Importing JSON Data from a REST API into Neo4j
|
Important - page not maintained
This page is no longer being maintained and its content may be out of date. For the latest guidance, please visit the Getting Started Manual . |
This article demonstrates some techniques for loading data from JSON-based REST APIs into Neo4j.
Before importing data from a JSON-based REST API you should have installed the APOC library.
Intermediate
Importing JSON Data into Neo4j
There are a plethora of JSON-based Web APIs that we can import into Neo4j, and we can use one of the Load JSON procedures to retrieve data from these APIs and turn it into map values ready for Cypher to consume.
The APOC user guide provides a worked example showing how to import data from StackOverflow into Neo4j.
The Strava API
Strava is an application used by runners and cyclists to record their activities and share them with their friends. This data is available to users via a JSON-based REST API.
Before we start calling the API, we need to create an application. We will then be provided with an access token that we will need to use in all our requests to the API.
We can create a parameter in the Neo4j Browser or Cypher shell by executing the following command:
:params {stravaToken: "Bearer <insert-strava-token>"}Working with a paginated endpoint
We are interested in importing the activities for the athlete who is logged in. That endpoint takes the following parameters:
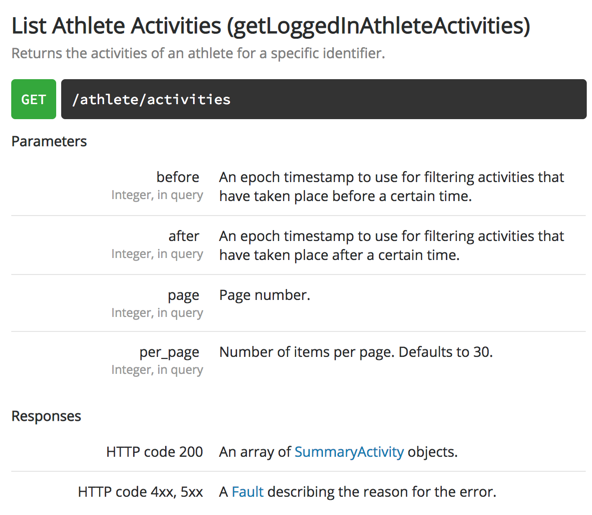
We’re interested in per_page (where we can define the number of activities returned per call to the endpoint) and after (where we can tell the API to only return results after a provided epoch timestamp).
Let’s imagine that we have more activities that we can return in one request to the API. We’ll need to paginate to retrieve all our activities and import them into Neo4j.
Before we paginate the API, let’s first learn how to import one page worth of activities into Neo4j. The following query will return activities starting from the earliest timestamp:
WITH 0 AS after
WITH 'https://www.strava.com/api/v3/athlete/activities?after=' + after AS uri
CALL apoc.load.jsonParams(uri, {Authorization: $stravaToken}, null)
YIELD value
CREATE (run:Run {id: value.id})
SET run.distance = toFloat(value.distance),
run.startDate = datetime(value.start_date_local),
run.elapsedTime = duration({seconds: value.elapsed_time})We create a node with the label Run for each activity and set a few properties, as well.
The most interesting one for this example is startDate which we will pass to the after parameter later on.
This query will load the first 30 activities, but what if we want to get the next 30?
We can change the first line of the query to find the most recent timestamp of any of our Run nodes and then pass that to the API.
If there aren’t any Run nodes, then we can use a value of 0 like in the query below.
OPTIONAL MATCH (run:Run)
WITH run ORDER BY run.startDate DESC LIMIT 1
WITH coalesce(run.startDate.epochSeconds, 0) AS after
WITH 'https://www.strava.com/api/v3/athlete/activities?after=' + after AS uri
CALL apoc.load.jsonParams(uri, {Authorization: $stravaToken}, null)
YIELD value
CREATE (run:Run {id: value.id})
SET run.distance = toFloat(value.distance),
run.startDate = datetime(value.start_date_local),
run.elapsedTime = duration({seconds: value.elapsed_time})We could continue to run this query manually, but it’s about time that we automated it.
Automated API pagination
One way to do this is by using a scripting language and creating a loop inside which we make calls to that endpoint until we run out of activities to retrieve.
If we’re a bit creative, we can achieve the same outcome with the apoc.periodic.commit procedure.
From the APOC documentation, this is the description of the periodic iterate procedure:
In our case, the exit condition will be when we receive less than 30 activities from the API.
Let’s first update our query to return a value of 0 if less than 30 activities are returned and the actual count if it’s 30.
OPTIONAL MATCH (run:Run)
WITH run ORDER BY run.startDate DESC LIMIT 1
WITH coalesce(run.startDate.epochSeconds, 0) AS after
WITH 'https://www.strava.com/api/v3/athlete/activities?after=' + after AS uri
CALL apoc.load.jsonParams(uri, {Authorization: $stravaToken}, null)
YIELD value
CREATE (run:Run {id: value.id})
SET run.distance = toFloat(value.distance),
run.startDate = datetime(value.start_date_local),
run.elapsedTime = duration({seconds: value.elapsed_time})
RETURN CASE WHEN count(*) < 30 THEN 0 ELSE count(*) END AS countAll that’s left to do now is wrap the whole thing in periodic commit.
We’ll call apoc.periodic.commit method with two arguments: the first is the Cypher statement to run until the RETURN clause returns 0, and the second are parameters that are passed to the Cypher statement.
call apoc.periodic.commit("
OPTIONAL MATCH (run:Run)
WITH run ORDER BY run.startDate DESC LIMIT 1
WITH coalesce(run.startDate.epochSeconds, 0) AS after
WITH 'https://www.strava.com/api/v3/athlete/activities?after=' + after AS uri
CALL apoc.load.jsonParams(uri, {Authorization: $stravaToken}, null)
YIELD value
CREATE (run:Run {id: value.id})
SET run.distance = toFloat(value.distance),
run.startDate = datetime(value.start_date_local),
run.elapsedTime = duration({seconds: value.elapsed_time})
RETURN CASE WHEN count(*) < 30 THEN 0 ELSE count(*) END AS count
", {stravaToken: $stravaToken})This query will now send multiple commits to the API until we have loaded all our activities.