Building RAG applications with the Neo4j GenAI stack: a comprehensive guide

Field Engineer, Neo4j
12 min read

The GenAI stack—A brief overview
Since the release of Neo4j’s GenAI Stack, the platform has garnered significant attention for its innovative approach to Generative AI (GenAI) application development.
The GenAI Stack is a pre-built development environment created by Neo4j in collaboration with Docker, LangChain, and Ollama. This stack is designed for creating GenAI applications, particularly focusing on improving the accuracy, relevance, and provenance of generated responses in LLMs (Large Language Models) through Retrieval Augmented Generation (RAG).
Below are key features of GenAI Stack:
- Information Retrieval Enhancement: GenAI Stack employs RAG to provide additional context at query time, improving the response quality of LLMs.
- Components: It includes application containers with Python and LangChain, a database container with Neo4j for vector index and graph search, and an LLM container with Ollama.
- Functionality: Users can import and embed data, perform queries using vector and graph search, and generate new content in the style of existing high-quality data.
- Trust and Verification: RAG applications within GenAI Stack can provide sources used to generate answers, offering an additional layer of trust and verification compared to traditional LLM responses.
In this post, I’d like to provide a quick reference on how to take advantage of Neo4j, a native graph database with vector search support in LangChain.
Quick index
- What’s available in LangChain for Neo4j? => 2. Neo4j Components in Langchain
- Where to download the project? => http://github.com/docker/genai-stack
- How to configure LLMs for embedding, and generation? => 3. Configuration
- Where do I specify the Neo4j URL and credentials? => 3. Configuration
- Can I change the parameters of LLM? => 4. Change of Parameters
- How to use Neo4j as the knowledge store? => 5. Initialize Neo4jVector Store
- How to specify the database name, index name, or embedding node label and property name? => 5. Initialize Neo4jVector Store
- What retrieval types are supported? => 6. Built-in Search Types
- I only have documents; how should I start? => 7. iv. Methods of Neo4jVector Initialization: from_documents
- I already have a Neo4j knowledge graph; how should I start? => 7. i. from_existing_index (no index creation), or 7. v. from_existing_graph (auto index creation)
- What exactly is VECTOR retrieval doing? => 11. Query Related to Retrieval/Search Types
- What is Hybrid Search/Retrieval, and how it works? => 11. Query Related to Retrieval/Search Types
- How to make my own prompts? => 12. Define Prompt Template
- How to create my own RAG QA chain using vector search? => 13. Initialize a Base QA Chain Instance, 14. Initialize A RAG QA Chain
- How to create a customized retriever, e.g., a structure-aware retriever? => 15. Customize Retrieval Strategy
- How to send user input to the Neo4j RAG chain to generate output? => 16. Generate Answers
