Supply chains don’t fail at the node. They fail at the connection.


6 min read

Global supply chains have never been more exposed. Tariff shifts, geopolitical disruptions, and pandemic-era shortages have revealed a structural problem that most organizations already suspected but couldn’t see clearly: they know their tier 1 suppliers, but very few know what sits behind them. A component shortage at a tier 3 supplier, two steps removed from direct contact, can halt production before anyone has time to respond.
The data exists to prevent this. What most organizations lack is a system that connects them and turns that data into business intelligence. For business leaders, the value is faster visibility into risk and alternatives. For technical teams, the value lies in an architecture that combines Databricks’ governed lakehouse foundation with Neo4j’s graph-native capabilities to traverse, analyze, and reason across connected data.
The questions that supply chain managers can’t answer
The daily reality of supply chain management is a set of questions that current systems handle poorly or not at all. What materials are needed to produce a finished product, and what is the current inventory status of each? Which finished products consume a material that’s at risk? If a supplier is disrupted and takes four weeks to recover, what actions should the business take to limit the impact? If a key supplier goes down entirely, how long can production continue before demand is lost?
These aren’t edge cases. They’re the questions supply chain managers face every week, even every day. The reason they’re hard to answer isn’t a shortage of data. The answers require simultaneous reasoning across connected networks of suppliers, components, BOMs, inventory positions, and logistics routes. Traditional relational systems can store these entities, but multi-hop questions require repeated joins across suppliers, components, products, sites, and customers. As supply networks grow more complex, those queries become harder to model, maintain, and run fast enough for real-time disruption response.
Why the graph layer changes what’s possible
Multi-tier supplier risk is a traversal problem. A query like “which products are at risk if supplier A goes down, and which tier 2 suppliers now carry elevated load?” requires traversing supplier → component → BOM → product → customer relationships in a single pass. In SQL, that means three or four levels of self-joins, and the cost compounds with every hop. In Cypher, Neo4j’s native graph query language, the same query follows relationship pointers directly and can return in milliseconds.
Neo4j stores the supply chain network as a Knowledge Graph, with suppliers, components, BOMs, contracts, and logistics routes as connected entities queryable through Cypher. The graph structure also enables analysis that flat data can’t support. Centrality analysis identifies suppliers whose influence across the network far exceeds their direct order volume — the ones whose failure would cascade furthest. Community detection reveals hidden dependency clusters where multiple suppliers share the same upstream risk. Pathfinding returns qualified alternative sources the moment a primary supplier goes offline.
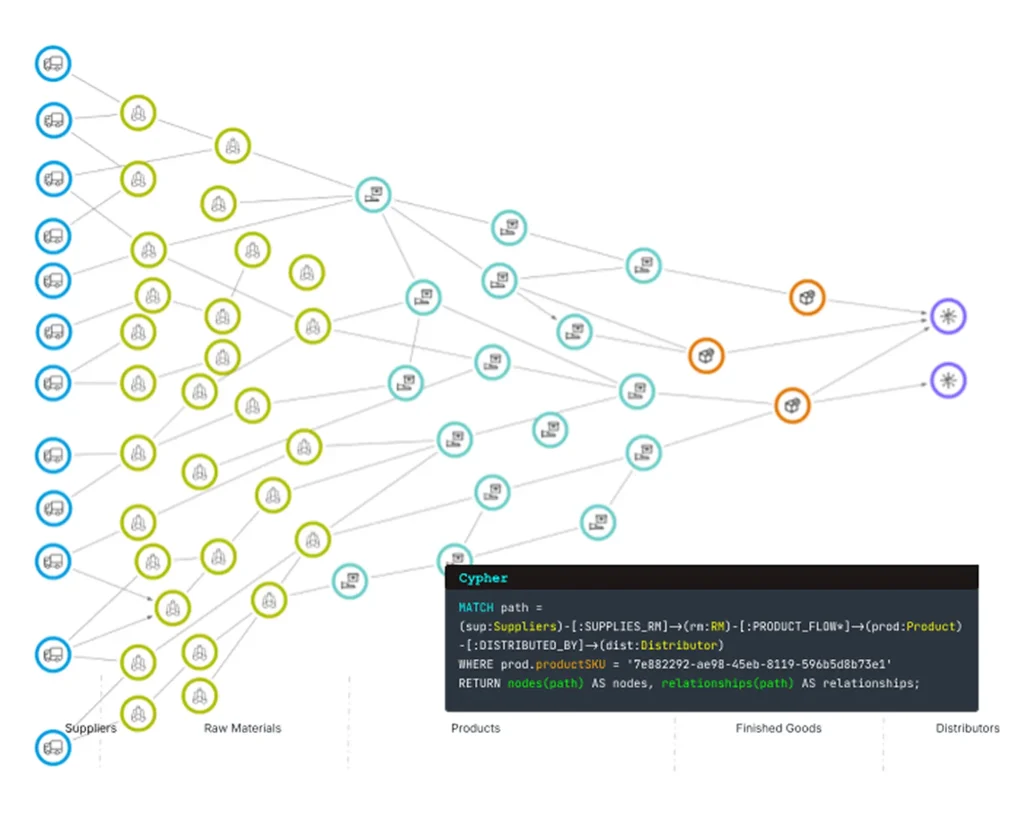
What this looks like in practice
A semiconductor fabrication facility in Taiwan goes offline. The supervisor agent receives the question: “Supplier A is disrupted and takes four weeks to recover. What actions should we take?”
The Genie Lakehouse agent, Genie Space, first queries the Delta tables. It returns the inventory position for every component sourced from that supplier, identifies which finished products are at risk, and calculates how many days of production remain before stockouts occur across each product line. The answer arrives in seconds.
