Configuring the pipeline
This feature is in the alpha tier. For more information on feature tiers, see API Tiers.
This page explains how to create and configure a node regression pipeline.
Creating a pipeline
The first step of building a new pipeline is to create one using gds.alpha.pipeline.nodeRegression.create.
This stores a trainable pipeline object in the pipeline catalog of type Node regression training pipeline.
This represents a configurable pipeline that can later be invoked for training, which in turn creates a regression model.
The latter is a model which is stored in the catalog with type NodeRegression.
Syntax
CALL gds.alpha.pipeline.nodeRegression.create(
pipelineName: String
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: List of Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the created pipeline. |
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
CALL gds.alpha.pipeline.nodeRegression.create('pipe')| name | nodePropertySteps | featureProperties | splitConfig | autoTuningConfig | parameterSpace |
|---|---|---|---|---|---|
"pipe" |
[] |
[] |
{testFraction=0.3, validationFolds=3} |
{maxTrials=10} |
{LinearRegression=[], RandomForest=[]} |
This shows that the newly created pipeline does not contain any steps yet, and has defaults for the split and train parameters.
Adding node properties
A node regression pipeline can execute one or several GDS algorithms in mutate mode that create node properties in the in-memory graph. Such steps producing node properties can be chained one after another and created properties can later be used as features. Moreover, the node property steps that are added to the training pipeline will be executed both when training a model and when the regression pipeline is applied for regression.
The name of the procedure that should be added can be a fully qualified GDS procedure name ending with .mutate.
The ending .mutate may be omitted and one may also use shorthand forms such as node2vec instead of gds.node2vec.mutate.
But please note that a tier qualification must still be given as part of the name.
For example, pre-processing algorithms can be used as node property steps.
Syntax
CALL gds.alpha.pipeline.nodeRegression.addNodeProperty(
pipelineName: String,
procedureName: String,
procedureConfiguration: Map
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: List of Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the pipeline. |
procedureName |
String |
The name of the procedure to be added to the pipeline. |
procedureConfiguration |
Map |
The map used to generate the configuration for the node property procedure. It supports all procedure-specific configuration, excluding the parameters |
| Name | Type | Default | Description |
|---|---|---|---|
contextNodeLabels |
List of String |
|
Additional node labels which are added as context. |
contextRelationshipTypes |
List of String |
|
Additional relationship types which are added as context. |
During training, the context configuration is combined with the train configuration to produce the final node label and relationship type filter for each node property step.
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
sizePerStory.CALL gds.alpha.pipeline.nodeRegression.addNodeProperty('pipe', 'scaleProperties', {
nodeProperties: 'sizePerStory',
scaler: 'MinMax',
mutateProperty:'scaledSizes'
}) YIELD name, nodePropertySteps| name | nodePropertySteps |
|---|---|
"pipe" |
[{config={contextNodeLabels=[], contextRelationshipTypes=[], mutateProperty="scaledSizes", nodeProperties="sizePerStory", scaler="MinMax"}, name="gds.scaleProperties.mutate"}] |
The scaledSizes property can be later used as a feature.
Adding features
A Node Regression Pipeline allows you to select a subset of the available node properties to be used as features for the machine learning model.
When executing the pipeline, the selected nodeProperties must be either present in the input graph, or created by a previous node property step.
Syntax
CALL gds.alpha.pipeline.nodeRegression.selectFeatures(
pipelineName: String,
featureProperties: List or String
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: List of Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the pipeline. |
featureProperties |
List or String |
Node properties to use as model features. |
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
CALL gds.alpha.pipeline.nodeRegression.selectFeatures('pipe', ['scaledSizes', 'sizePerStory'])
YIELD name, featureProperties| name | featureProperties |
|---|---|
"pipe" |
["scaledSizes", "sizePerStory"] |
Here we assume that the input graph contains a property sizePerStory and scaledSizes was created in a nodePropertyStep.
Configuring the node splits
Node Regression Pipelines manage the splitting of nodes into several sets, which are used for training, testing and validating the model candidates defined in the parameter space.
Configuring the splitting is optional, and if omitted, splitting will be done using default settings.
