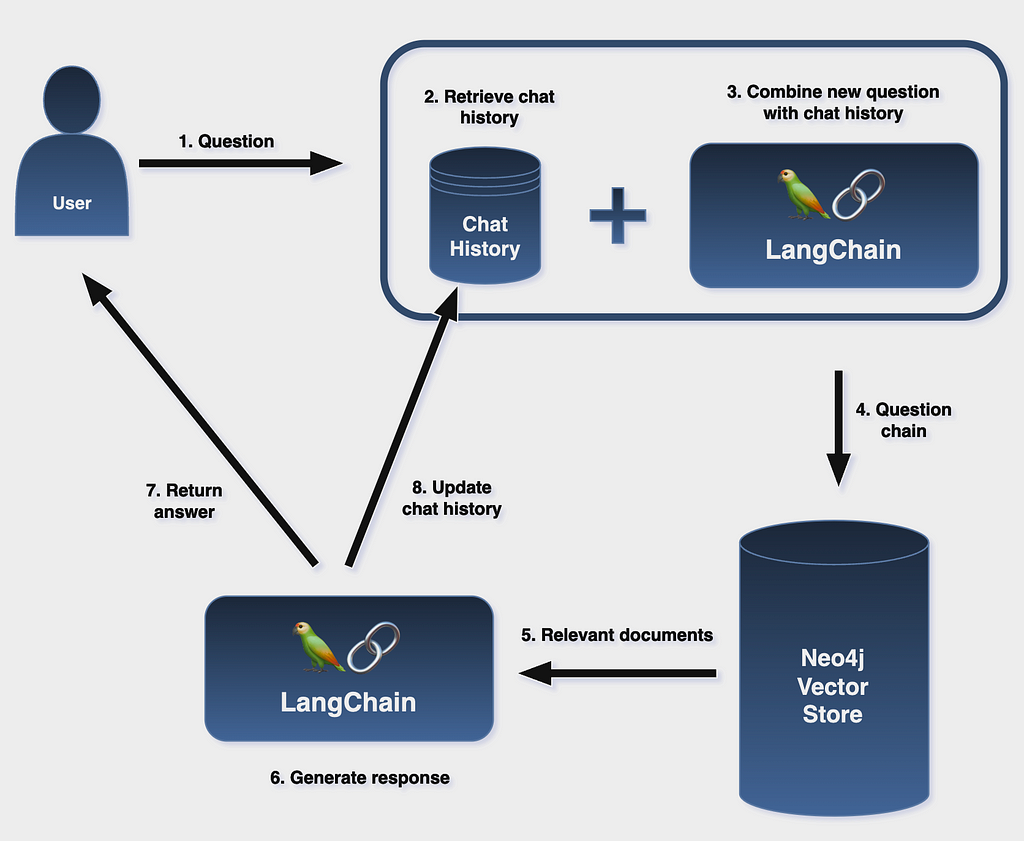
Picture this: a user initiates the conversation with a query, setting in motion a captivating exchange with our Large Language Model. The magic happens as the vector representation of the user’s input becomes a beacon for exploration within the Neo4j graph database.
The result? A seamless fusion of structured knowledge and natural language understanding, culminating in a response that is not just accurate but deeply connected to the context of the user’s inquiry.
Recognizing the importance of user experience, we introduce a conversational memory chain. Imagine a conversation where every question asked and every answer given becomes part of an evolving dialogue. This approach ensures that the interaction remains clear and coherent.
By feeding all past questions and answers into the conversational memory chain alongside the latest query, we create a continuous narrative thread. The result? A more engaging, relevant, and user-centric conversation that evolves intelligently with each interaction.
What will I cover in this tutorial
1. Processing of YouTube playlists; reading captions
2. Splitting each video caption into documents
3. Feeding documents into Neo4j database
4. Constructing a conversational retrieval chain
5. Performing queries
All of the code that is written in this article can also be accessed and viewed inside Python notebook on my GitHub repository here.
To be able to finish this demo, we have to first install all of the required packages:
pip install langchain neo4j openai tiktoken pytube youtube_transcript_api
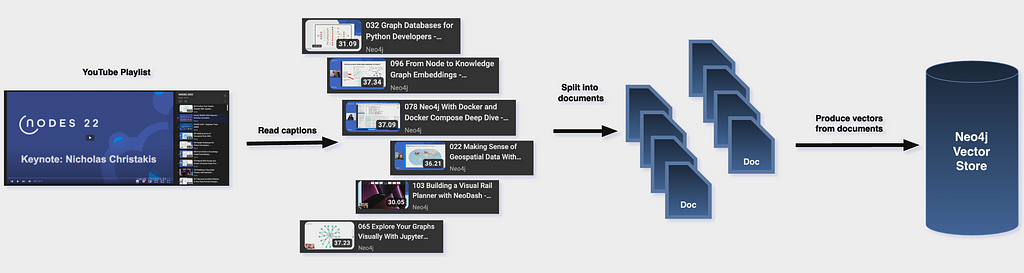
Processing of YouTube playlists
Use Playlist package to retrieve all video IDs that are inside the given playlist. For every video, using YouTubeLoader, extract caption documents. Feed each document into a text splitter. It is important to clear and preprocess the data before feeding it into text splitters. In our case, we ensured that we only considered English captions.
