Build AI agents that make better decisions on GCP with Neo4j

Head of Product Innovation & Developer Strategy, Neo4j
21 min read
Modern agentic systems have long moved beyond the simple ReAct loop — now they are integrated into enterprise architectures with access to vast organizational data, higher requirements for security, auditability and provenance and tasked with more and more complex jobs to complete reliably.
In this article, you will learn how you can use the Graph Intelligence Platform capabilities to build such agentic systems on Google Cloud.
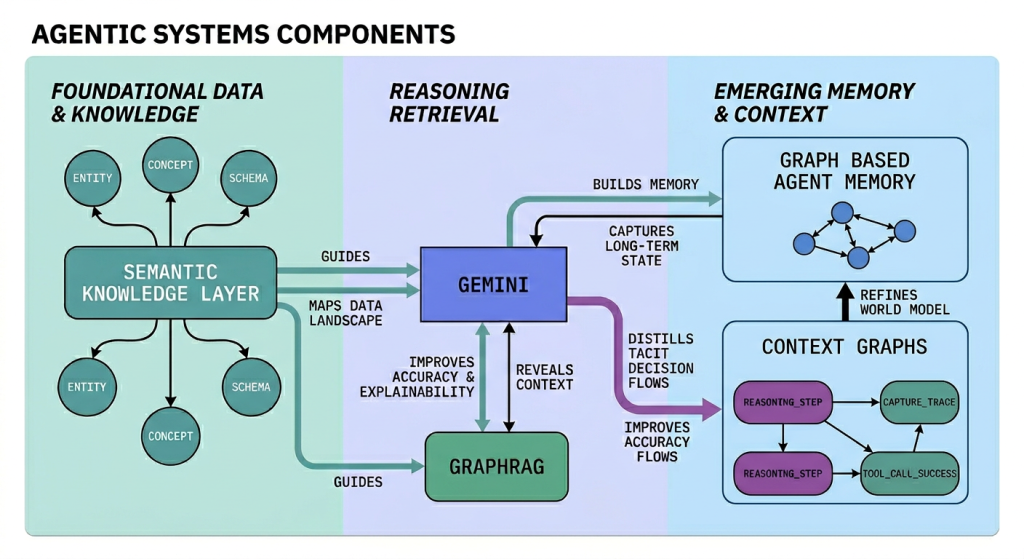
We will also dive into the underlying architectural details and components of modern agent systems. Using the latest reasoning models from Gemini, the agent operations are improved by a variety of context engineering techniques. Contextual retrieval with GraphRAG — which improves explainability, traceability and accuracy of your agents. A Semantic Knowledge Layer guides the agent in a complex enterprise data and system landscape to surgically determine the sources and tools for accessing the right data and APIs to achieve reliable and efficient task completion. Graph based agent memory doesn’t just store conversations in short term memory but builds up a world model of the user, their environment and jobs to be done with structured long-term memory that is tied to the organization’s domain. Capturing traces of agent reasoning, tool calls, and success of task completion creates a rich source to be distilled into Context Graphs which represent the so far underutilized tacit decision flows of organizations that go beyond explicit business rules.

Using GCP native services allowed us to build and operate the control and data-planes for the Aura Database Platform effectively that forms the underlying graph engine of the knowledge layer.
The Graph Intelligence capabilities — Agents with GraphRAG tools, MCP, Agent Memory, Document Intelligence, Assistants and Natural Language Querying are benefitting from the power of the Vertex AI platform with Gemini, ADK and model training and hosting.
Behind every intelligent agent is a hidden, sturdy foundation. The journey from a simple demo to a production-ready agentic system is rarely about the model alone; it’s about the environment that surrounds it. This article dives into how you can build a production-grade agentic infrastructure on top of GCP and Neo4j, ensuring your agents have the memory, security, and reasoning capacity to handle truly complex organizational tasks.
The graph knowledge layer for navigable, explainable AI
Any successful AI project starts with the right data. As we all know, Enterprise AI data isn’t just a single pile of documents. There are many systems, each with its own shape, language, and access rules.
To navigate them, an agent needs to know where each piece of information lives and what each piece means in the context of the task at hand. That navigation layer is the semantic layer. It describes the data systems as ontologies, metadata, provenance, and policies, in a form that agents can consume.
In the actual data layer below we see three different types of data with specific update frequencies, relevancies and interactions. At the core is the organizational knowledge: customers, products, policies, organizational structure, contracts, and data lineage. This is the stable world the agent needs to know, and it underpins daily operations: planning, orders, approvals, production control, transactions, which are running in a fast-moving context — the current session, in-flight requests, live telemetry, the specific decision the agent is about to make.
Many decisions that happen in the system are guided by business rules, but a large fraction is also made ad-hoc, where the underlying reasoning is traditionally not made available. In this knowledge layer the decisions (made by humans and increasingly by agents), the reasoning that produced them, and the outcomes that followed are captured, processed and become accessible.
Collapsing all of that into a disconnected data system loses the relationships, the provenance, and the structure that makes the data navigable in the first place. A graph-powered knowledge layer keeps the structure. Entities and their typed relationships are first-class, and vector embeddings can serve as entry points into the graph.

