All Pairs Shortest Path
The All Pairs Shortest Path (APSP) calculates the shortest (weighted) path between all pairs of nodes. This algorithm has optimizations that make it quicker than calling the Single Source Shortest Path algorithm for every pair of nodes in the graph.
Glossary
- Directed
-
Directed trait. The algorithm is well-defined on a directed graph.
- Directed
-
Directed trait. The algorithm ignores the direction of the graph.
- Directed
-
Directed trait. The algorithm does not run on a directed graph.
- Undirected
-
Undirected trait. The algorithm is well-defined on an undirected graph.
- Undirected
-
Undirected trait. The algorithm ignores the undirectedness of the graph.
- Heterogeneous nodes
-
Heterogeneous nodes fully supported. The algorithm has the ability to distinguish between nodes of different types.
- Heterogeneous nodes
-
Heterogeneous nodes allowed. The algorithm treats all selected nodes similarly regardless of their label.
- Heterogeneous relationships
-
Heterogeneous relationships fully supported. The algorithm has the ability to distinguish between relationships of different types.
- Heterogeneous relationships
-
Heterogeneous relationships allowed. The algorithm treats all selected relationships similarly regardless of their type.
- Weighted relationships
-
Weighted trait. The algorithm supports a relationship property to be used as weight, specified via the relationshipWeightProperty configuration parameter.
- Weighted relationships
-
Weighted trait. The algorithm treats each relationship as equally important, discarding the value of any relationship weight.
- Node properties
-
Node properties trait. The algorithm makes use of node properties.
History and explanation
Some pairs of nodes might not be reachable between each other, so no shortest path exists between these pairs.
In this scenario, the algorithm will return Infinity value as a result between these pairs of nodes.
GDS includes functions such as gds.util.isFinite to help filter infinity values from results.
Starting with Neo4j 5, the Infinity literal is now included in Cypher too.
Use-cases - when to use the All Pairs Shortest Path algorithm
-
The All Pairs Shortest Path algorithm is used in urban service system problems, such as the location of urban facilities or the distribution or delivery of goods. One example of this is determining the traffic load expected on different segments of a transportation grid. For more information, see Urban Operations Research.
-
All pairs shortest path is used as part of the REWIRE data center design algorithm that finds a network with maximum bandwidth and minimal latency. There are more details about this approach in "REWIRE: An Optimization-based Framework for Data Center Network Design"
Syntax
CALL gds.allShortestPaths.stream(
graphName: string,
configuration: map
)
YIELD sourceNodeId, targetNodeId, distance| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
List of String |
|
yes |
Filter the named graph using the given node labels. Nodes with any of the given labels will be included. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. Relationships with any of the given types will be included. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
String |
|
yes |
Name of the relationship property to use as weights. If unspecified, the algorithm runs unweighted. |
|
1. In a GDS Session, the default is the number of available processors. |
||||
| Name | Type | Description |
|---|---|---|
sourceNodeId |
Integer |
The source node. |
targetNodeId |
Integer |
The target node. |
distance |
Float |
The distance of the shortest path from source to target. |
All Pairs Shortest Path algorithm sample
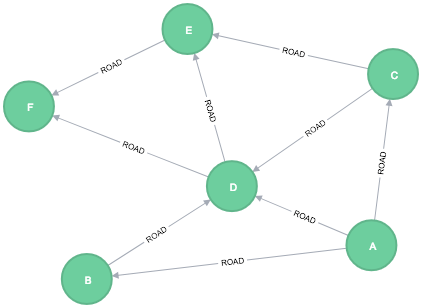
CREATE (a:Loc {name: 'A'}),
(b:Loc {name: 'B'}),
(c:Loc {name: 'C'}),
(d:Loc {name: 'D'}),
(e:Loc {name: 'E'}),
(f:Loc {name: 'F'}),
(a)-[:ROAD {cost: 50}]->(b),
(a)-[:ROAD {cost: 50}]->(c),
(a)-[:ROAD {cost: 100}]->(d),
(b)-[:ROAD {cost: 40}]->(d),
(c)-[:ROAD {cost: 40}]->(d),
(c)-[:ROAD {cost: 80}]->(e),
(d)-[:ROAD {cost: 30}]->(e),
(d)-[:ROAD {cost: 80}]->(f),
(e)-[:ROAD {cost: 40}]->(f);MATCH (src:Loc)-[r:ROAD]->(trg:Loc)
RETURN gds.graph.project(
'cypherGraph',
src,
trg,
{
relationshipType: type(r),
relationshipProperties: r { .cost }
},
{ undirectedRelationshipTypes: ['ROAD'] }
)Memory Estimation
First off, we will estimate the cost of running the algorithm using the estimate procedure.
This can be done with any execution mode.
We will use the stream mode in this example.
Estimating the algorithm is useful to understand the memory impact that running the algorithm on your graph will have.
When you later actually run the algorithm in one of the execution modes the system will perform an estimation.
If the estimation shows that there is a very high probability of the execution going over its memory limitations, the execution is prohibited.
To read more about this, see Automatic estimation and execution blocking.
For more details on estimate in general, see Memory Estimation.
CALL gds.allShortestPaths.stream.estimate('cypherGraph', {
relationshipWeightProperty: 'cost'
})
YIELD nodeCount, relationshipCount, bytesMin, bytesMax, requiredMemory
RETURN nodeCount, relationshipCount, bytesMin, bytesMax, requiredMemory| nodeCount | relationshipCount | bytesMin | bytesMax | requiredMemory |
|---|---|---|---|---|
6 |
18 |
1264 |
1264 |
"1264 Bytes" |
Stream
In the stream execution mode, the algorithm returns the shortest path distance for each source-target pair.
This allows us to inspect the results directly or post-process them in Cypher without any side effects.
CALL gds.allShortestPaths.stream('cypherGraph', {
relationshipWeightProperty: 'cost'
})
YIELD sourceNodeId, targetNodeId, distance
WITH sourceNodeId, targetNodeId, distance
WHERE gds.util.isFinite(distance) = true
WITH gds.util.asNode(sourceNodeId) AS source, gds.util.asNode(targetNodeId) AS target, distance WHERE source <> target
RETURN source.name AS source, target.name AS target, distance
ORDER BY distance DESC, source ASC, target ASC
LIMIT 10| source | target | distance |
|---|---|---|
"A" |
"F" |
160.0 |
"F" |
"A" |
160.0 |
"A" |
"E" |
120.0 |
"E" |
"A" |
120.0 |
"B" |
"F" |
110.0 |
"C" |
"F" |
110.0 |
"F" |
"B" |
110.0 |
"F" |
"C" |
110.0 |
"A" |
"D" |
90.0 |
"D" |
"A" |
90.0 |