Triangle Count
Glossary
- Directed
-
Directed trait. The algorithm is well-defined on a directed graph.
- Directed
-
Directed trait. The algorithm ignores the direction of the graph.
- Directed
-
Directed trait. The algorithm does not run on a directed graph.
- Undirected
-
Undirected trait. The algorithm is well-defined on an undirected graph.
- Undirected
-
Undirected trait. The algorithm ignores the undirectedness of the graph.
- Heterogeneous nodes
-
Heterogeneous nodes fully supported. The algorithm has the ability to distinguish between nodes of different types.
- Heterogeneous nodes
-
Heterogeneous nodes allowed. The algorithm treats all selected nodes similarly regardless of their label.
- Heterogeneous relationships
-
Heterogeneous relationships fully supported. The algorithm has the ability to distinguish between relationships of different types.
- Heterogeneous relationships
-
Heterogeneous relationships allowed. The algorithm treats all selected relationships similarly regardless of their type.
- Weighted relationships
-
Weighted trait. The algorithm supports a relationship property to be used as weight, specified via the relationshipWeightProperty configuration parameter.
- Weighted relationships
-
Weighted trait. The algorithm treats each relationship as equally important, discarding the value of any relationship weight.
- Node properties
-
Node properties trait. The algorithm makes use of node properties.
Introduction
The Triangle Count algorithm counts the number of triangles for each node in the graph. A triangle is a set of three nodes where each node has a relationship to the other two. In graph theory terminology, this is sometimes referred to as a 3-clique. The Triangle Count algorithm in the GDS library only finds triangles in undirected graphs.
Triangle counting has gained popularity in social network analysis, where it is used to detect communities and measure the cohesiveness of those communities. It can also be used to determine the stability of a graph, and is often used as part of the computation of network indices, such as clustering coefficients. The Triangle Count algorithm is also used to compute the Local Clustering Coefficient.
For more information on this algorithm, see:
-
Triangle count and clustering coefficient have been shown to be useful as features for classifying a given website as spam, or non-spam, content. This is described in "Efficient Semi-streaming Algorithms for Local Triangle Counting in Massive Graphs".
Node label filtering
For some use-cases it is useful to only count triangles that contain nodes with specific node labels. This is also something that can save computation time, as the algorithm will not have to consider nodes that do not have the specified labels.
The algorithm supports node label filtering by allowing you to specify a list of up to three node labels in the configuration. If three labels are specified, the algorithm will only count triangles that contain nodes with all three labels, and each label must be represented by at least one node in the triangle. If fewer than three labels are specified, the algorithm will count triangles where each specified label is represented by at least one node in the triangle, but nodes with no specified label can also be part of the triangle. If a label is repeated in the list, it will represented by as many nodes as times it appears in the list.
Syntax
This section covers the syntax used to execute the Triangle Count algorithm in each of its execution modes. We are describing the named graph variant of the syntax. To learn more about general syntax variants, see Syntax overview.
CALL gds.triangleCount.stream(
graphName: String,
configuration: Map
)
YIELD
nodeId: Integer,
triangleCount: Integer| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
List of String |
|
yes |
Filter the named graph using the given node labels. Nodes with any of the given labels will be included. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. Relationships with any of the given types will be included. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
maxDegree |
Integer |
|
yes |
If a node has a degree higher than this it will not be considered by the algorithm. The triangle count for these nodes will be |
labelFilter |
List of String |
|
yes |
A list of up to three node labels as strings. Only triangles with nodes having representatives for each specified label will be counted. If left empty (default), all triangles will be counted. |
1. In a GDS Session, the default is the number of available processors. |
||||
| Name | Type | Description |
|---|---|---|
nodeId |
Integer |
Node ID. |
triangleCount |
Integer |
Number of triangles the node is part of. Is |
CALL gds.triangleCount.stats(
graphName: String,
configuration: Map
)
YIELD
globalTriangleCount: Integer,
nodeCount: Integer,
preProcessingMillis: Integer,
computeMillis: Integer,
postProcessingMillis: Integer,
configuration: Map| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