The boundary between “knowledge” and “context” becomes a design choice rather than a storage format.
Build more accurate retrieval: From vectors to GraphRAG
A typical vector search integration works with chunks, embeddings, and a top-k lookup. That approach is adequate for single-document question answering. Beyond that, accuracy degrades quickly, and production systems layer on additional techniques (reranking, query rewriting, hybrid search, contextual embeddings) to recover it.
A search for “late-payment penalty” returns five chunks that all mention late payments, none of which are the governing clause in the contract the user is asking about. A question that needs multiple facts joined (a contract, the counterparty it binds, and the jurisdiction it falls under) degrades into separate vector searches with disconnected results.
GraphRAG replaces the flat top-k with a combined retrieval. A hybrid semantic search (vector plus fulltext) resolves the question to a small set of entry points in the graph. A Cypher traversal then expands over several hops from those entry points to gather the entities, relationships, and provenance the agent needs.
Every fact the deterministic retriever returns comes back with a path: which entry point it started at, which patterns it followed, which document it was grounded in. The Essential GraphRAG book and graphrag.com cover the pattern in depth, including improvements in accuracy, explainability and reliability.
A vector search on the Clause embedding opens the traversal. From there, (Clause)-[:PART_OF]->(Contract)-[:SIGNED_BY]->(Party) pulls in governing law, effective dates, and neighbouring clauses in the same document. The agent receives a structured record with the matched clause, its parent contract, the parties, and the related clauses. Each of which can point back to it source information for further investigation.
The new vector SEARCH syntax lets the semantic search, its filters (extracted from “only active contracts under English law”), and the graph expansion live in the same Cypher statement.
MATCH (contract:Contract)
SEARCH contract IN (
VECTOR INDEX contracts FOR $embedding
WHERE contract.status = 'active'
AND contract.jurisdiction = $jurisdiction
LIMIT 5
)
MATCH (contract)-[:SIGNED_BY]->(party:Party),
MATCH (contract)-[:SOURCED_FROM]->(doc:Document)
MATCH clauses = (contract)-[:RELATED_TO*1..2]-(:Clause)
RETURN contract, party, doc, collect(clauses)
Aura Agents package these retrieval patterns as a managed tool set into a low-code architecture running inside the trusted Aura infrastructure.
Aura Agents: Trusted low-code GraphRAG
Any team that wants to democratize natural language access to their knowledge graph through a grounded GraphRAG agent can use Aura Agents to do so. The easiest way to get started is to let the LLM configure a draft agent with instructions and tools from your description and the database schema.
An Aura Agent is built from the same three tool types introduced above:
- Vector search tools. Resolve a question to its closest entry points on a chosen index, as a possible entry into the traversal.
- Parameterized Cypher templates. Carry the deeper, known traversals: “given this clause, return the parent contract, its parties, and any related obligations.” The agent extracts and fills in the parameters as needed from the user information or the context.
- Text2Cypher tools. Translate free-form natural-language questions from the user or agent into Cypher using the live database schema, for tasks that do not match any dedicated template.
Reasoning runs on the latest Gemini models served from Vertex AI. The agent runtime analyses the task, deconstructs it into sub-tasks and extracts parameters. Then, each turn reasons which tools to use to gather the relevant information (also multiple in parallel), observes the results, and, if needed, expands or rephrases the subtask and iterates until the answer can be generated. All reasoning and tool call interaction details are available in the admin UI and the APIs.
The Text2Cypher tool runs on a Neo4j fine-tuned Gemini model hosted on Vertex AI, trained on the Cypher dialects, schema conventions, and idioms, and it generates queries against the actual database schema introspected at request time. The same model powers the natural-language query functionality across the Aura experience (Query, Explore, Dashboards, Onboarding Assistant), so an agent using the model inherits the same query behaviour as an analyst interacting with the graph tools — with some additional error handling and refinement built into the autonomous agent.
All Aura Agent components (reasoning, agent-loop, retrieval, Text2Cypher endpoint, MPC/API) run inside the Aura trust boundary on Neo4j-managed Google Cloud infrastructure. Database content does not leave that boundary on its way to a third-party model.
An Aura Agent can be imported and exported via a JSON representation, so its instructions, database, tools, parameters, schema bindings, and prompts can be versioned and then later recreated or updated via API
The Aura Agent UI and the schema-aware Create with AI bootstrapping are a great way to get started and test your agent interactively; the APIs are where you can take it to production.

