ImportPreview
AuraDB Free AuraDB Professional AuraDB Business Critical
|
This feature is in preview and is offered AS-IS and should only be used for internal development purposes and not in production. |
Once you have added your source documents, generated a model, refined it, and fixed any errors, you can run the import. However, if you want to see what your graph will look like, you can generate a preview from the tool bar on the bottom of the model panel. The preview is generated from a random sample of your data and will therefore look slightly different from your final graph, but it can give insights and provide an overview of your data.
Once the import job is complete, you can use the Document Intelligence Agent to talk to your data directly in natural language.
|
Document Intelligence uses generative AI assistance and this usage can be disabled on the Organization level. See Visual tour → Organization settings. |
The import process
Regardless of whether you use the Document Intelligence Agent to trigger the import job, or the button, the process is done behind the scenes.
The process consists of the following high level steps:
-
Document parsing - text is extracted from your document(s)
-
Document chunking - each document is split into smaller pieces of text of a fixed size
-
Chunk embedding - each chunk’s text is embedded using the gemini-embedding-001 model
-
-
Entity and relation extraction - for each chunk of text, entity and relation extraction is performed according to the provided graph model. This means that only node labels and relationship types listed in the model are extracted.
-
Entity resolution - also known as entity deduplication. Using the key property defined in the graph model to deduplicate entities based on the lower-case value of said property.
-
Import - imports the documents as a graph.
Lexical graph
In addition to the entities extracted from the documents that form the knowledge graph, other nodes and relationships are created that are part of a lexical graph. The lexical graph is created internally during the import process and this results in a single graph containing both a lexical layer and a knowledge layer.
See the illustration of the knowledge graph model on the left and the resulting imported knowledge graph with a lexical layer on the right.
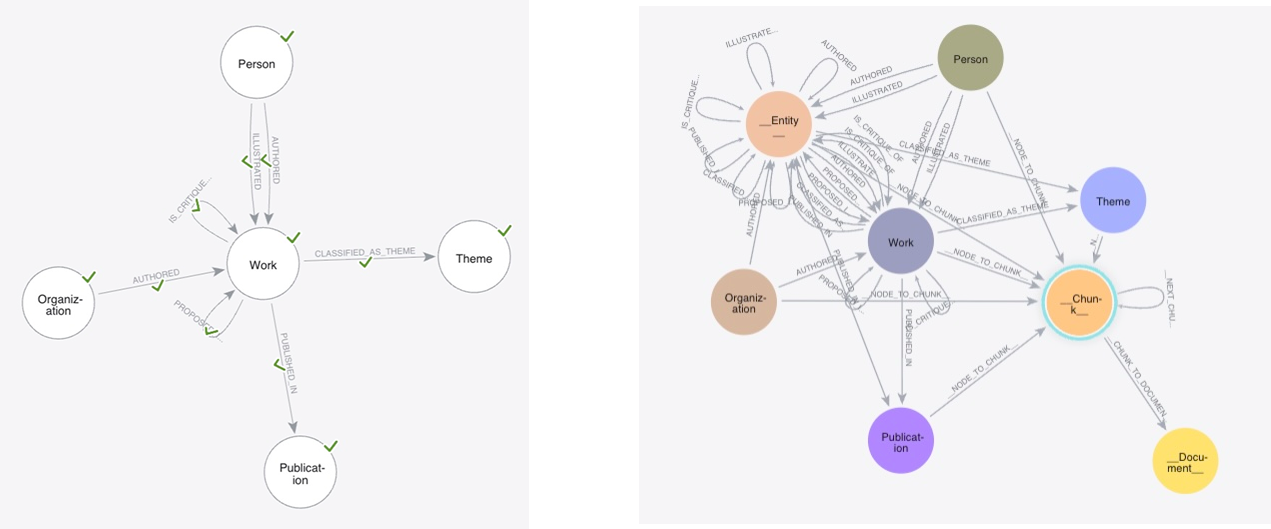
The lexical graph consists of the following nodes and relationships:
-
_ _Document_ _- a node that represents a single document in the data source. It has a path property to identify it. -
_ _Chunk_ _- a node that is a part of a document. It is linked to its source document via a_ _CHUNK_TO_DOCUMENT_ _relationship. -
_ _NEXT_CHUNK_ _- a relationship that links the different chunks together. -
_ _NODE_TO_CHUNK_ _- a relationship between all extracted entities and the chunk they are extracted from.
All entities extracted gets an _Entity_ label in addition to other labels.