Configure Entity Extraction
How to configure entity extraction pipelines to automatically build your context graph from conversations and documents.
Prerequisites
-
neo4j-agent-memoryinstalled -
For GLiNER extraction:
pip install neo4j-agent-memory[gliner] -
For LLM extraction: OpenAI API key or compatible LLM
Quick Start
Use the built-in POLE+O schema for general-purpose extraction:
from neo4j_agent_memory import MemoryClient, MemorySettings
from neo4j_agent_memory.extraction import GLiNEREntityExtractor
settings = MemorySettings(
neo4j={"uri": "bolt://localhost:7687", "password": "password"}
)
client = MemoryClient(settings)
# Create extractor with POLE+O schema
extractor = GLiNEREntityExtractor.for_poleo()
text = """
Customer Jane Smith called about her order #12345 from Nike.
She purchased Air Max 90 shoes last week from our Manhattan store.
She mentioned she prefers next-day delivery for future orders.
"""
result = await extractor.extract(text)
for entity in result.entities:
print(f" {entity.name} ({entity.type}) - confidence: {entity.confidence:.2f}")Choosing an Extractor
|
Which extractor should I use?
|
| Extractor | Speed | Quality | Cost | Best For |
|---|---|---|---|---|
spaCy |
Very Fast |
Basic |
Free |
High-volume, standard entity types |
GLiNER |
Fast |
Good |
Free |
Domain-specific, local deployment |
GLiNER + GLiREL |
Fast |
Good |
Free |
Entities + relationships together |
LLM (gpt-4o-mini) |
Slow |
Excellent |
$$ |
Complex text, high-accuracy requirements |
Hybrid Pipeline |
Medium |
Excellent |
$ |
Production systems |
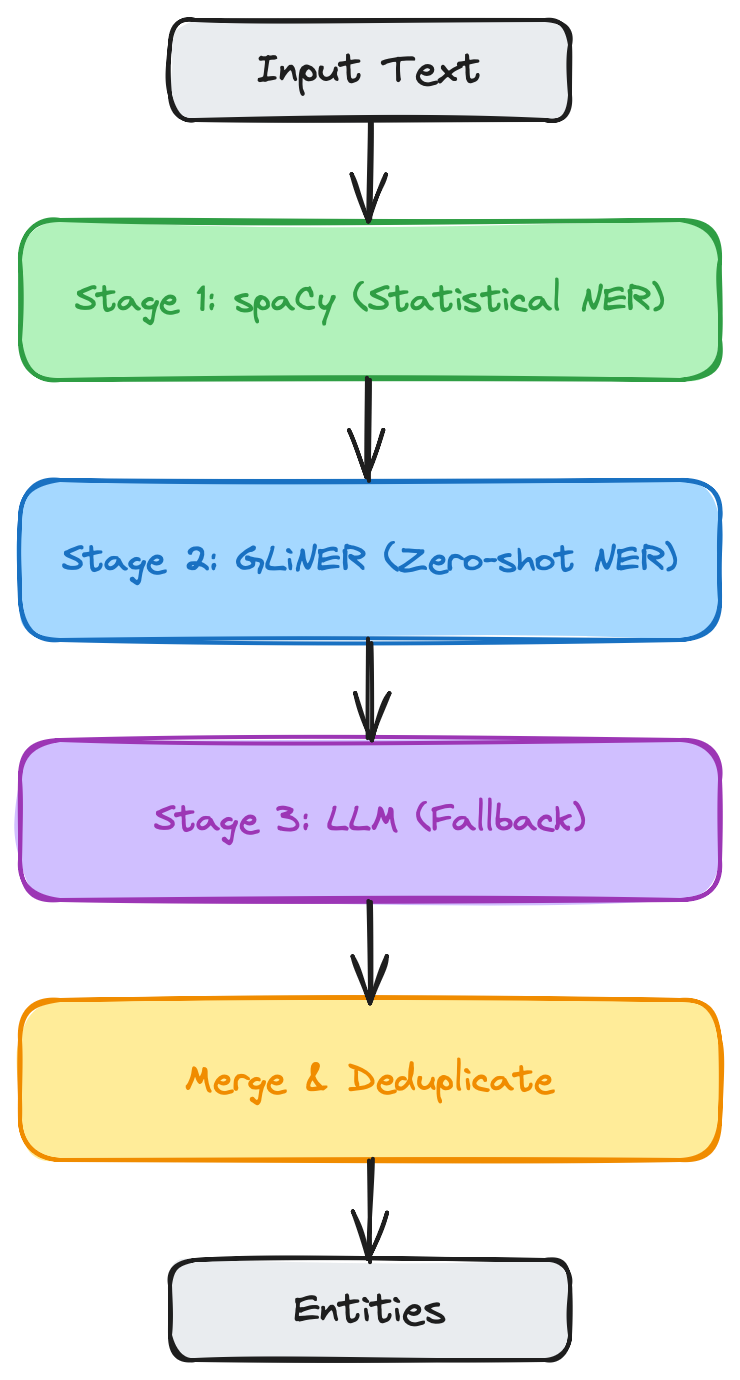
Multi-Stage Extraction Pipelines
Combine extractors for comprehensive extraction:
from neo4j_agent_memory.extraction import (
ExtractionPipeline,
GLiNEREntityExtractor,
LLMEntityExtractor,
)
# Stage 1: Fast local extraction
gliner = GLiNEREntityExtractor.for_schema("financial")
# Stage 2: LLM for refinement and relationship extraction
llm = LLMEntityExtractor(
model="gpt-4o-mini",
extract_relations=True,
schema="financial",
)
pipeline = ExtractionPipeline(
stages=[gliner, llm],
merge_strategy="confidence", # Keep highest confidence result per entity
)
result = await pipeline.extract(text)|
Use LLM as a fallback, not a first pass. Run GLiNER first — it handles 80-90% of entities with no API cost. Only route to LLM when GLiNER confidence is below your threshold, or when you need relationship extraction that GLiREL can’t handle. |