The splitting configuration of a pipeline can be inspected by using gds.model.list and yielding splitConfig.
The node splits are used in the training process as follows:
-
The input graph is split into two parts: the train graph and the test graph. See the example below.
-
The train graph is further divided into a number of validation folds, each consisting of a train part and a validation part. See the animation below.
-
Each model candidate is trained on each train part and evaluated on the respective validation part.
-
The model with the highest average score according to the primary metric will win the training.
-
The winning model will then be retrained on the entire train graph.
-
The winning model is evaluated on the train graph as well as the test graph.
-
The winning model is retrained on the entire original graph.
Below we illustrate an example for a graph with 12 nodes.
First we use a holdoutFraction of 0.25 to split into train and test subgraphs.

Then we carry out three validation folds, where we first split the train subgraph into 3 disjoint subsets (s1, s2 and s3), and then alternate which subset is used for validation. For each fold, all candidate models are trained using the red nodes, and validated using the green nodes.
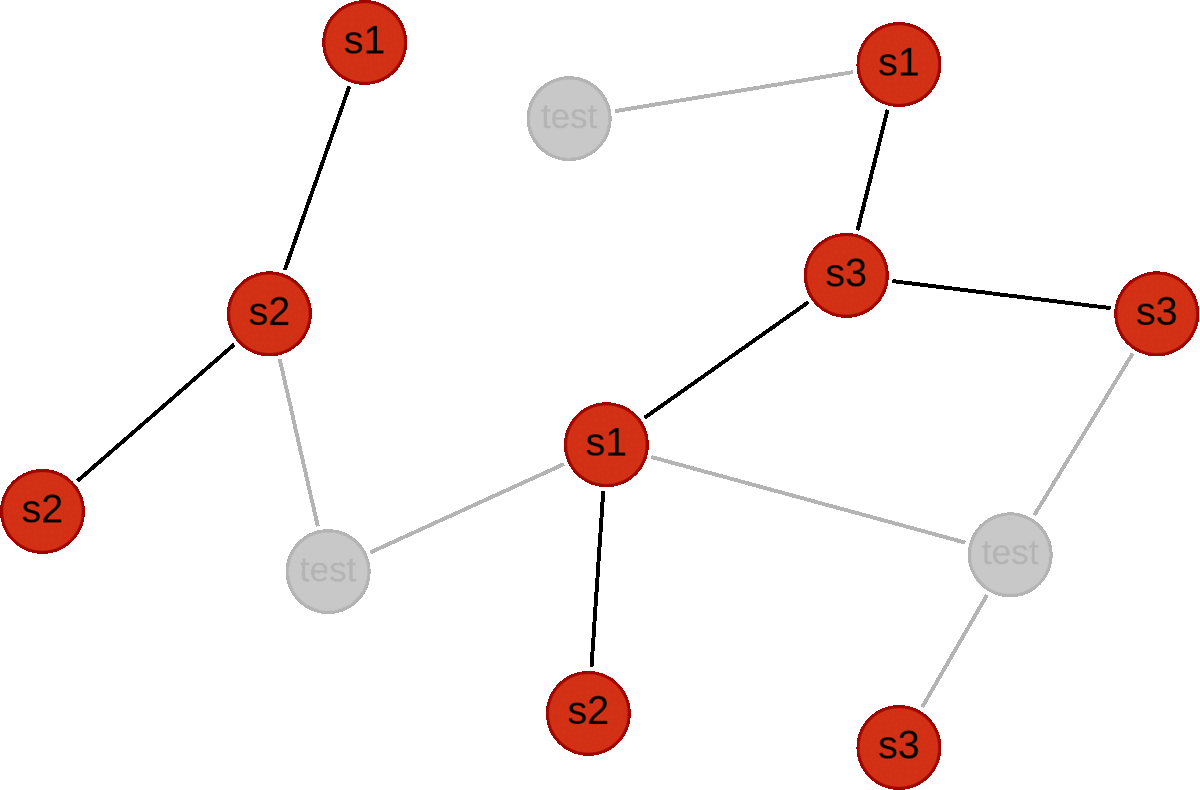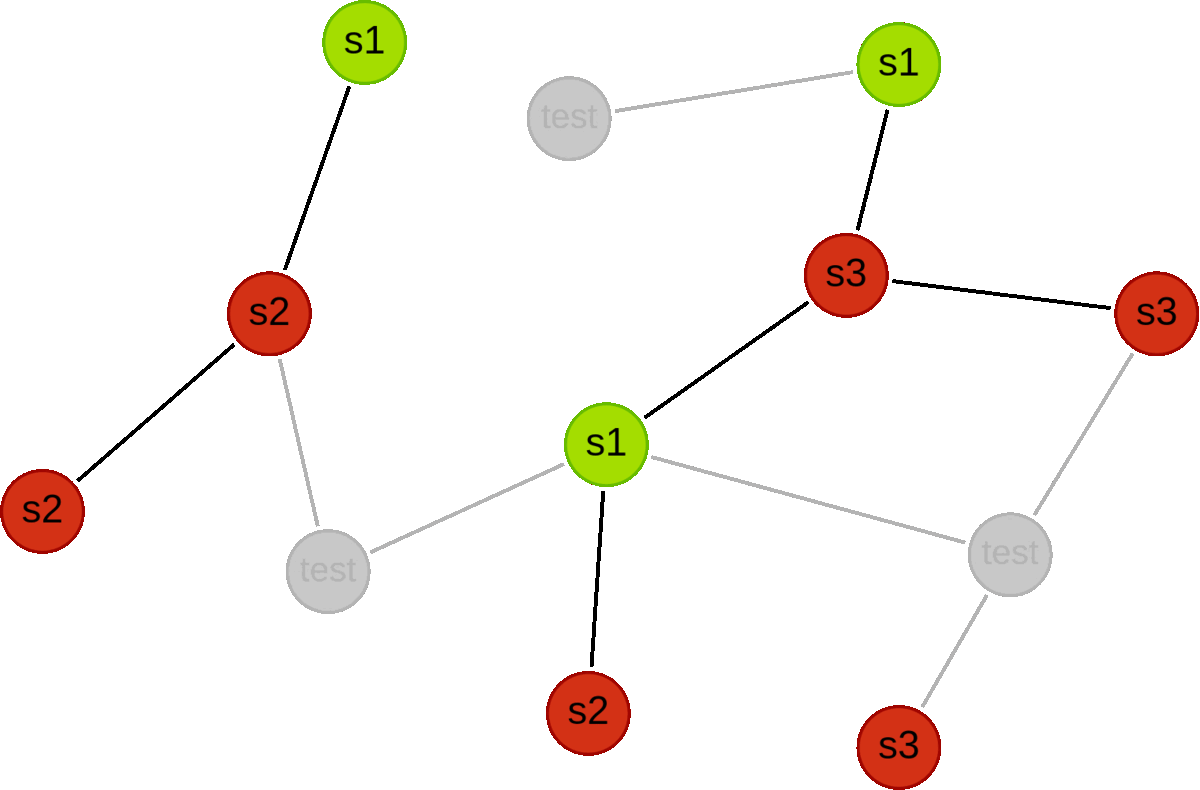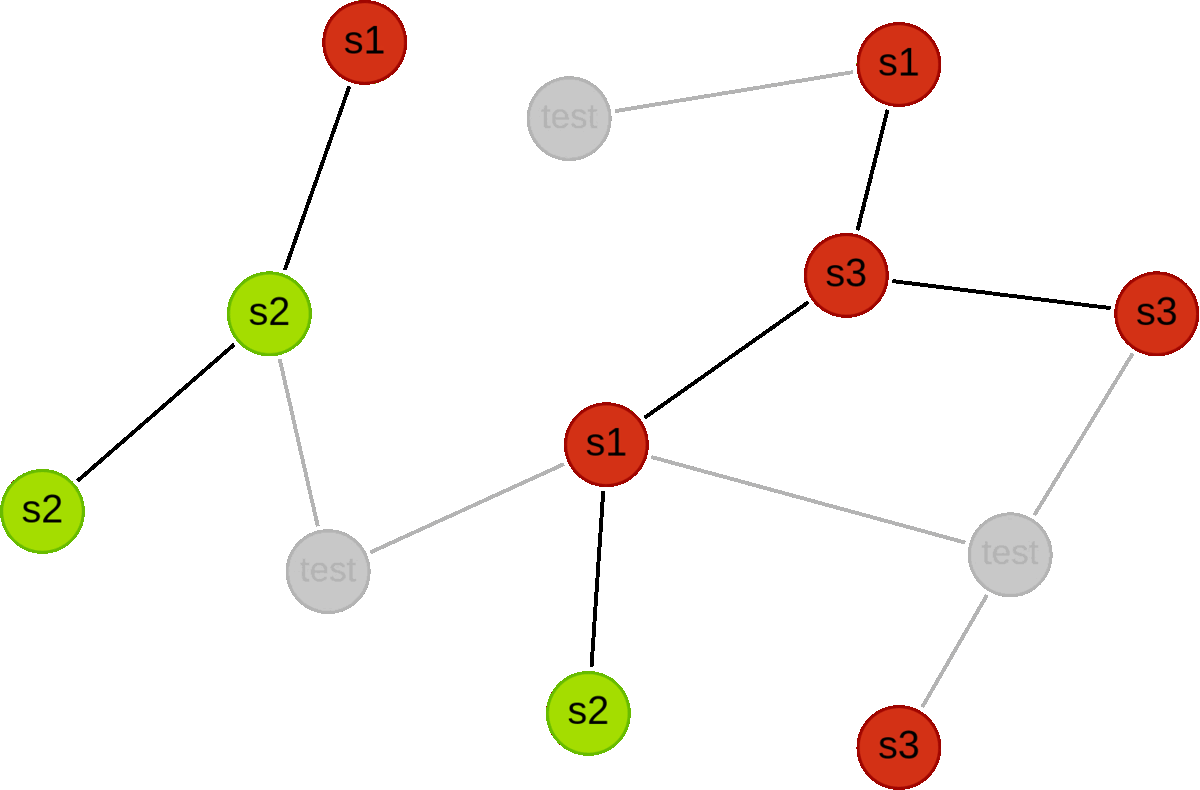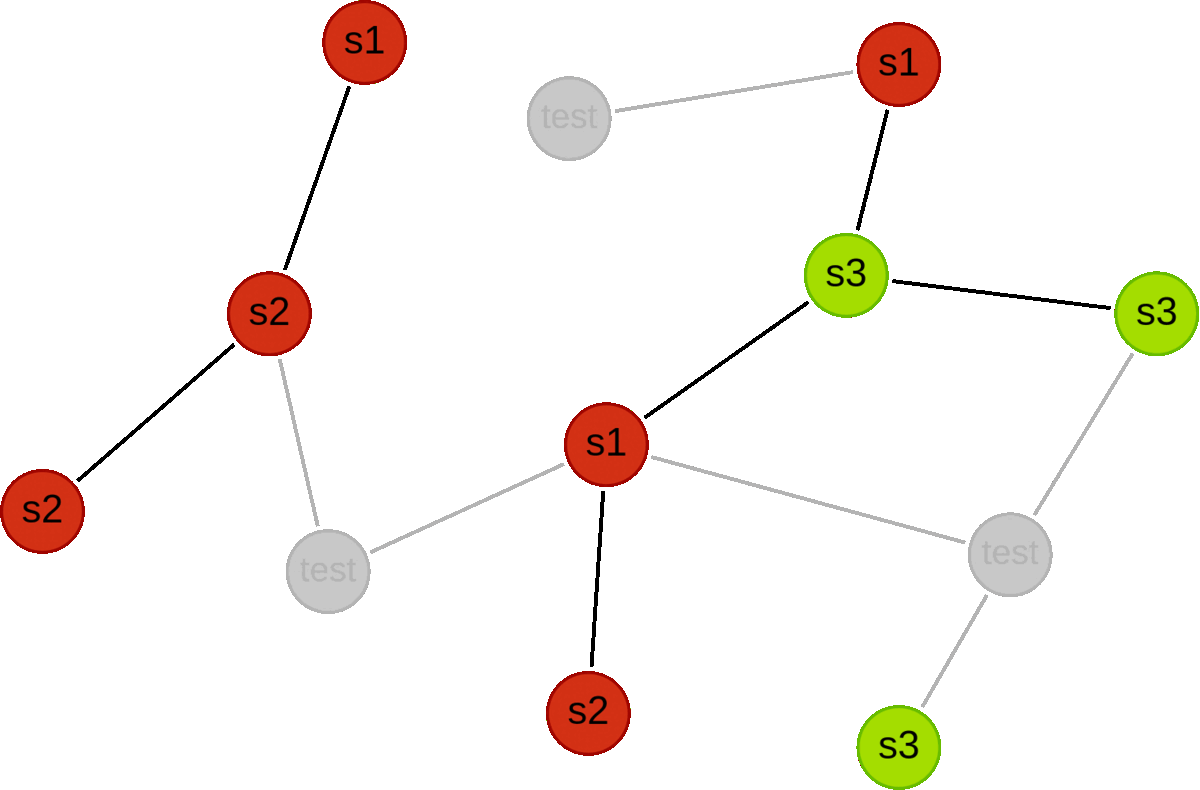
Syntax
CALL gds.alpha.pipeline.nodeRegression.configureSplit(