Part of the APIs integration is exposing an agent via REST or MCP. Public Aura Agents APIs are a paid Aura capability that needs to be explicitly enabled. A configured agent is reachable over REST for direct HTTP integration and over MCP so any MCP-compatible client can call it as one of its tools.
Agent-to-Agent (A2A) support is on the roadmap and will enable an Aura Agent to participate in Google’s A2A protocols for tighter integration with ADK and Gemini Enterprise agents.
Today Aura Agents can be used with Free, Pro and Business Critical tiers. In the near future you will be able to take advantage of integrated agent memory and Aura Agent availability in virtual dedicated cloud environments,
For an end-to-end example on the contract domain used throughout this article, see the Context-Aware GraphRAG Agent blog post and the knowledge-graph-agent repository, which explain the schema, the tool definitions, and the full agent configuration, integration, and usage.

A live production example of the Aura Agent surface is also available. The Aura Onboarding Assistant uses an Aura Agent sitting on top of a Neo4j documentation knowledge graph, with GraphRAG retrieval across docs, tutorials, and reference material. New and existing users can ask it how to size an instance, pick a driver, or model their first domain, and it answers against the indexed documentation with explanations, code examples, generated Cypher queries and links back to every source page to which an answer is grounded.

Semantic layer: Help agents choose the right data & resources
Jason Liu frames context engineering as the ability of agents to navigate a complex information space. That also applies to the challenges of navigating a large enterprise data space. A semantic layer creates a navigable map of the organizational landscape (a sprawl of databases, APIs, document stores, BI models, permission systems, and their policies) and shapes it into a graph that the agent systems can search and traverse to inform their plans and reasoning while breaking down a task and before choosing sequences of the relevant tools.
In that graph, the first-class objects are not the data rows themselves but the metadata an agent needs to know about the data to act on it:
- Entities and ontology. The business concepts (customer, product, contract, account) and how they relate, independent of which system currently stores them.
- Schemas and lineage. Tables, columns, and their evolution, with lineage edges pointing back at the upstream sources and forward at the downstream consumers.
- APIs and tool descriptions. For each callable surface, entities the agent can inspect: what it returns, what it costs, what it is trusted for, and which ontology entities it resolves.
- Ownership, access, and freshness. Who owns each source, who is allowed to read it, how recently it was updated, and how reliable the last refresh was.
Tool selection becomes informed by a graph traversal. From the entities in question, through the ontology, to the schemas and APIs that hold those entities, filtered by access rights and freshness. An agent facing thirty tools uses the relevant handful per turn and subsequent data-dependent tools, the same way a developer reads a data catalogue before writing a query.
Neo4j financial services customers run such a stack on Google Cloud. BigQuery holds the analytics data, Dataplex the catalog and governance, Collibra the business glossary, LookML the semantic model, with Looker dashboards and Gemini-powered agents on the consumption side. A Neo4j graph spans all of it, so an agent traverses from an entity in question to the right LookML view, confirms the glossary term, checks lineage, and only then issues the Looker query against BigQuery.
Google’s MCP Toolbox for Databases, which has long-time support for Neo4j fits the callable tool side of this picture. It exposes parameterized database queries as an MCP tool and a resource endpoint, so each tool node in the semantic graph could point directly at an executable surface the agent invokes through the same MCP machinery used elsewhere in the stack.
You can find more on our AI Systems page and the Uber architecture deep dive.

Graph memory: Build stateful, explainable agents
Agents have a memory problem. A conversation from last week is unreachable. Half a dozen agents deployed across an organization cannot share what they have learned. When something goes wrong, there is no audit trail explaining why the agent made that decision.
Fixing this takes three distinct memory types, each holding a different kind of state:
- Short-term memory. The current session and its recent turns. Messages, the user’s last request, the assistant’s last response, and any transient state the agent built up during the turn.
- Long-term memory. Structured facts about the entities the agent encounters over time. Customers, products, policies, user/org preferences, and the relationships between them, with temporal, confidence, and sourcing attributes so facts can be asserted, invalidated, and superseded.
- Reasoning memory. The decision traces themselves. Which tools the agent called, which evidence it retrieved, which reasoning step led to which action, and whether the outcome was accepted, reversed, or escalated.