List of String |
|
yes |
Filter the named graph using the given node labels. Nodes with any of the given labels will be included. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. Relationships with any of the given types will be included. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
maxDegree |
Integer |
|
yes |
If a node has a degree higher than this it will not be considered by the algorithm. The triangle count for these nodes will be |
labelFilter |
List of String |
|
yes |
A list of up to three node labels as strings. Only triangles with nodes having representatives for each specified label will be counted. If left empty (default), all triangles will be counted. |
2. In a GDS Session, the default is the number of available processors. |
||||
| Name | Type | Description |
|---|---|---|
globalTriangleCount |
Integer |
Total number of triangles in the graph. |
nodeCount |
Integer |
Number of nodes in the graph. |
preProcessingMillis |
Integer |
Milliseconds for preprocessing the graph. |
computeMillis |
Integer |
Milliseconds for running the algorithm. |
postProcessingMillis |
Integer |
Milliseconds for computing the global metrics. |
configuration |
Map |
The configuration used for running the algorithm. |
CALL gds.triangleCount.mutate(
graphName: String,
configuration: Map
)
YIELD
globalTriangleCount: Integer,
nodeCount: Integer,
nodePropertiesWritten: Integer,
preProcessingMillis: Integer,
computeMillis: Integer,
postProcessingMillis: Integer,
mutateMillis: Integer,
configuration: Map| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
mutateProperty |
String |
|
no |
The node property in the GDS graph to which the triangle count is written. |
List of String |
|
yes |
Filter the named graph using the given node labels. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
maxDegree |
Integer |
|
yes |
If a node has a degree higher than this it will not be considered by the algorithm. The triangle count for these nodes will be |
labelFilter |
List of String |
|
yes |
A list of up to three node labels as strings. Only triangles with nodes having representatives for each specified label will be counted. If left empty (default), all triangles will be counted. |
| Name | Type | Description |
|---|---|---|
globalTriangleCount |
Integer |
Total number of triangles in the graph. |
nodeCount |
Integer |
Number of nodes in the graph. |
nodePropertiesWritten |
Integer |
Number of properties added to the projected graph. |
preProcessingMillis |
Integer |
Milliseconds for preprocessing the graph. |
computeMillis |
Integer |
Milliseconds for running the algorithm. |
postProcessingMillis |
Integer |
Milliseconds for computing the global metrics. |
mutateMillis |
Integer |
Milliseconds for adding properties to the projected graph. |
configuration |
Map |
The configuration used for running the algorithm. |
CALL gds.triangleCount.write(
graphName: String,
configuration: Map
)
YIELD
globalTriangleCount: Integer,
nodeCount: Integer,
nodePropertiesWritten: Integer,
preProcessingMillis: Integer,
computeMillis: Integer,
postProcessingMillis: Integer,
writeMillis: Integer,
configuration: Map| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
List of String |
|
yes |
Filter the named graph using the given node labels. Nodes with any of the given labels will be included. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. Relationships with any of the given types will be included. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
Integer |
|
yes |
The number of concurrent threads used for writing the result to Neo4j. |
|
String |
|
no |
The node property in the Neo4j database to which the triangle count is written. |
|
maxDegree |
Integer |
|
yes |
If a node has a degree higher than this it will not be considered by the algorithm. The triangle count for these nodes will be |
labelFilter |
List of String |
|
yes |
A list of up to three node labels as strings. Only triangles with nodes having representatives for each specified label will be counted. If left empty (default), all triangles will be counted. |
3. In a GDS Session, the default is the number of available processors. |
||||
| Name | Type | Description |
|---|---|---|
globalTriangleCount |
Integer |
Total number of triangles in the graph. |
nodeCount |
Integer |
Number of nodes in the graph. |
nodePropertiesWritten |
Integer |
Number of properties written to Neo4j. |
preProcessingMillis |
Integer |
Milliseconds for preprocessing the graph. |
computeMillis |
Integer |
Milliseconds for running the algorithm. |
postProcessingMillis |
Integer |
Milliseconds for computing the global metrics. |
writeMillis |
Integer |
Milliseconds for writing results back to Neo4j. |
configuration |
Map |
The configuration used for running the algorithm. |
Triangles listing
In addition to the standard execution modes there is additionally the procedure gds.triangles that can be used to list all triangles in the graph.