The Neo4j Knowledge Graph Agent then traverses the supplier graph using Cypher. It identifies every product line with a dependency on the disrupted supplier, runs PageRank to surface which tier 2 suppliers now carry elevated risk, and executes a shortest path query to return qualified alternative suppliers ranked by lead time and current capacity. It also runs Louvain across the affected cluster to identify other suppliers in the same dependency community, the ones most likely to face cascading pressure from the same disruption.
The supervisor agent combines both responses into a single recommendation: here is your current exposure, here are your alternatives, and here is where the next failure is most likely to come from.
In the solution accelerator scenario, the full analysis can be completed in under 30 seconds, resolving what would typically require an hours-long manual investigation across disconnected systems.
Graph-Powered Supply Chain Analytics
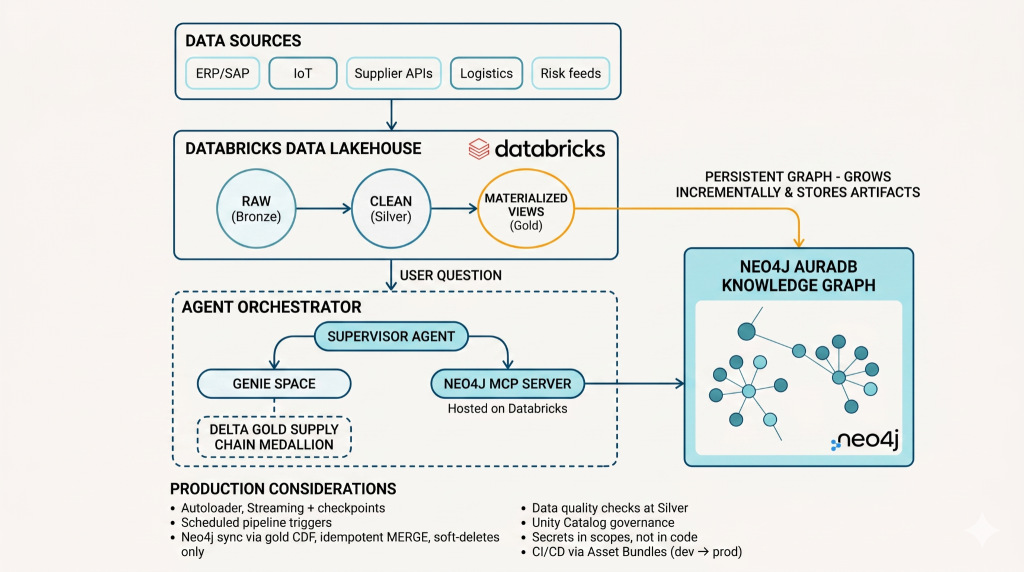
The scenario above runs on the Supply Chain Analytics solution accelerator, built on a dual architecture that combines Databricks’ operational data layer with Neo4j’s graph intelligence. Databricks remains the system of record for governed, high-volume operational data: inventory, suppliers, BOMs, logistics, demand, and risk signals. Neo4j turns the relationships across that data into a graph intelligence layer that can answer dependency, exposure, and cascade-risk questions in real time. Together, they give supply chain teams both the numbers and the network context needed to act.
Delta’s Change Data Feed keeps Neo4j graph in sync with gold tables. As upstream changes flow through the medallion pipeline to the gold layer, an idempotent MERGE writes deltas into Neo4j, entities created, relationships updated, and removed ones soft-deleted. The graph grows incrementally rather than being rebuilt, so centrality scores and community assignments persist across runs and stay current with the operational state.
A supervisor agent built on Databricks Mosaic AI classifies each question and routes it to the right agent. Quantitative questions go to the Genie Lakehouse Agent. Network and risk questions go to the Neo4j Knowledge Graph Agent. The supervisor combines their outputs into a single, coherent response, grounded in both operational data and graph structure.
Outcomes
The scenario above illustrates the pattern. The dual architecture delivers capabilities that matter to supply chain leaders, each grounded in a specific feature of the stack.
- Visibility beyond tier 1
Supply chain teams can trace dependencies across suppliers, components, finished goods, and customers before a disruption exposes them. - Faster disruption response
Teams can move from manual investigation to same-day decisions, with agents surfacing exposure, alternatives, and likely points of cascade risk. - Risk based on network influence
Graph algorithms help identify suppliers whose failure would have an outsized impact, even when they are not the largest by spend or order volume. - Governed operational context
Databricks keeps operational data governed and current, while Neo4j keeps the relationship layer synchronized for graph analysis.
Get started
Supply chain resilience is only one example of a broader pattern: enterprise AI becomes more useful when governed operational data is connected to the relationships that give it meaning.
The Supply Chain Analytics solution accelerator on GitHub includes synthetic data generation, Delta Lake integration, a running supervisor agent, and sample Cypher queries you can execute immediately against the loaded graph. Clone the repo, run the setup notebook, and the full dual-architecture environment is operational in under an hour.
References:
Share Article



Explore
Related Articles



A workbench for teams to query, explore, and visualize graph data
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