Most existing graph-backed memory systems cover the first two types of memory. Without reasoning memory, several things break: an agent cannot explain a past decision, a team cannot learn from past outcomes, and someone investigating problems cannot reason why the agent took an unexpected path.
Keeping all three memory types in a single graph provides a significant payoff. A single traversal spans from a conversation turn to the entities it mentions, to the tool calls it triggers, to the reasoning step that chose them, to the decision and the outcome that follow.
Implement graph memory with neo4j-agent-memory
neo4j-agent-memory is the Neo4j Labs library that implements this model. Open-source Python, Go, Typescript, built from the patterns Neo4j developed with customers and users running agents in production. It can be configured with custom schemas for extraction, integrates with major agent frameworks and agent platforms, and stores the full context graph in Neo4j. For Google Cloud specifically, the library ships a Neo4jMemoryService integration that slots into ADK’s memory hook, so an ADK agent gets all access to all three memory types without writing extraction or schema code.
from neo4j_agent_memory import MemoryClient, MemorySettings
from neo4j_agent_memory.integrations.google_adk import Neo4jMemoryService
async with MemoryClient(settings) as client:
# Create memory service
memory_service = Neo4jMemoryService(
memory_client=client, user_id="user-123",
include_entities=True, include_preferences=True,
)
# Store a conversation session
session = {
"id": "session-1",
"messages": [
{"role": "user", "content": "I always want to use Gemini Flash for speed and cost reasons."},
{"role": "assistant", "content": "Noted!"},
]
}
await memory_service.add_session_to_memory(session)
# Search across all memory types
results = await memory_service.search_memories(
query="user preferences", limit=10,
)
for entry in results:
print(f"[{entry.memory_type}] {entry.content}")
Graph memory as a managed service
We’re also launching a hosted Neo4j Agent Memory Service in Neo4j Labs. Visit memory.neo4jlabs.com to to try it out. We try to explore and learn about real-world usage patterns that feed back into the agent memory work, and to cover agent platforms that lack native extension points but can call out to a REST/MCP service during the agent lifecycle.

Context graphs: Improve agent decisions
Organizations run on tacit decision flows. Why does the ops team approve some late invoices? Which exceptions does the compliance officer waves through? When does an account manager escalate instead of discounting? None of it is written down. It lives in heads, Slack threads, phone calls, and hallway conversations. Business rules capture the explicit part. The rest is invisible to new participants.
That’s why agents start with a clean slate. An agent deployed into a new domain inherits the documents, schemas, APIs, and explicit rules. The tacit decision flow is inaccessible, because the people who hold it never had to articulate it.
A context graph captures these decisions (the “why”), the links to the entities and transactions. It makes them explicit and accessible for humans and agents alike. And it’s easier than ever to distill the context graph from agent traces.
Reasoning memory can be one of the raw materials for closing this gap. Every turn an agent runs leaves a full trace: the question shape, the tools it called, the evidence it retrieved, the reasoning step that chose each tool, the decision it reached, and the outcome (accepted, reversed, escalated, or confirmed by a human). Over weeks of agent activity, this accumulates into a corpus of decision paths with outcomes attached.
Running graph algorithms over that corpus allows us to surface the patterns the humans never wrote down. From frequent subgraph mining and path ranking to temporal analysis, clustering and centrality computation. All of them help distill and condense the essence of decisions.
Karpathy discussed including decision paths in reinforcement learning, not just the results for better outcomes. Decision traces in context graphs do that for agents during inference, and are updated whenever new data is integrated.
End-to-end visibility is the concrete payoff over flat logs. A flat log shows that the agent called bq.customer_lookup at 14:32. A context graph shows the full chain behind that one call in a single traversal:
// Full chain behind a single bq.customer_lookup call
MATCH (tc:ToolCall {name: 'bq.customer_lookup', id: $call_id})
<-[:CALLED]-(r:ReasoningStep)<-[:TRIGGERED]-(t:Turn),
(r)-[:LED_TO]->(d:Decision)-[:CITES]->(e:Evidence)
-[:RESOLVES_TO]->(c:Customer)
RETURN t.question, c.name, c.jurisdiction,
d.outcome, d.decided_at, d.reviewed_by
The call came from a reasoning step triggered by a user about to turn renewal risk. The evidence was resolved to a customer whose contract was governed by a specific jurisdiction. The decision was reversed two days later by the account manager. The same traversal answers the post-mortem question at scale:
// Reversed decisions in the last quarter that went through this tool
MATCH (d:Decision:Reversed)<-[:LED_TO]-(:ReasoningStep)
-[:CALLED]->(:ToolCall {name: 'bq.customer_lookup'}),
(d)-[:CITES]->(e:Evidence)
WHERE d.reversed_at > datetime() - duration('P90D')
RETURN e.source_type, count(DISTINCT d) AS reversal_count
ORDER BY reversal_count DESC
Eleven reversals in the past quarter, all sharing the same evidence-source pattern. The traversal that answered the agent’s question at inference time answers the post-mortem question a week later.
To make the pattern tangible, Neo4j Labs launched create-context-graph.dev, a scaffolding tool that generates runnable context-graph demos across 22 domains and several agent frameworks (including Google ADK). One command (uvx create-context-graph) produces a working project: a domain graph, a seeded reasoning-memory corpus, and an agent with a UI that reads the distilled patterns at inference time. The blog post Hands on with Context Graphs and Neo4j walks through the same shape in a standalone runnable example.