pipelineName: String,
configuration: Map
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: List of Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the pipeline. |
configuration |
Map |
Configuration for splitting the graph. |
| Name | Type | Default | Description |
|---|---|---|---|
validationFolds |
Integer |
3 |
Number of divisions of the training graph used during model selection. |
testFraction |
Double |
0.3 |
Fraction of the graph reserved for testing. Must be in the range (0, 1). The fraction used for the training is |
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
CALL gds.alpha.pipeline.nodeRegression.configureSplit('pipe', {
testFraction: 0.2,
validationFolds: 5
}) YIELD splitConfig| splitConfig |
|---|
{testFraction=0.2, validationFolds=5} |
We now reconfigured the splitting of the graph for the pipeline, which will be used during training.
Adding model candidates
A pipeline contains a collection of configurations for model candidates which is initially empty. This collection is called the parameter space. Each model candidate configuration contains either fixed values or ranges for training parameters. When a range is present, values from the range are determined automatically by an auto-tuning algorithm, see Auto-tuning. One or more model configurations must be added to the parameter space of the training pipeline, using one of the following procedures:
-
gds.alpha.pipeline.nodeRegression.addLinearRegression -
gds.alpha.pipeline.nodeRegression.addRandomForest
For detailed information about the available training methods in GDS, see Training methods.
In Training the pipeline, we explain further how the configured model candidates are trained, evaluated and compared.
The parameter space of a pipeline can be inspected using gds.model.list and yielding parameterSpace.
|
At least one model candidate must be added to the pipeline before it can be trained. |
Syntax
CALL gds.alpha.pipeline.nodeRegression.addLinearRegression(
pipelineName: String,
configuration: Map
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the pipeline. |
configuration |
Map |
The linear regression configuration for a candidate model. Supported parameters for model candidates are defined in the next table. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
batchSize |
Integer or Map [1] |
|
yes |
Number of nodes per batch. |
minEpochs |
Integer or Map [1] |
|
yes |
Minimum number of training epochs. |
maxEpochs |
Integer or Map [1] |
|
yes |
Maximum number of training epochs. |
learningRate [2] |
Float or Map [1] |
|
yes |
The learning rate determines the step size at each epoch while moving in the direction dictated by the Adam optimizer for minimizing the loss. |
patience |
Integer or Map [1] |
|
yes |
Maximum number of unproductive consecutive epochs. |
tolerance [2] |
Float or Map [1] |
|
yes |
The minimal improvement of the loss to be considered productive. |
penalty [2] |
Float or Map [1] |
|
yes |