The size of each chunk varies and should be set based on the nature of the documents. Smaller chunks, up to 256 tokens, capture information more granularly. Larger chunks provide our LLM with more context based on the information within each document. In our case, I decided to use a chunk size of 512. This decision was made because context is more important, so we ensure contextual connection over multiple videos.
# Process all videos from the playlist
playlist_url = "https://www.youtube.com/watch?v=1CqZo7nP8yQ&list=PL9Hl4pk2FsvUu4hzyhWed8Avu5nSUXYrb"
playlist = Playlist(playlist_url)
video_ids = [_v.split('v=')[-1] for _v in playlist.video_urls]
print(f"Processing {len(video_ids)} videos.")
# Read their captions and process it into documents with above defined text splitter
documents = []
for video_id in video_ids:
try:
loader = YoutubeLoader(video_id=video_id)
documents.append(loader.load()[0])
except: # if there are no english captions
pass
print(f"Read captions for {len(documents)} videos.")
# Init text splitter with chunk size 512 (https://www.pinecone.io/learn/chunking-strategies/)
text_splitter = TokenTextSplitter.from_tiktoken_encoder(chunk_size=512, chunk_overlap=20)
# Split documents
splitted_documents = text_splitter.split_documents(documents)
print(f"{len(splitted_documents)} documents ready to be processed.")
Feeding Documents Into Neo4j Database
As mentioned earlier, all the documents will be stored inside the Neo4j database. In return, we will obtain a vector index that will later be utilized in conjunction with LangChain. Creating a Neo4j database is fairly straightforward and can be done without any additional knowledge of how the database operates and functions.
Since we have already prepared all our documents and split them, we used the from_documents function, which accepts a List[Document]. To simplify this process even further, we could also use the from_texts function. However, in this case, we would lose control over documents. Therefore, I believe that from_texts should only be used when we quickly want to demonstrate an application.
Setting search_type to hybrid will allow us to search over keywords and vectors. Hybrid search combines results from both full-text search and vector queries which use different functions such as HNSW. To merge the results, a Reciprocal Rank Fusion (RRF) algorithm is used. Response at the end provides only one result set, which is determined by the RRF algorithm.
This combination of vector search with traditional search methods allows for more nuanced and contextually relevant search results, improving the accuracy and depth of insights. This approach is particularly useful in applications such as ours, where we have new answers every time.
# Contruct Neo4j vector
neo4j_vector = Neo4jVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=splitted_documents,
url=os.environ['NEO4J_URI'],
username=os.environ['NEO4J_USERNAME'],
password=os.environ['NEO4J_PASSWORD'],
search_type="hybrid"
)
Constructing a Conversational Retrieval Chain
A conversational chain will be used to facilitate the Q&A flow. Setting k to 3 signals our retrieval chain to retain the last 3 messages in memory. These three messages will be passed to the LLM while performing queries. Adjusting this value will provide the LLM with more context during the Q&A flow. For retrieval, we will use the Neo4j vector instance generated earlier. Additionally, we set the maximum tokens (max_tokens_limit) to ensure that we stay within the specified limit.
Understanding the conversational retrieval chain is much easier if we split the process of asking a question and getting back the answer into three parts:
- Use the chat history and new question to create a “standalone question”. This is done so that this question can be passed into the retrieval step to fetch relevant documents. If only the new question was passed in, then relevant context may be lacking. If the whole conversation was passed into retrieval, there may be unnecessary information there that would distract from retrieval.
- This new question is passed to the retriever, and relevant documents are returned.
- The retrieved documents are passed to an LLM along with either the new question (default behavior) or the original question and chat history to generate a final response.
# Prepare Q&A object
chat_mem_history = ChatMessageHistory(session_id="1")
mem = ConversationBufferWindowMemory(
k=3,
memory_key="chat_history",
chat_memory=chat_mem_history,
return_messages=True
)
q = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0.2),
memory=mem,
retriever=neo4j_vector.as_retriever(),
verbose=True,
max_tokens_limit=4000
)
Now, it is time to ask some questions and to everything into action. First, we will ask a simple question that won’t require any information from previous answers (since we also do not have any). After that, a question will be asked that could only be answered if our conversational retrieval chain is working as it should.
