A GenAI-powered song finder in four lines of code

Director of Engineering, Neo4j
12 min read

We will build a catalog of songs and lyrics with Neo4j, and use its built-in Gen AI capabilities to find songs from a synopsis of what they are about.
Have you ever wanted to find a song, but you don’t remember what it was called, nor who wrote it? Or do you only vaguely remember what it was about? Let’s build a tool that solves just that use case — with four lines of code.

The Internet is a hype that may blow by. I don’t think in the long run people will want to spend as much time, as it actually takes, surfing the net
This was a quote by the Swedish Minister of Communication, Ines Uusmann, in 1996. I guess she was right that the internet was a hype, but it was a hype for something that had already been around for 20 years, and one that would certainly not blow by. It is hard to imagine modern life without the internet. What actually built the hype in the early 90s was the introduction of the World Wide Web.
Similarly, many call AI a hype, which, of course, it also is, but one that is very similar to the Internet hype. AI has been around for more than half a century, and I believe it will still be here in the future, as integral to our lives as the internet is today. What WWW was to the Internet is what Large Language Models (LLMs) and Generative AI are to Artificial Intelligence.
If this prediction is true, it is important- especially for a software developer- to learn and embrace this new technology, not only from chatting with ChatGPT but by learning how to use this technology yourself. And you don’t have to be a mathematician to do so. There are so many great tools out there that make the use of AI simple. One of those tools is Neo4j.
Neo4j and AI
The power of knowledge graphs in conjunction with LLMs and Gen AI is well known and has been explored in dozens of articles. With the addition of vector indexes, vector search, and built-in embedding procedures, you have everything you need packaged inside the Neo4j graph database.
I won’t go too deep into what vector search is about, just to give you a brief understanding. A vector is something that has a length and a direction, sort of like an arrow. In two dimensions, you can describe the vector with two numbers, x and y, below.
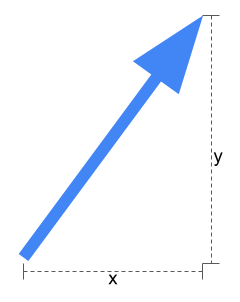
Vector embeddings are when you let an LLM create a single vector that represents the content of a natural language text (or an image or a piece of music), for example, this blog article. But it is not a two-dimensional vector like above, but a vector with over a thousand dimensions (1536 dimensions in the case with OpenAI). Now you have a numerical representation of a text, and with that, you can search for similar texts, for example, another blog about Gen AI and Neo4j (there are a few). It is not the similarity of the words used in the text but the actual meaning of the text (which is what an LLM is designed to understand).
Neo4j lets you store a vector embedding as a property on a node and then search for nodes that are similar to a certain embedding. You can also index these vectors to make searches fast. This is what we will use to create our lyrics finder.
Why a lyrics finder?
But why do we want to create a tool like this? ChatGPT is excellent at this right out of the box. If I ask it:
Which Metallica song is about a guy who is so badly wounded in war so he no longer has any senses
It will respond with:
The Metallica song you’re referring to is “One.” “One” is a track from their 1988 album “…And Justice for All.” The song is inspired by the novel “Johnny Got His Gun” by Dalton Trumbo, which tells the story of a soldier who loses all his senses, including sight, hearing, and speech, after being wounded in World War I. In the song, Metallica conveys the horror and suffering of war and the loss of individual identity that can occur in such a tragic situation.
Well, there are several reasons why we might want to create this as a tool of our own:
- ChatGPT only knows what existed when the language model was trained. So it wouldn’t have worked if it was a song from the latest Metallica album, “72 Seasons”.
- ChatGPT is cool, but it is not entirely reliable. Sometimes, it tells straight-out lies.
- If you have this as part of a music service, like Spotify, you only want to search the songs in your library, not everything.
- And if you want to incorporate a feature like this in a tool like Spotify, you probably don’t want to integrate with a chat function but a more well-defined API.
Our tool
Before getting started, we need to create an OpenAI account. Neo4j has support for OpenAI, VertexAI, and AWS Bedrock to do the embeddings, but we’ll use OpenAI. Note that these are paid accounts, and there will be a cost to this. But the cost of all the tests I made for this article was less than 2 cents. In our OpenAI account, we need to create an API key, and this is the key that is used as $apiKey in the queries below.
The Gen AI support has come incrementally in Neo4j 5.x versions. The latest part that we will use here, the embedding procedures, was released in Neo4j 5.15, so that is the version that we will use.
If you have your own instance of Neo4j, you have to install the embedding procedures by copying the neo4j-genai-plugin-5.XX.0.jar from the products to the plugins folder of Neo4j (and restart). If you are on Aura, you will have access to these procedures by default.
One way to test the content of this article is to setup an instance of Aura Free. Just setup a free account here https://neo4j.com/product/auradb/ and then create an instance to play with. Remember that you also need to sign up for an OpenAI account.