CALL gds.triangles(
graphName: String,
configuration: Map
)
YIELD nodeA, nodeB, nodeC| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
graphName |
String |
|
no |
The name of a graph stored in the catalog. |
configuration |
Map |
|
yes |
Configuration for algorithm-specifics and/or graph filtering. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
List of String |
|
yes |
Filter the named graph using the given node labels. Nodes with any of the given labels will be included. |
|
List of String |
|
yes |
Filter the named graph using the given relationship types. Relationships with any of the given types will be included. |
|
Integer |
|
yes |
The number of concurrent threads used for running the algorithm. |
|
String |
|
yes |
An ID that can be provided to more easily track the algorithm’s progress. |
|
Boolean |
|
yes |
If disabled the progress percentage will not be logged. |
|
4. In a GDS Session, the default is the number of available processors. |
||||
| Name | Type | Description |
|---|---|---|
nodeA |
Integer |
The ID of the first node in the given triangle. |
nodeB |
Integer |
The ID of the second node in the given triangle. |
nodeC |
Integer |
The ID of the third node in the given triangle. |
Examples
|
All the examples below should be run in an empty database. The examples use Cypher projections as the norm. Native projections will be deprecated in a future release. |
In this section we will show examples of running the Triangle Count algorithm on a concrete graph. The intention is to illustrate what the results look like and to provide a guide in how to make use of the algorithm in a real setting. We will do this on a small social network graph of a handful nodes connected in a particular pattern. The example graph looks like this:
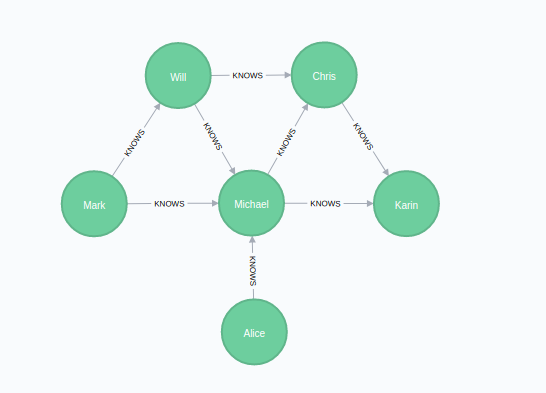
CREATE
(alice:Person {name: 'Alice'}),
(michael:Person {name: 'Michael'}),
(karin:Person {name: 'Karin'}),
(chris:Person {name: 'Chris'}),
(will:Person {name: 'Will'}),
(mark:Person {name: 'Mark'}),
(michael)-[:KNOWS]->(karin),
(michael)-[:KNOWS]->(chris),
(will)-[:KNOWS]->(michael),
(mark)-[:KNOWS]->(michael),
(mark)-[:KNOWS]->(will),
(alice)-[:KNOWS]->(michael),
(will)-[:KNOWS]->(chris),
(chris)-[:KNOWS]->(karin)With the graph in Neo4j we can now project it into the graph catalog to prepare it for algorithm execution.
We do this using a Cypher projection targeting the Person nodes and the KNOWS relationships.
For the relationships we must use the UNDIRECTED orientation.
This is because the Triangle Count algorithm is defined only for undirected graphs.
MATCH (source:Person)-[r:KNOWS]->(target:Person)
RETURN gds.graph.project(
'myGraph',
source,
target,
{},
{ undirectedRelationshipTypes: ['*'] }
)
The Triangle Count algorithm requires the graph to use the UNDIRECTED orientation for relationships.
You can either create the graph with undirected relationships or update it by converting the directed relationships into new undirected ones.
|
In the following examples we will demonstrate using the Triangle Count algorithm on this graph.
Memory Estimation
First off, we will estimate the cost of running the algorithm using the estimate procedure.
This can be done with any execution mode.
We will use the write mode in this example.
Estimating the algorithm is useful to understand the memory impact that running the algorithm on your graph will have.
When you later actually run the algorithm in one of the execution modes the system will perform an estimation.
If the estimation shows that there is a very high probability of the execution going over its memory limitations, the execution is prohibited.
To read more about this, see Automatic estimation and execution blocking.
For more details on estimate in general, see Memory Estimation.
CALL gds.triangleCount.write.estimate('myGraph', { writeProperty: 'triangleCount' })
YIELD nodeCount, relationshipCount, bytesMin, bytesMax, requiredMemory| nodeCount | relationshipCount | bytesMin | bytesMax | requiredMemory |
|---|---|---|---|---|
6 |
16 |
160 |
160 |
"160 Bytes" |
Note that the relationship count is 16, although we only projected 8 relationships in the original Cypher statement.
This is because we used the UNDIRECTED orientation, which will project each relationship in each direction, effectively doubling the number of relationships.
Stream
In the stream execution mode, the algorithm returns the triangle count for each node.
This allows us to inspect the results directly or post-process them in Cypher without any side effects.
For example, we can order the results to find the nodes with the highest triangle count.
For more details on the stream mode in general, see Stream.
stream mode:CALL gds.triangleCount.stream('myGraph')
YIELD nodeId, triangleCount
RETURN gds.util.asNode(nodeId).name AS name, triangleCount
ORDER BY triangleCount DESC, name ASC| name | triangleCount |
|---|---|
"Michael" |
3 |
"Chris" |
2 |
"Will" |
2 |
"Karin" |
1 |
"Mark" |
1 |
"Alice" |
0 |
Here we find that the 'Michael' node has the most triangles.