# Perform Q&A flow - first question
response = q.run('What can you tell me about the GenAI stack?')
response
The GenAI stack is a framework and technology called Olama that is used for running language models (LLMs) on your local desktop or laptop. It is a collaboration between Neo4j, Langchain, and other parties. The GenAI stack makes it easier for developers to build LLM-backed applications by providing a pre-integrated environment with Neo4j and Langchain. It allows developers to leverage LLMs for various application features, such as chatbots or personalized email generation. The GenAI stack is designed to make it more accessible for developers to work with LLMs and incorporate them into their applications.
# Follow up question that requires previous answers (memory)
response = q.run('Who talked about it?')
response
Oscar and Harrison discussed the GenAI stack.
Again, all of the code can be viewed and accessed inside python notebook on my GitHub repository here.
Graph Representation
Neo4j Aura database offers us a workspace, where we can run Cypher queries and have a graphical presentation of the graph that is being constructed during our interactions. To showcase how this conversation history chain is presented, we can take a look at the following graph.
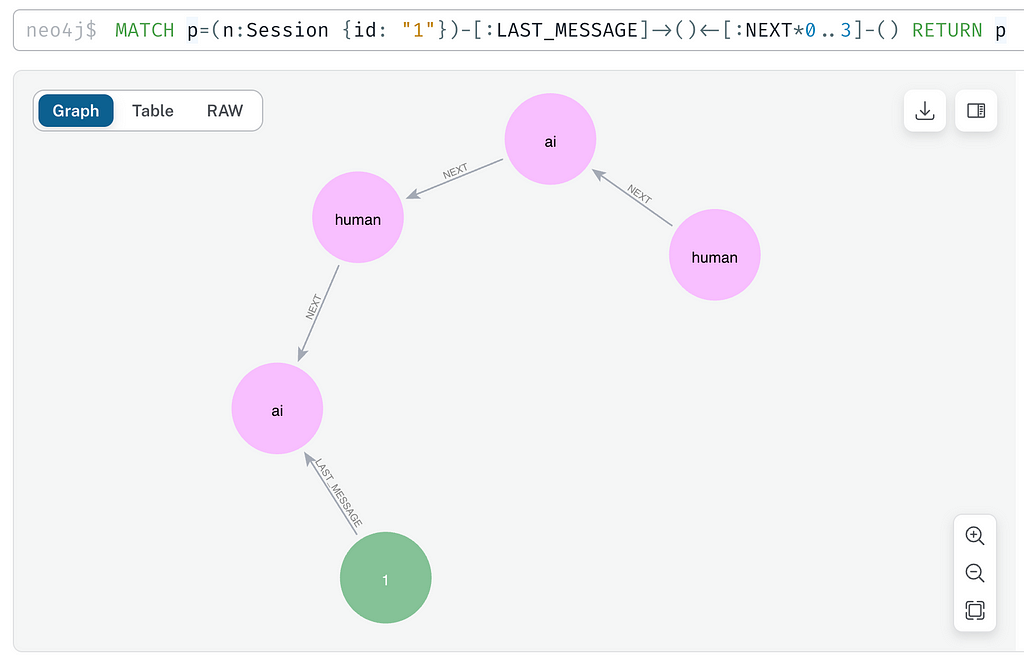
The above graph was displayed by executing the following Cypher query:
MATCH p=(n:Session {id: "1"})-[:LAST_MESSAGE]->()<-[:NEXT*0..3]-()
RETURN p
Chat history is represented as two types of nodes: an ai and a human node. Each of these nodes is connected with a NEXT connection that forms a chain relationship. Each node has its id and content. There is also our main session node, which has a LAST_MESSAGE connection to the last message that was returned by the ai. By following the chain, we can see how questions were asked by the human and how responses were returned by the ai. The above graph was constructed when we ran two questions from above.
Conclusion
In summary, our mission involved transforming YouTube learning by fostering dynamic conversations. We processed YouTube playlists using the Playlist package to extract video IDs and obtained caption documents through YouTubeLoader. Data preprocessing ensured consideration of only English captions, and text splitters handled document chunks. With a chunk size of 512, we prioritized context, crucial for maintaining connections across multiple videos.
To facilitate a Q&A flow, a conversational chain with a retrieval chain (k set to 3) was employed. This retention of the last 3 messages aided the Language Model (LLM) in contextual understanding during queries. Retrieval leveraged a Neo4j vector instance generated earlier.
The conversational retrieval chain involved creating a “standalone question” from the chat history and a new question. This question was then passed to the retriever, which returned relevant documents. Finally, the LLM, given the retrieved documents and either the new or original question with chat history, generated a comprehensive response.
Disclaimer: This article was written with the help of ChatGPT.
Using LangChain in Combination With Neo4j to Process YouTube Playlists and Perform Q&A Flow was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling



Text2Cypher Across Languages: Evaluating Foundational Models Beyond English