- What other retrieval strategies are available? => 17. Advanced RAG Strategies
- Where can I find useful LangChain templates? => 17. Advanced RAG Strategies
- Can I generate a Cypher query and execute it in LangChain? => 18. Query Neo4j Graph Database
- How to create a RAG QA chain by executing a generated Cypher query? => 19. Generate Cypher Query from Question
Deep dive into components
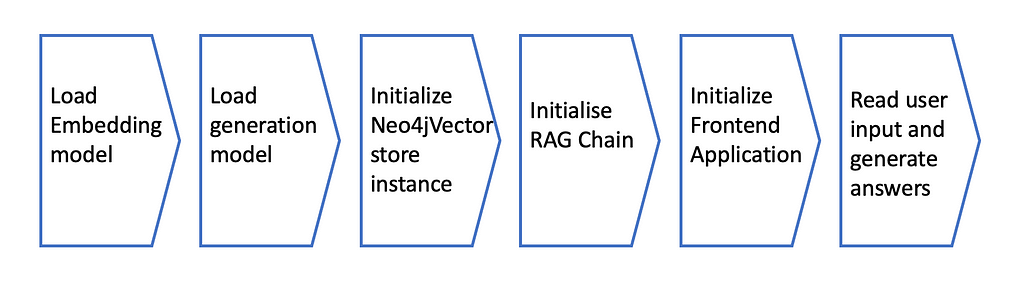
1. Typical process for RAG applications
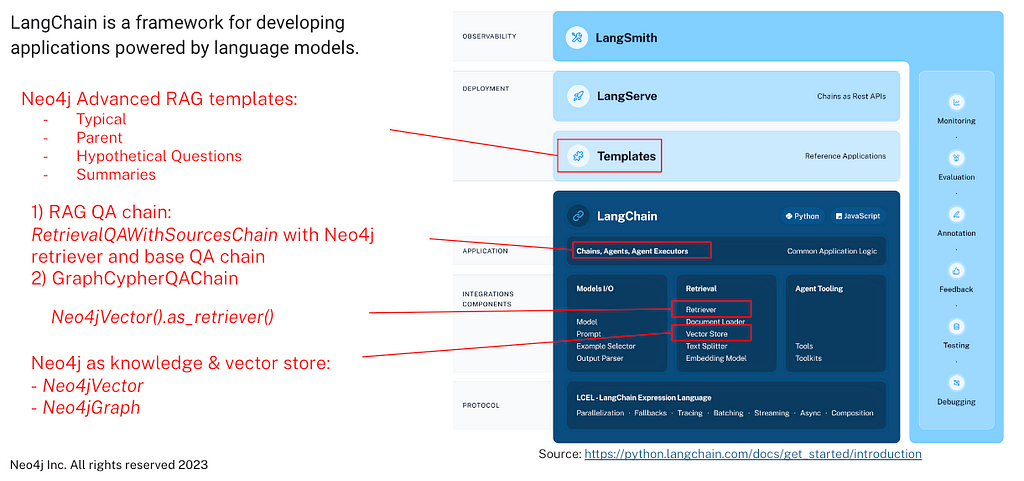
2. Neo4j components in LangChain
3. Configuration
In the GenAI Stack project folder, look for and copy the env.sample file into a .env file, and then make the necessary changes:
OPENAI_API_KEY=sk-YOUR-OPENAI-KEY
#OLLAMA_BASE_URL=http://host.docker.internal:11434
NEO4J_URI="neo4j+s://AURADB-INSTANCE:7687"
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=AURADB-PASSWORD
NEO4J_DATABASE=neo4j
LLM=gpt-4
EMBEDDING_MODEL=openai
LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
# LangSmith account requried if tracing is enabled
LANGCHAIN_TRACING_V2=false #true/false
LANGCHAIN_PROJECT=#your-project-name
LANGCHAIN_API_KEY=#your-api-key ls_...
4. Change parameters of LLM
In chains.py, check the code in the load_llm() procedure. For the current version, there are three LLMs supported:
- gpt-4
- gpt-3.5 (gpt-3.5-turbo)
- any other LLM enabled by Ollama
You’ll need to update the code here in order to use newer versions of GPT-4 models, e.g., gpt-4–32k, gpt-4–0613, etc., or other LLMs.
5. Initialize Neo4jVector store
Neo4jVector is the main class for the store. There are various ways to initialize an instance of Neo4jVector, and below are common parameters:
- embedding: Embedding model
- search_type: default is SearchType.VECTOR
- username: Neo4j database user name
- password: Neo4j database password
- url: vector store URL, in this case it’s Neo4j DBMS url.
- keyword_index_name: Optional, fulltext index name in Neo4j.
- database: database name. On Aura, it is always neo4j. For on-prem employment, it can be another database name except system.
- index_name: Optional, vector text index name in Neo4j.
- node_label: label of nodes with property storing text corpus, e.g., Sentence.
- embedding_node_property: Node property that stores text embeddings.
- text_node_property: Node property which stores text corpus.
- distance_strategy: similarity method for vector search, default is DistanceStrategy.COSINE.
- logger: Optional, only needed when LangSmith or other logging service is used.
- pre_delete_collection: default is False, If True, will delete existing data if it exists.
- retrieval_query: Optional, used for special retrieval strategy.
- relevance_score_fn: Optional, the normalization function for scores of matched items.
Implementation of Neo4jVector is in neo4j_vector.py, which is inherited from LangChain VectorStore.
6. Built-in search types
In neo4j_vector.py:
class SearchType(str, enum.Enum):
"""Enumerator of the Distance strategies."""