Penalty used for the logistic regression. By default, no penalty is applied. |
1. A map should be of the form 2. Ranges for this parameter are auto-tuned on a logarithmic scale. |
||||
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
CALL gds.alpha.pipeline.nodeRegression.addRandomForest(
pipelineName: String,
configuration: Map
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the pipeline. |
configuration |
Map |
The random forest configuration for a candidate model. Supported parameters for model candidates are defined in the next table. |
| Name | Type | Default | Optional | Description |
|---|---|---|---|---|
maxFeaturesRatio |
Float or Map [3] |
|
yes |
The ratio of features to consider when looking for the best split |
numberOfSamplesRatio |
Float or Map [3] |
|
yes |
The ratio of samples to consider per decision tree. We use sampling with replacement. A value of |
numberOfDecisionTrees |
Integer or Map [3] |
|
yes |
The number of decision trees. |
maxDepth |
Integer or Map [3] |
|
yes |
The maximum depth of a decision tree. |
minLeafSize |
Integer or Map [3] |
|
yes |
The minimum number of samples for a leaf node in a decision tree. Must be strictly smaller than |
minSplitSize |
Integer or Map [3] |
|
yes |
The minimum number of samples required to split an internal node in a decision tree. Must be strictly larger than |
3. A map should be of the form |
||||
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
We can add multiple model candidates to our pipeline.