I will not write any application around the functionality here for this article. Instead, I will just write Cypher queries in the Neo4j Browser. But if you were to develop a tool like this, you would, of course, incorporate those queries inside your application instead.
It would be cool to do this with all the songs ever written, but I don’t have access to any such data, so for this example, I found a library of the lyrics of all Metallica songs written up to St Anger. I found it in HTML format, but I parsed the lyrics and created a graph with the artist (in this case, only Metallica), the albums, and the songs, with the lyrics of the songs as a String property on each Song node.
If you want to duplicate this dataset for your own tests, you can run the code below to import it. You can, of course, use your own favorite artists and songs, as long as it follows the same schema as implied by the import statement below.
LOAD CSV WITH HEADERS FROM 'https://drive.google.com/uc?export=download&id=1uD3h7xYxr9EoZ0Ggoh99JtQXa3AxtxyU' AS line
CREATE (song:Song {name: line.Song, lyrics: line.Lyrics})
MERGE (album:Album {name: line.Album})
MERGE (artist:Artist {name: line.Artist})
MERGE (song)-[:IS_ON]->(album)
MERGE (album)-[:PERFORMED_BY]->(artist)
The first thing we need to do now that we have the database is to create a vector index on the property we will use for the vector. We call this property embedding, and it is on the Song node. 1536 is the dimension of the vector (remember, 1536 is what OpenAI uses), and the last property ‘cosine’ is the similarity algorithm to use. ‘cosine’ is what is normally recommended.
CREATE VECTOR INDEX song_embeddings IF NOT EXISTS
FOR (s:Song) ON (s.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}
Now, we need to add the vector embedding of the lyrics for every song. We do a simple MATCH to find the songs, and then pass the lyrics property string to the embeddings function.
MATCH (song:Song)
WITH song, genai.vector.encode(song.lyrics, "OpenAI", {token: $apiKey}) AS vector
CALL db.create.setNodeVectorProperty(song, "embedding", vector)
Note that the procedure db.create.setNodeVectorProperty() does the same as SET song.embedding = embedding, however, the vector will be stored in a more optimal format when done like this.
This query will take some time to run since it will make one API call to OpenAI for every song in the database. There is an alternative with a batch procedure instead of the function above, which would (in our case) result in only one API call.
MATCH (song:Song)
WITH collect(song.lyrics) AS lyrics, collect(song) AS songs
CALL genai.vector.encodeBatch(lyrics, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(songs[index], "embedding", vector)
The caveat here is that there is a limit to how many items you can include in one batch (2048 in the case of OpenAI), so if we had more than just Metallica in the database, we would need to divide and conquer, for example, batch by artist or batch by album.
Now we are all set and ready to do our lyrics searching. We will set the phrase to search for as a parameter called phrase, and we’ll still have the apiKey as a parameter (which I won’t show below).
:params
{
phrase: "A song about a guy who is so badly wounded in war so he no longer has any senses",
apiKey: "*****"
}
To do the search, we just call the same function to generate the vector embedding for our search phrase, and then we use a dedicated procedure to do a vector search in the database for the song with the most similar embedding.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 1, embedding) YIELD node AS song, score
RETURN song.name
This gives us the reply DISPOSABLE HEROES. Well, that wasn’t really what we expected. We were thinking of ONE. Disposable Heroes is also a war song about suffering, so it is a correct answer, just not the one we wanted. This is no exact science. Therefore, it is usually best to ask for a number of top matches. The correct one is generally in the top 3–5 results. The second parameter to queryNodes is the results we want, so we can just increase that to 3.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
RETURN song.name
Now, we get back.
DISPOSABLE HEROES
ONE
ONE
There we go. We get the correct one as the second match. And the third match…? Why do we get it twice? Well, because it is on more than one album, it is duplicated in the database as we have modeled it.
This is where it is so great to have a knowledge graph backing our solution. We find the song based on the lyrics, but then we can traverse the graph to find everything else.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
MATCH (song)-[:IS_ON]->(album:Album)-[:PERFORMED_BY]->(artist:Artist)
RETURN song.name AS Song, album.name AS Album, artist.name AS Artist
And now we get
Song Album Artist
DISPOSABLE HEROES MASTER OF PUPPETS Metallica
ONE S&M Metallica
ONE And Justice For All.. Metallica
Now, we just need to make one more test to ensure it works. This time, we search for:
A song about a boy who is having nightmares
The results are
Song Album Artist
Enter Sandman Black Album Metallica
Enter Sandman S&M Metallica
The thing that should not be MASTER OF PUPPETS Metallica
Enter Sandman was the one I intended, so I need to call that a success.
There you go. We have done an intelligent song synopsis finder in four lines of code!
Documentation
Here is the documentation of vector search indexes:
Vector search indexes – Cypher Manual
Here you can find the documentation for the embedding functions/procedures:
GenAI integrations – Cypher Manual
A Gen AI-Powered Song Finder in Four Lines of Code was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



