Graph pattern search
Bloom provides an easy and flexible way to explore your graph through graph patterns. It uses a vocabulary built from your graph and Perspective elements (categories, labels, relationship types, property keys and property values). Uncategorized labels and relationships or properties hidden in the Perspective are not considered in the vocabulary. To build a graph pattern search in Bloom, you use this vocabulary and either build the pattern step by step or type in a near-natural language phrase.
Step-by-step pattern building with proactive suggestions
One approach to building graph patterns is to use the proactive suggestions feature of Bloom. This is useful when you need assistance with picking elements of your graph schema (e.g. relationship types from a label or categories that connect together).
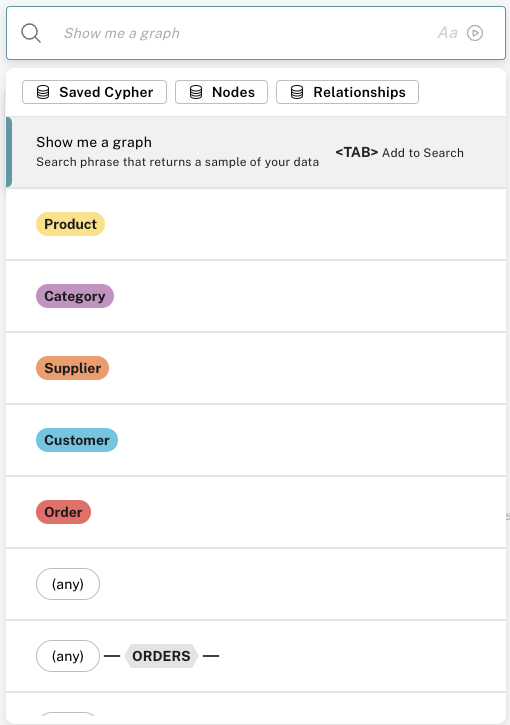
When you go to the search bar, Bloom presents proactive options to begin your search.
You can select from any node labels available in the Perspective or use a blank (any) node.
Further, if you know which relationship you are interested in, but not which node labels it connects, you can select based on the relationship type and use the wildcard option for the node label (the (any) node).
Additionally, you can filter the suggestions by Search phrases, nodes, or relationships.
If you select a node label, Product for example, Bloom lets you choose if you want to further filter on the start node by its relationships or if you want to refine by properties and/or property values.
Bloom gives you a hint about the datatype of the property value directly in the search bar.
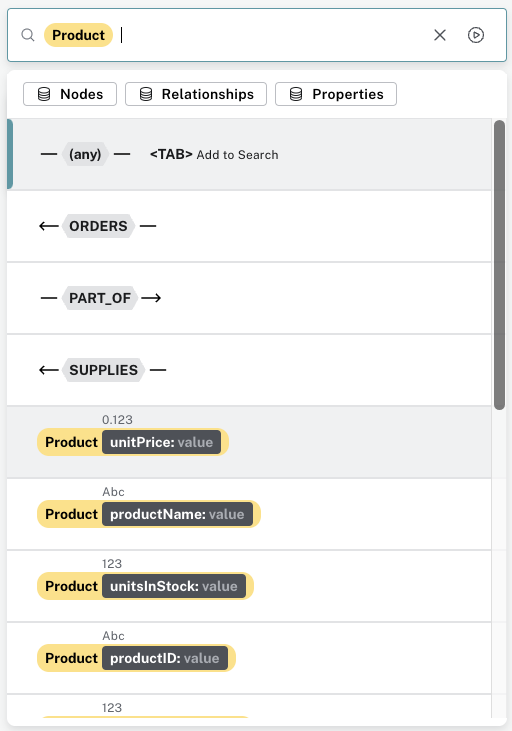
If you select Properties, you can see all properties for the Product label and if you pick discontinued for example, you can then specify the condition, for example true.
This results in a pattern that starts with a discontinued product and filters all other nodes, both the ones with other labels as well as the Product nodes where the discontinued property does not equal true.
From here, you can either press the play icon to display all discontinued products, or you can continue defining your graph pattern.
When you are happy with the start node, select Relationship to see a list of available relationship types for your specified start node, both incoming and outgoing.
Similarly, you can further filter on properties for the relationship, if available.
If you are not interested in the type of relationship, you can use the wildcard (any) relationship.
The last step is to specify the end node, which naturally follows the same steps as the start node.
The wildcard option, (any), is available here as well.
Press the play icon when you are ready to execute the search.
A note on property-value suggestions
Category, label and relationship type matches are searched in Bloom’s in-memory metadata of available graph and Perspective elements.
For property matches, Bloom queries the database instead to find suggestions.
To do so, Bloom relies on property indexes to be set up in the database for any properties that should be searchable in Bloom.
For bigger graphs, all properties of a node with a certain label are considered as indexed if there are less than 1000 nodes with the specific label. However, if a property has the same value on more than 10% of the nodes, it is not searchable, whether indexed or not, for performance reasons. For small graphs with low cardinality in data values (e.g. the Movies graph, found in the example data sets), Bloom is able to search for property values without requiring an index.
Depending on the search input, the number of indexes, and the speed of typing in the search box, it is possible that Bloom runs a large number of index lookup queries to find relevant matches. Optimizations are built-in to delay firing queries while waiting for user to complete the input and to cancel un-needed queries if the input is changed.
Bloom also attempts to hide pattern permutations from the suggestions list, if they are not found in the database. This may not be applicable in all situations. It is possible for database performance issues or network latency between the user’s machine and the Neo4j server to cause delays in showing search suggestions.
Case sensitivity of input
Neo4j database is case sensitive.
By default, property values are matched by Bloom in a case sensitive fashion, if they begin with any of the matching tokens input by the user.
If you would like search suggestions to be case insensitive, you can enable Case insensitive search and suggestions under Bloom settings.
By contrast, metadata elements like labels, categories, relationship types or property keys, are matched in a case insensitive fashion. Also, metadata elements are matched if they simply contain one of the search tokens.
|
Case insensitive matching of property values requires full-text indexes on all properties that will be searched.
Without full-text indexes, Bloom will use case sensitive searching even with |