Conditional Pipeline
Apply different schemas based on conversation content:
from neo4j_agent_memory.extraction import ConditionalPipeline
pipeline = ConditionalPipeline(
conditions=[
{
"keywords": ["portfolio", "investment", "stock", "bond", "dividend"],
"extractor": GLiNEREntityExtractor.for_schema("financial"),
},
{
"keywords": ["order", "shipping", "product", "return", "delivery"],
"extractor": GLiNEREntityExtractor.for_schema("ecommerce"),
},
],
default=GLiNEREntityExtractor.for_poleo(),
)
result = await pipeline.extract(text)Store Extracted Entities
Basic Storage
result = await extractor.extract(text)
for entity in result.entities:
stored, _ = await client.long_term.add_entity(
name=entity.name,
entity_type=entity.type,
attributes={
"confidence": entity.confidence,
"extracted_at": datetime.now().isoformat(),
},
)With Deduplication
Prevent duplicate nodes in your context graph:
from neo4j_agent_memory.memory import DeduplicationConfig
dedup_config = DeduplicationConfig(
auto_merge_threshold=0.95, # Auto-merge highly similar entities
flag_threshold=0.85, # Flag for review between 0.85-0.95
use_fuzzy_matching=True,
match_same_type_only=True,
)
for extracted in result.entities:
entity, dedup_result = await client.long_term.add_entity(
name=extracted.name,
entity_type=extracted.type,
deduplication=dedup_config,
)
if dedup_result.action == "merged":
print(f"Merged '{extracted.name}' with '{dedup_result.matched_entity_name}'")
elif dedup_result.action == "flagged":
print(f"Flagged '{extracted.name}' for review")Validate Before Storing
for entity in result.entities:
if entity.confidence < 0.6:
continue
if len(entity.name) < 2:
continue
stored, _ = await client.long_term.add_entity(
name=entity.name,
entity_type=entity.type,
)With Provenance Tracking
entity, _ = await client.long_term.add_entity(
name=extracted.name,
entity_type=extracted.type,
)
await client.long_term.link_entity_to_message(
entity=entity,
message_id=message.id,
confidence=extracted.confidence,
start_pos=extracted.start,
end_pos=extracted.end,
)
await client.long_term.link_entity_to_extractor(
entity=entity,
extractor_name="GLiNEREntityExtractor",
extractor_version="1.0",
confidence=extracted.confidence,
)