VECTOR = "vector"
HYBRID = "hybrid"
DEFAULT_SEARCH_TYPE = SearchType.VECTOR
7. Methods of Neo4jVector initialization
Common usage:
kg = Neo4jVector.*initialize_method(*params)
initialize_method is one of the following procedures.
i. from_existing_index
Get instance of an existing Neo4j vector index. This method will return the instance of the store without inserting any new embeddings.
ii. from_texts
Parameters:
- texts: List[str]
- embedding: Embedding model
Return Neo4jVector initialized from texts, generate and save embeddings.
iii. from_embeddings
text_embeddings: List[Tuple[str, List[float]]]
Construct Neo4jVector wrapper from raw documents and pre-generated embeddings.
iv. from_documents
Return Neo4jVector initialized from documents and embeddings. Documents are instances of Document class as per LangChain.
v. from_existing_graph
This method initializes a Neo4jVector instance using the provided parameters and the existing graph. It validates the existence of the indices and creates new ones if they don’t exist.
8. Neo4j retriever
Neo4jVector.as_retriever() return an instance of class VectorStoreRetriever, which is inherited from LangChain BaseRetriever.
9. Load embedding model
embeddings, dimension = load_embedding_model(
embedding_model_name, config={"ollama_base_url": ollama_base_url}, logger=logger
)
10. Load generation model
llm = load_llm(llm_name, logger=logger, config={"ollama_base_url": ollama_base_url})
11. Query related to retrieval/search types
SearchType.VECTOR: (
"CALL db.index.vector.queryNodes($index, $k, $embedding) YIELD node, score "
),
SearchType.HYBRID: (
"CALL { "
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
"RETURN node, score UNION "
"CALL db.index.fulltext.queryNodes($keyword_index, $query, {limit: $k}) "
"YIELD node, score "
"WITH collect({node:node, score:score}) AS nodes, max(score) AS max "
"UNWIND nodes AS n "
"RETURN n.node AS node, (n.score / max) AS score " # We use 0 as min
"} "
"WITH node, max(score) AS score ORDER BY score DESC LIMIT $k " # dedup
),
}
12. Define prompt template
Usually there are two parts required in a prompt: system message and user message. Below are lines from procedure configure_qa_rag_chain in chains.py:
general_system_template = """
Use the following pieces of context to answer the question at the end.
The context contains question-answer pairs and their links from Stackoverflow.
You should prefer information from accepted or more upvoted answers.
Make sure to rely on information from the answers and not on questions to provide accuate responses.
When you find particular answer in the context useful, make sure to cite it in the answer using the link.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----
{summaries}
----
Each answer you generate should contain a section at the end of links to
Stackoverflow questions and answers you found useful, which are described under Source value.
You can only use links to StackOverflow questions that are present in the context and always
add links to the end of the answer in the style of citations.
Generate concise answers with references sources section of links to
relevant StackOverflow questions only at the end of the answer.
"""
general_user_template = "Question:```{question}```"
messages = [
SystemMessagePromptTemplate.from_template(general_system_template),
HumanMessagePromptTemplate.from_template(general_user_template),
]
qa_prompt = ChatPromptTemplate.from_messages(messages)
13. Initialize a base QA chain instance
For a base QA chain, all that is needed is:
- a generation model, e.g., OpenAI (=>3.10)
Check procedure configure_llm_only_chain in chains.py.
14. Initialize a RAG QA chain
For a RAG chain, since it needs to retrieve a knowledge store and provide results as context to prompts, there are more things required:
- initialize a RetrievalQAWithSourcesChain, which is inherited from the BaseCombineDocumentsChain instance
- embedding model => 3.9
- Neo4jVector store=> 3.5
- prompt template (ChatPromptTemplate instance) => 3.12
Check procedure configure_qa_rag_chain in chains.py.
// 0. Prepare
llm = load_llm(llm_name, logger=logger, config={})
embeddings, dimension = load_embedding_model(
embedding_model_name, config={}, logger=logger
)
// 1. Initialize document chain
qa_chain = load_qa_with_sources_chain(
llm,
chain_type="stuff",
prompt=qa_prompt,
)
// 2. Initialize Neo4jVector
kg = Neo4jVector.from_existing_index(
embedding=embeddings,
url=embeddings_store_url,
username=username,
password=password,
...