This can be verified in the example graph.
Since the 'Alice' node only KNOWS one other node, it can not be part of any triangle, and indeed the algorithm reports a count of zero.
Stats
In the stats execution mode, the algorithm returns a single row containing a summary of the algorithm result.
The summary result contains the global triangle count, which is the total number of triangles in the entire graph.
This execution mode does not have any side effects.
It can be useful for evaluating algorithm performance by inspecting the computeMillis return item.
In the examples below we will omit returning the timings.
The full signature of the procedure can be found in the syntax section.
For more details on the stats mode in general, see Stats.
stats mode:CALL gds.triangleCount.stats('myGraph')
YIELD globalTriangleCount, nodeCount| globalTriangleCount | nodeCount |
|---|---|
3 |
6 |
Here we can see that the graph has six nodes with a total number of three triangles. Comparing this to the stream example we can see that the 'Michael' node has a triangle count equal to the global triangle count. In other words, that node is part of all of the triangles in the graph and thus has a very central position in the graph.
Mutate
The mutate execution mode extends the stats mode with an important side effect: updating the named graph with a new node property containing the triangle count for that node.
The name of the new property is specified using the mandatory configuration parameter mutateProperty.
The result is a single summary row, similar to stats, but with some additional metrics.
The mutate mode is especially useful when multiple algorithms are used in conjunction.
For example, using the triangle count to compute the local clustering coefficient.
For more details on the mutate mode in general, see Mutate.
mutate mode:CALL gds.triangleCount.mutate('myGraph', {
mutateProperty: 'triangles'
})
YIELD globalTriangleCount, nodeCount| globalTriangleCount | nodeCount |
|---|---|
3 |
6 |
The returned result is the same as in the stats example.
Additionally, the graph 'myGraph' now has a node property triangles which stores the triangle count for each node.
To find out how to inspect the new schema of the in-memory graph, see Listing graphs.
Write
The write execution mode extends the stats mode with an important side effect: writing the triangle count for each node as a property to the Neo4j database.
The name of the new property is specified using the mandatory configuration parameter writeProperty.
The result is a single summary row, similar to stats, but with some additional metrics.
The write mode enables directly persisting the results to the database.
For more details on the write mode in general, see Write.
write mode:CALL gds.triangleCount.write('myGraph', {
writeProperty: 'triangles'
})
YIELD globalTriangleCount, nodeCount| globalTriangleCount | nodeCount |
|---|---|
3 |
6 |
The returned result is the same as in the stats example.
Additionally, each of the six nodes now has a new property triangles in the Neo4j database, containing the triangle count for that node.
Maximum Degree
The Triangle Count algorithm supports a maxDegree configuration parameter that can be used to exclude nodes from processing if their degree is greater than the configured value.
This can be useful to speed up the computation when there are nodes with a very high degree (so-called super nodes) in the graph.
Super nodes have a great impact on the performance of the Triangle Count algorithm.
To learn about the degree distribution of your graph, see Listing graphs.
The nodes excluded from the computation get assigned a triangle count of -1.
stream mode with the maxDegree parameter:CALL gds.triangleCount.stream('myGraph', {
maxDegree: 4
})
YIELD nodeId, triangleCount
RETURN gds.util.asNode(nodeId).name AS name, triangleCount
ORDER BY name ASC| name | triangleCount |
|---|---|
"Alice" |
0 |
"Chris" |
0 |
"Karin" |
0 |
"Mark" |
0 |
"Michael" |
-1 |
"Will" |
0 |
Running the algorithm on the example graph with maxDegree: 4 excludes the 'Michael' node from the computation, as it has a degree of 5.
As this node is part of all the triangles in the example graph excluding it results in no triangles.
Triangles listing
It is also possible to list all the triangles in the graph.
To do this we make use of the procedure gds.triangles.
CALL gds.triangles('myGraph')
YIELD nodeA, nodeB, nodeC
RETURN
gds.util.asNode(nodeA).name AS nodeA,
gds.util.asNode(nodeB).name AS nodeB,
gds.util.asNode(nodeC).name AS nodeC
ORDER BY nodeA, nodeB, nodeC ASC| nodeA | nodeB | nodeC |
|---|---|---|
"Michael" |
"Chris" |
"Karin" |
"Michael" |
"Mark" |
"Will" |
"Michael" |
"Will" |
"Chris" |
We can see that there are three triangles in the graph: "Will, Michael, and Chris", "Will, Mark, and Michael", and "Michael, Karin, and Chris". The node "Alice" is not part of any triangle and thus does not appear in the triangles listing.