CALL gds.alpha.pipeline.nodeRegression.addLinearRegression('pipe')
YIELD parameterSpaceCALL gds.alpha.pipeline.nodeRegression.addRandomForest('pipe', {numberOfDecisionTrees: 5})
YIELD parameterSpaceCALL gds.alpha.pipeline.nodeRegression.addLinearRegression('pipe', {maxEpochs: 500, penalty: {range: [1e-4, 1e2]}})
YIELD parameterSpace
RETURN parameterSpace.RandomForest AS randomForestSpace, parameterSpace.LinearRegression AS linearRegressionSpace| randomForestSpace | linearRegressionSpace |
|---|---|
[{maxDepth=2147483647, methodName="RandomForest", minLeafSize=1, minSplitSize=2, numberOfDecisionTrees=5, numberOfSamplesRatio=1.0}] |
[{batchSize=100, learningRate=0.001, maxEpochs=100, methodName="LinearRegression", minEpochs=1, patience=1, penalty=0.0, tolerance=0.001}, {batchSize=100, learningRate=0.001, maxEpochs=500, methodName="LinearRegression", minEpochs=1, patience=1, penalty={range=[0.0001, 100.0]}, tolerance=0.001}] |
The parameterSpace in the pipeline now contains the three different model candidates, expanded with the default values.
Each specified model candidate will be tried out during the model selection in training.
|
These are somewhat naive examples of how to add and configure model candidates. Please see Training methods for more information on how to tune the configuration parameters of each method. |
Configuring Auto-tuning
In order to find good models, the pipeline supports automatically tuning the parameters of the training algorithm. Optionally, the procedure described below can be used to configure the auto-tuning behavior. Otherwise, default auto-tuning configuration is used. Currently, it is only possible to configure the maximum number of trials of hyper-parameter settings which are evaluated.
Syntax
CALL gds.alpha.pipeline.nodeRegression.configureAutoTuning(
pipelineName: String,
configuration: Map
) YIELD
name: String,
nodePropertySteps: List of Map,
featureProperties: List of String,
splitConfig: Map,
autoTuningConfig: Map,
parameterSpace: List of Map| Name | Type | Description |
|---|---|---|
pipelineName |
String |
The name of the created pipeline. |
configuration |
Map |
The configuration for auto-tuning. |
| Name | Type | Default | Description |
|---|---|---|---|
maxTrials |
Integer |
10 |
The value of |
| Name | Type | Description |
|---|---|---|
name |
String |
Name of the pipeline. |
nodePropertySteps |
List of Map |
List of configurations for node property steps. |
featureProperties |
List of String |
List of node properties to be used as features. |
splitConfig |
Map |
Configuration to define the split before the model training. |
autoTuningConfig |
Map |
Configuration to define the behavior of auto-tuning. |
parameterSpace |
List of Map |
List of parameter configurations for models which the train mode uses for model selection. |
Example
CALL gds.alpha.pipeline.nodeRegression.configureAutoTuning('pipe', {
maxTrials: 100
}) YIELD autoTuningConfig| autoTuningConfig |
|---|
{maxTrials=100} |
We explicitly configured the auto-tuning to try out at most 100 model candidates during training.