)
// 3. Initialize RAG chain
kg_qa = RetrievalQAWithSourcesChain(
combine_documents_chain=qa_chain,
retriever=kg.as_retriever(search_kwargs={"k": 2}),
reduce_k_below_max_tokens=False,
max_tokens_limit=3375,
)
15. Customize Retrieval Strategy
This is simply done by sending a retrieval_query parameter when initializing the Neo4jVector store (=> 3.5). The retrieval_query takes returned items and their similarity scores and applies extra logic for re-ranking and/or filtering.
In my previous post, there is a sample implementation of structure-aware retrieval that followed this approach.
Adding Structure-Aware Retrieval to GenAI Stack
16. Generate answers
Check cs_bot.py for samples.
result = kg_qa(
{"question": user_input, "chat_history": []},
callbacks=[callback_handler]
)["answer"]
Behind the scenes, the procedure get_relevant_document of the LangChain BaseRetriever class is called to retrieve documents relevant to a query.
def get_relevant_documents(
self,
query: str,
*,
callbacks: Callbacks = None,
tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None,
run_name: Optional[str] = None,
**kwargs: Any,
) -> List[Document]:
Args:
- query: string to find relevant documents for
- callbacks: Callback manager or list of callbacks. For example, a StreamHandler from Streamlit.
- tags: Optional list of tags associated with the retriever. Defaults to None. These tags will be associated with each call to this retriever, and passed as arguments to the handlers defined in `callbacks`.
- metadata: Optional metadata associated with the retriever. Defaults to None. This metadata will be associated with each call to this retriever, and passed as arguments to the handlers defined in `callbacks`.
17. Advanced RAG strategies
LangChain Templates offers a collection of easily deployable reference architectures that anyone can use. This is a new way to create, share, maintain, download, and customize chains and agents. They are all in a standard format that allows them to easily be deployed with LangServe, allowing you to easily get production-ready APIs and a playground for free.
The neo4j-advanced-rag template allows you to balance precise embeddings and context retention by implementing advanced retrieval strategies.
Available Strategies
- Typical RAG: Traditional method where the exact data indexed is the data retrieved.
- Parent retriever: Instead of indexing entire documents, data is divided into smaller chunks, referred to as Parent and Child documents. Child documents are indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
- Hypothetical Questions: Documents are processed to generate potential questions they might answer. These questions are then indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
- Summaries: Instead of indexing the entire document, a summary of the document is created and indexed. Sometimes, this is referred to as metadata of documents.
The blog post from my colleague Tomaz Bratanic details advanced retrieval strategies.
Neo4j x LangChain: Deep dive into the new Vector index implementation
18. Query Neo4j graph database
Neo4jGraph is the class for executing any Cypher query, including index creation, data load, and retrieval. It is inherited from the GraphStore class in LangChain.
19. Generate Cypher query from question
Use GraphCypherQAChain in LangChain. You’ll need:
- A Neo4jGraph instance => 3.18
- LLM for Cypher generation, e.g., LLM finetuned for code generation like Code Llama.
- LLM for NLU
- Prompt template
The example below uses VertexAI services:
from langchain.chains import GraphCypherQAChain
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=VertexAI(model_name='code-bison@001', max_output_tokens=2048, temperature=0.0),
qa_llm=VertexAI(model_name='text-bison', max_output_tokens=2048, temperature=0.0),
cypher_prompt=CYPHER_GENERATION_PROMPT,
verbose=True,
return_intermediate_steps=True
)
Summary
The GenAI Stack facilitates experimentation with various approaches to knowledge retrieval and summarization, aiding developers in creating more accurate and relevant responses for users through a streamlined environment for rapid development, testing, and deployment of GenAI applications.
The intention of GenAI Stack is to offer developers a robust and efficient platform for creating sophisticated GenAI applications, which represents a significant advancement in the realm of GenAI.
Any questions or comments are welcome! Feel free to message me on LinkedIn.
Neo4j GenAI Stack for Efficient LLM Applications: A Quick Guide was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