Integrating Neo4j with Google’s agent infrastructures
No matter where you build and run your agent systems, we want to ensure you can use the power of graphs anywhere. That’s why we have integrated Neo4j with all the agent platforms and frameworks, both for GraphRAG retrieval and agent-memory through MCP (Model Context Protocol) and bespoke extensions.
You can use Neo4j beginning with Google’s Agent Development Kit (ADK), all the way to the Gemini Enterprise Agent Platform.
MCP as an integration technology offers two advantages. First,- every agent system integrates with MCP, and second, the official Neo4j MCP server provides secure query execution against any Neo4j database.
Official Neo4j MCP server
The official Neo4j MCP server is our primary integration surface. It exposes schema introspection, read and write queries, and access to graph algorithms as MCP tools, and runs in both STDIO and HTTP mode. For cloud environments, a step-by-step guide walks through deploying it to Cloud Run. A hosted MCP server for Neo4j Aura will be launched later in this quarter.
Google ADK
Our example code shows you how to connect an ADK Agent to Neo4j, both through the official MCP server or dedicated tools for Cypher template queries. The same pattern works for local STDIO for testing, or remote HTTP mode against a Cloud Run deployment for production.
Neo4jMemoryService from neo4j-agent-memory extends directly into the ADK memory hook, so the three memory types are exposed in the agent runtime. Short-term memory clears at the end of the session. Long-term entities and reasoning traces persist across sessions.
Gemini Enterprise
Integrations with Gemini Enterprise utilize the A2A protocol, which is used for composing multi-agent systems. Provisioning happens through well-known agent cards or the agent marketplace. Neo4j ships several A2A integration patterns for Gemini Enterprise.
A2A MCP Wrapper: The A2A ADK agent and the Neo4j MCP server run as separately scalable Cloud Run services. OAuth authenticated natural language A2A invocations are translated and executed against Neo4j using the remote MCP tools. Here each MCP service is configured for a single graph database and needs to be routed accordingly.
A2A Direct Service: A single Cloud Run service bundles the ADK agent and the Neo4j driver, authenticates against Google Workspace, and can be configured per Gemini Enterprise installation for separate Neo4j database connections. This pattern fits an internal enterprise setup where teams want self-service onboarding and a fixed auth to corporate identity, with the flexibility of connecting to different Neo4j databases.

We are walking through the technical implementation details in our article on: Building a Neo4j Graph Agent for Gemini Enterprise.
Start building now or see it live at Google Cloud Next ‘26
You can put the technologies and infrastructures covered in the article into action today. Here are some additional resources to get you started
- Knowledge Graph and GraphRAG courses on GraphAcademy
- Free Essential GraphRAG Book
- GraphRAG Patterns Repository
- Google ADK with Neo4j
- Neo4j Agent Memory
- Gemini Enterprise Integrations
Google Cloud Next ’26, April 22–24, Las Vegas. Neo4j is at booth #2717. The team is running live demos of Aura Agents, the MCP server on Cloud Run, the three Gemini Enterprise A2A patterns, and a preview of other upcoming features. Book a slot in advance if a specific topic interests you, or walk up during the show.
NODES AI, April 15. The Graph AI Developer Conference runs this week before Google Next. Sessions are recorded and available on demand at neo4j.com/nodes-ai and cover KnowledgeGraphs & GraphRAG,GraphMemory & Agents, and Graph + AI in Production.
Build AI Agents That Make Better Decisions on GCP with Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


